
谁是Adam?NeurIPS 2025审稿爆年度最大笑话!Hinton也曾被拒稿
谁是Adam?NeurIPS 2025审稿爆年度最大笑话!Hinton也曾被拒稿LLM真是把审稿人害惨了!NeurIPS 2025评审结果公,全网都被「谁是Adam」爆梗淹没。更离谱的是,有人的审稿建议中,残留了AI提示的痕迹。
来自主题: AI资讯
11103 点击 2025-07-28 16:17
 搜索
搜索
LLM真是把审稿人害惨了!NeurIPS 2025评审结果公,全网都被「谁是Adam」爆梗淹没。更离谱的是,有人的审稿建议中,残留了AI提示的痕迹。
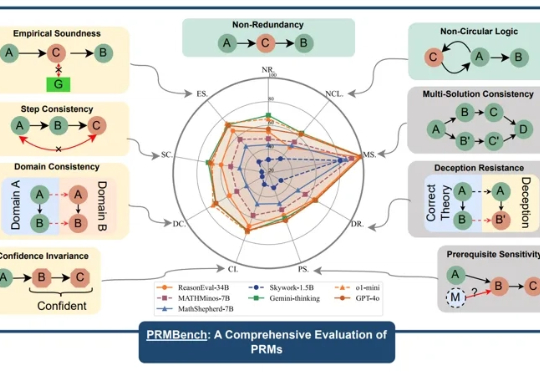
近年来,大型语言模型(LLMs)在复杂推理任务中展现出惊人的能力,这在很大程度上得益于过程级奖励模型(PRMs)的赋能。PRMs 作为 LLMs 进行多步推理和决策的关键「幕后功臣」,负责评估推理过程的每一步,以引导模型的学习方向。
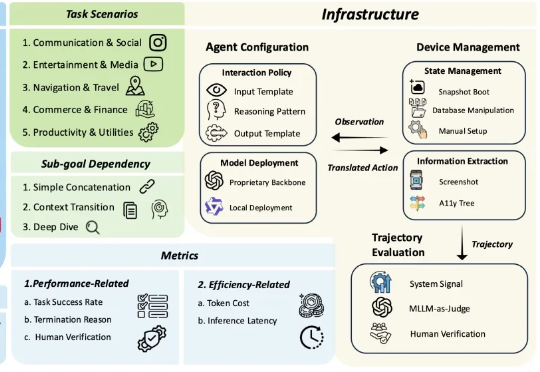
多模态大模型 (MLLM) 驱动的 OS 智能体在单屏动作落实(如 ScreenSpot)、短链操作任务(如 AndroidControl)上展现出突出的表现,标志着端侧任务自动化的初步成熟。

当前最强大的大语言模型(LLM)虽然代码能力飞速发展,但在解决真实、复杂的机器学习工程(MLE)任务时,仍像是在进行一场“闭卷考试”。它们可以在单次尝试中生成代码,却无法模拟人类工程师那样,在反复的实验、调试、反馈和优化中寻找最优解的真实工作流。

如何理解大模型推理能力?现在有来自谷歌DeepMind推理负责人Denny Zhou的分享了。 就是那位和清华姚班马腾宇等人证明了只要思维链足够长,Transformer就能解决任何问题的Google Brain推理团队创建者。 Denny Zhou围绕大模型推理过程和方法,在斯坦福大学CS25上讲了一堂“LLM推理”课。

复合LLM应用 (compound LLM applications) 是一种结合大语言模型(LLM)与外部工具、API、或其他LLM的高效多阶段工作流应用。

近年来,语言模型的显著进展主要得益于大规模文本数据的可获得性以及自回归训练方法的有效性。
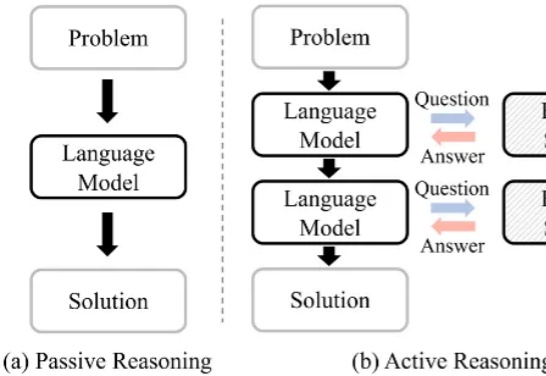
大语言模型(Large Language Model, LLM)在复杂推理任务中表现卓越。借助链式思维(Chain-of-Thought, CoT),LLM 能够将复杂问题分解为简单步骤,充分探索解题思路并得出正确答案。LLM 已在多个基准上展现出优异的推理能力,尤其是数学推理和代码生成。
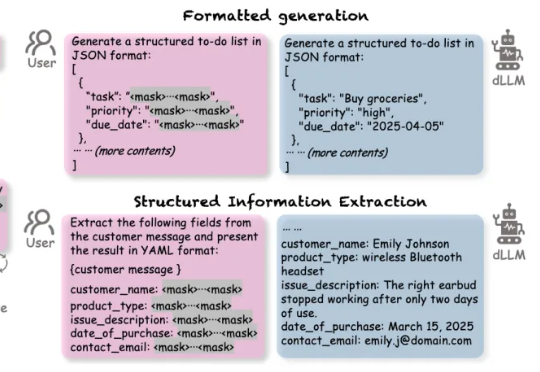
扩散语言模型(Diffusion-based LLMs,简称 dLLMs)以其并行解码、双向上下文建模、灵活插入masked token进行解码的特性,成为一个重要的发展方向。
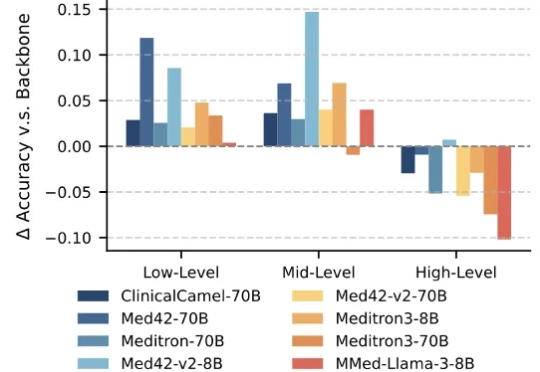
大语言模型(Large Language Models,LLMs)技术的迅猛发展,正在深刻重塑医疗行业。医疗领域正成为这一前沿技术的 “新战场” 之一。大模型具备强大的文本理解与生成能力,能够快速读取医学文献、解读病历记录,甚至基于患者表述生成初步诊断建议,有效辅助医生提升诊断的准确性与效率。