
Transformer终结者!谷歌DeepMind全新MoR架构问世,新一代魔王来了
Transformer终结者!谷歌DeepMind全新MoR架构问世,新一代魔王来了Transformer杀手来了?KAIST、谷歌DeepMind等机构刚刚发布的MoR架构,推理速度翻倍、内存减半,直接重塑了LLM的性能边界,全面碾压了传统的Transformer。网友们直呼炸裂:又一个改变游戏规则的炸弹来了。
来自主题: AI技术研报
9922 点击 2025-07-17 17:00
 搜索
搜索
Transformer杀手来了?KAIST、谷歌DeepMind等机构刚刚发布的MoR架构,推理速度翻倍、内存减半,直接重塑了LLM的性能边界,全面碾压了传统的Transformer。网友们直呼炸裂:又一个改变游戏规则的炸弹来了。

今天,我们正式发布MiniMax Agent全栈开发功能。这可能是全球首个 在复杂全栈网站应用上高交付率 的Agent。它支持Supabase后端托管、Stripe支付功能、cron job定时任务、长链接维持等能力,可开发需要API、实时数据、下单支付、LLM调用、定时任务、登录注册等功能的各类应用。
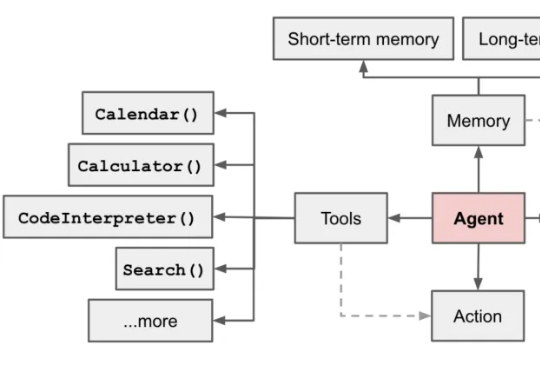
超长上下文窗口的大模型也会经常「失忆」,「记忆」也是需要管理的。

LLM正以前所未有的速度进化:METR发现,它们的智能每7个月就翻一番。到了2030年,一个模型可能只需几小时,就能搞定人类工程师几个月的工作。别眨眼,你的岗位或许已在倒计时中。
Zeju Qiu和Tim Z. Xiao是德国马普所博士生,Simon Buchholz和Maximilian Dax担任德国马普所博士后研究员
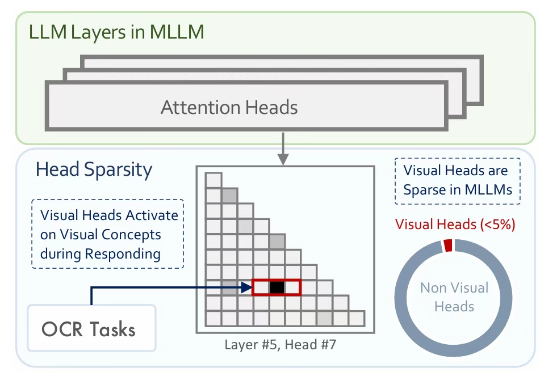
多模态大模型通常是在大型预训练语言模型(LLM)的基础上扩展而来。尽管原始的 LLM 并不具备视觉理解能力,但经过多模态训练后,这些模型却能在各类视觉相关任务中展现出强大的表现。
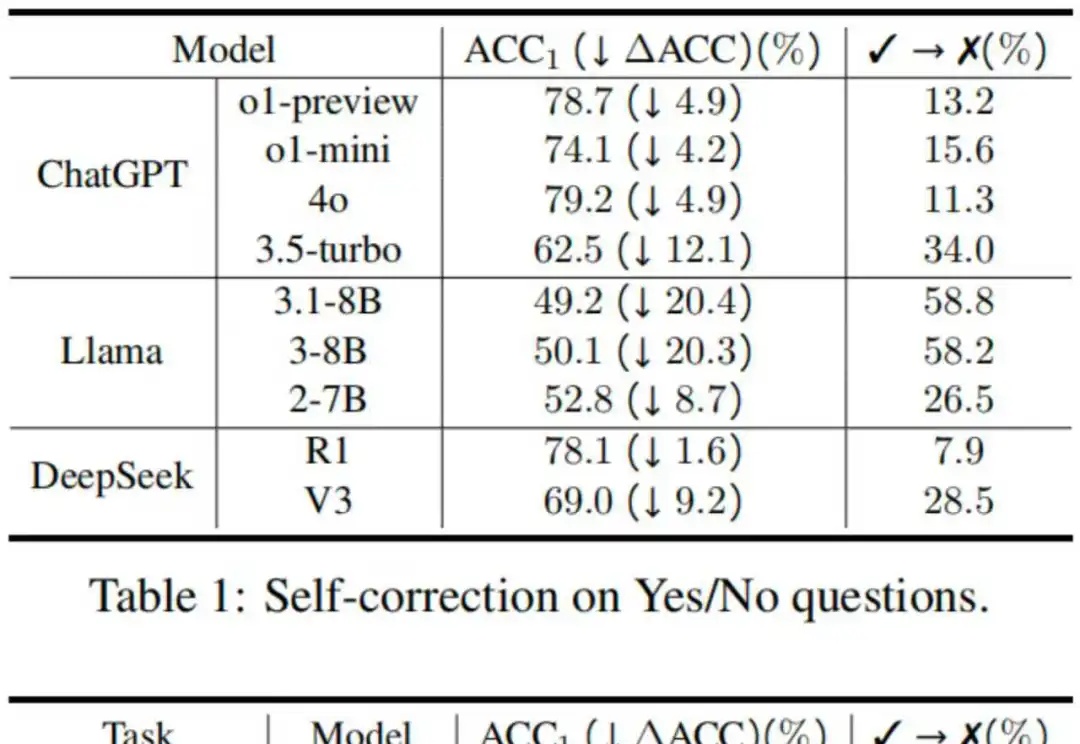
反思技术因其简单性和有效性受到了广泛的研究和应用,具体表现为在大语言模型遇到障碍或困难时,提示其“再想一下”,可以显著提升性能 [1]。然而,2024 年谷歌 DeepMind 的研究人员在一项研究中指出,大模型其实分不清对与错,如果不是仅仅提示模型反思那些它回答错误的问题,这样的提示策略反而可能让模型更倾向于把回答正确的答案改错 [2]。

近年来,多模态大模型(MLLMs)发展迅猛,从看图说话到视频理解,似乎无所不能。
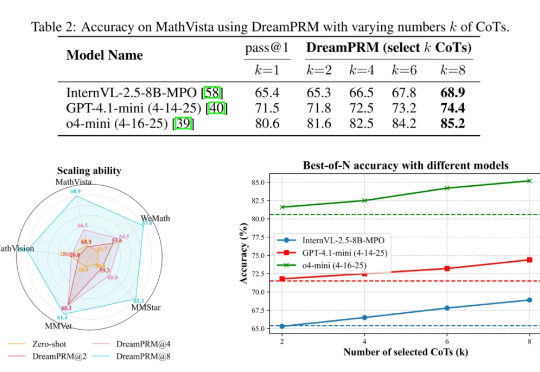
使用过程奖励模型(PRM)强化大语言模型的推理能力已在纯文本任务中取得显著成果,但将过程奖励模型扩展至多模态大语言模型(MLLMs)时,面临两大难题:
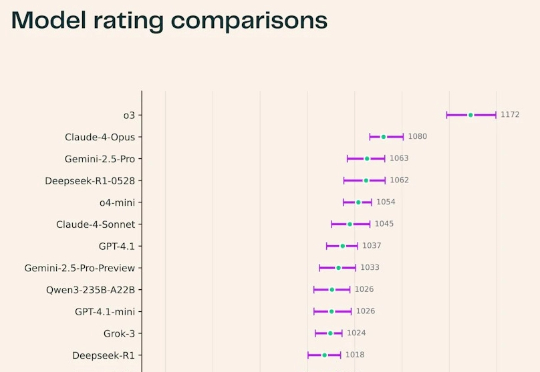
最近,Ai2耶鲁NYU联合推出了一个科研版「Chatbot Arena」——SciArena。全球23款顶尖大模型火拼真实科研任务,OpenAI o3领跑全场,DeepSeek紧追Gemini挤入前四!不过从结果来看,要猜中科研人的偏好,自动评估系统远未及格。