OpenAI没说的秘密,Meta全揭了?华人一作GPT-4o同款技术,爆打扩散王者
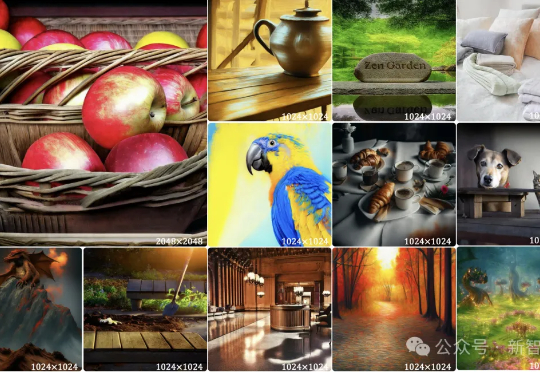
OpenAI没说的秘密,Meta全揭了?华人一作GPT-4o同款技术,爆打扩散王者自回归模型,首次生成2048×2048分辨率图像!来自Meta、西北大学、新加坡国立大学等机构的研究人员,专门为多模态大语言模型(MLLMs)设计的TokenShuffle,显著减少了计算中的视觉Token数量,提升效率并支持高分辨率图像合成。
来自主题: AI技术研报
10157 点击 2025-04-28 09:16