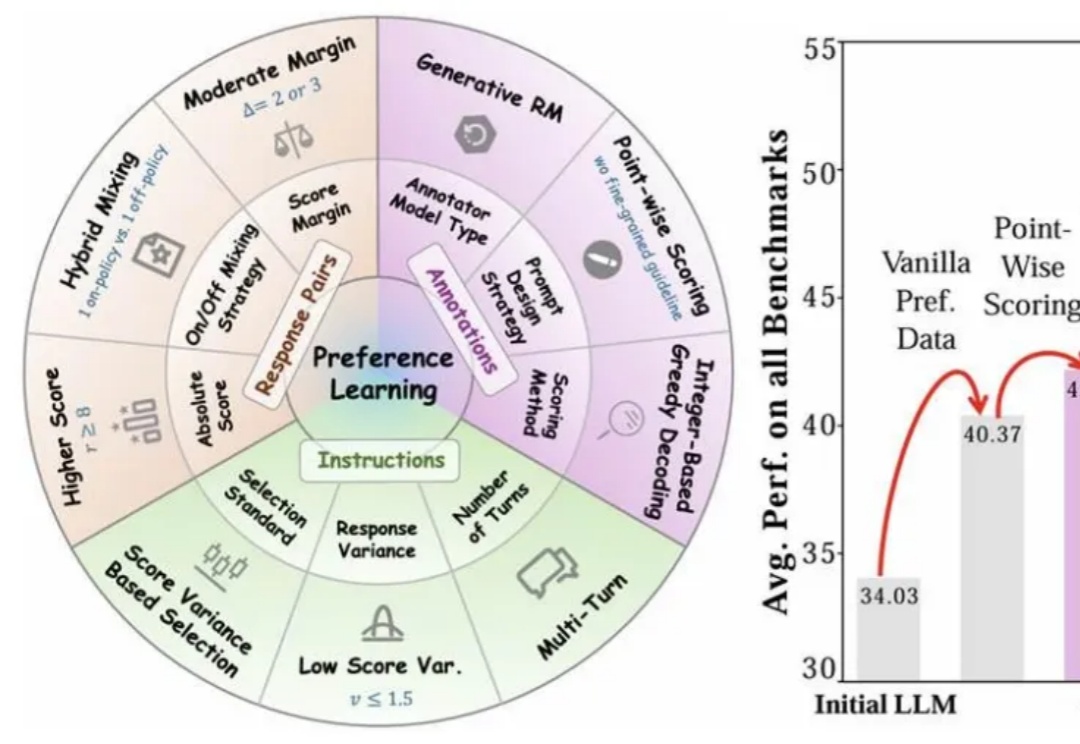
什么样的偏好,才叫好的偏好?——揭秘偏好对齐数据的「三驾马车」
什么样的偏好,才叫好的偏好?——揭秘偏好对齐数据的「三驾马车」近年来,大语言模型(LLMs)的对齐研究成为人工智能领域的核心挑战之一,而偏好数据集的质量直接决定了对齐的效果。无论是通过人类反馈的强化学习(RLHF),还是基于「RL-Free」的各类直接偏好优化方法(例如 DPO),都离不开高质量偏好数据集的构建。
来自主题: AI技术研报
9410 点击 2025-04-15 14:29
 搜索
搜索
近年来,大语言模型(LLMs)的对齐研究成为人工智能领域的核心挑战之一,而偏好数据集的质量直接决定了对齐的效果。无论是通过人类反馈的强化学习(RLHF),还是基于「RL-Free」的各类直接偏好优化方法(例如 DPO),都离不开高质量偏好数据集的构建。
近年来,随着大型语言模型(LLMs)的快速发展,多模态理解领域取得了前所未有的进步。像 OpenAI、InternVL 和 Qwen-VL 系列这样的最先进的视觉-语言模型(VLMs),在处理复杂的视觉-文本任务时展现了卓越的能力。

统一多模态大模型(U-MLLMs)逐渐成为研究热点,近期GPT-4o,Gemini-2.0-flash都展现出了非凡的理解和生成能力,而且还能实现跨模态输入输出,比如图像+文本输入,生成图像或文本。
视觉Token可以与LLMs词表无缝对齐了!
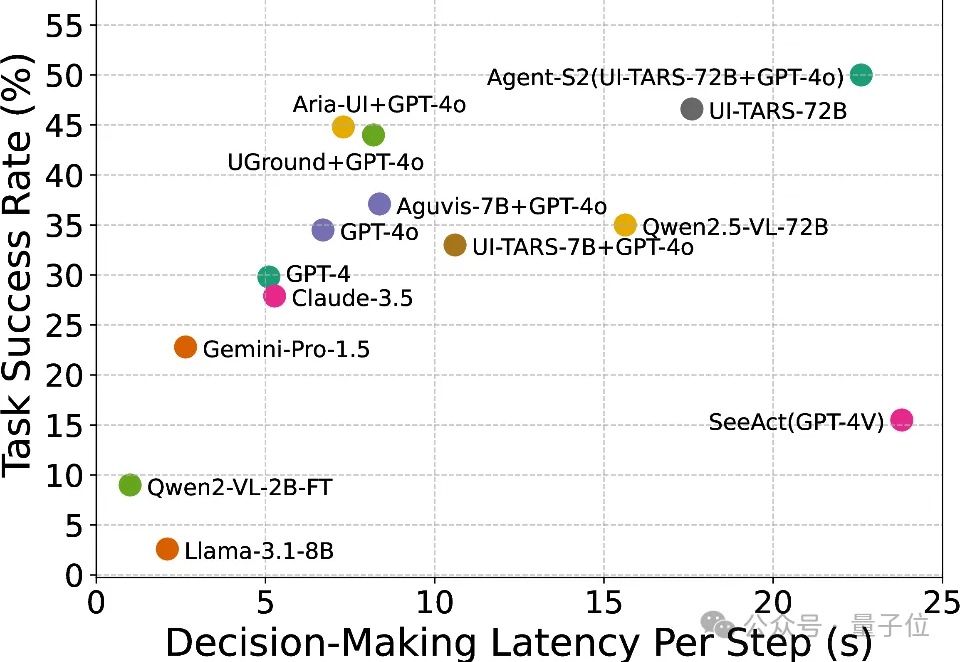
随着人工智能和大语言模型(LLMs)的不断突破,如何将其优势赋能于现实世界中可实际部署的高效工具,成为了业界关注的焦点。
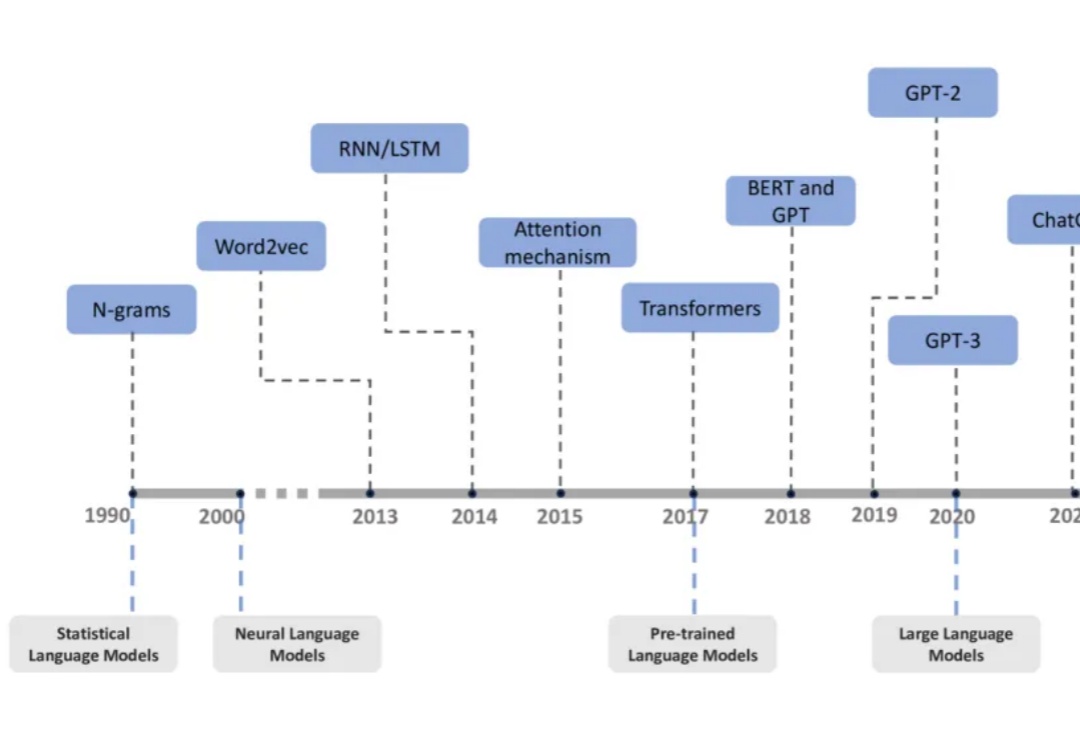
过去十年,自然语言处理领域经历了从统计语言模型到大型语言模型(LLMs)的飞速发展。
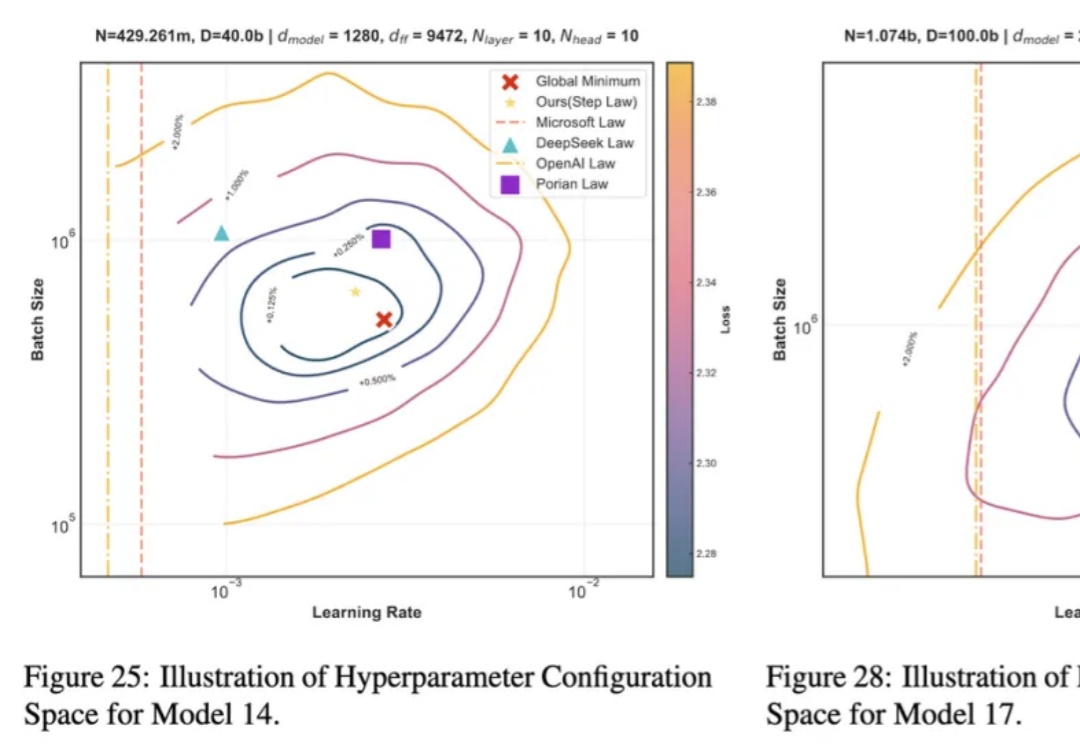
近年来,大语言模型 LLMs 在多种任务上的卓越表现已得到广泛认可。然而,要实现其高效部署,精细的超参数优化至关重要。为了探究最佳超参数的规律,我们开展了大规模的实证研究,通过在不同配置上进行网格搜索,我们揭示了一套通用的最优超参数缩放定律(Optimal Hyperparameter Scaling Law)。
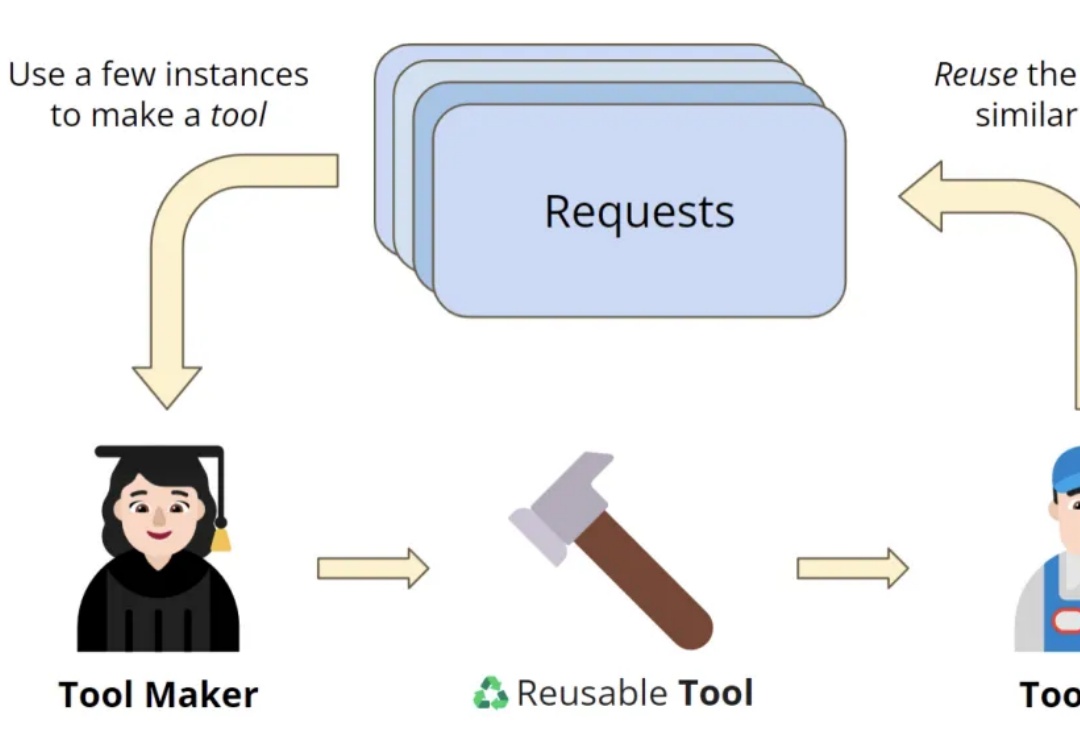
OctoTools通过标准化工具卡和规划器,帮助LLMs高效完成复杂任务,无需额外训练。在16个任务中表现优异,比其他方法平均准确率高出9.3%,尤其在多步推理和工具使用方面优势明显。
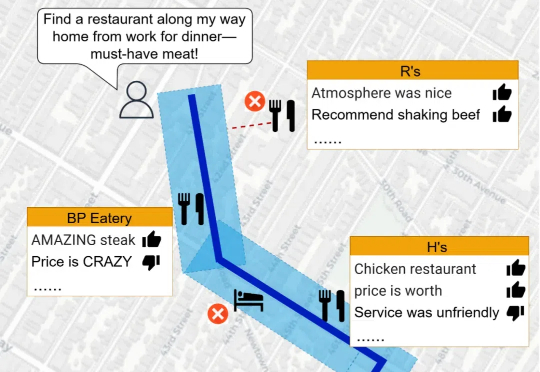
当涉及到空间推理任务时,LLMs 的表现却显得力不从心。空间推理不仅要求模型理解复杂的空间关系,还需要结合地理数据和语义信息,生成准确的回答。为了突破这一瓶颈,研究人员推出了 Spatial Retrieval-Augmented Generation (Spatial-RAG)—— 一个革命性的框架,旨在增强 LLMs 在空间推理任务中的能力。
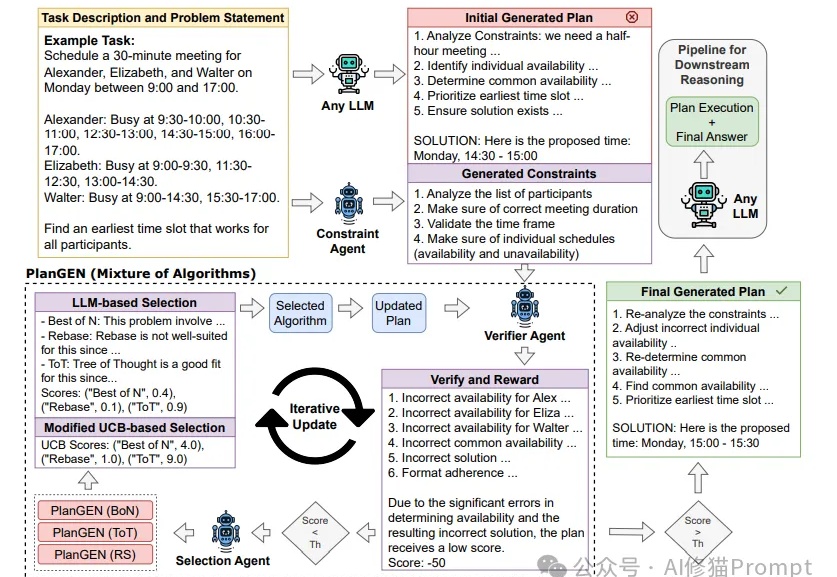
Agent这两天随着邀请码进入公众视野,展示了不凡的推理能力。然而,当面对需要精确规划和深度推理的复杂问题时,即使是最先进的LLMs也常常力不从心。Google研究团队提出的PlanGEN框架,正是为解决这一挑战而生。