
一个有意思的Prompt演员框架,LLMs被当成演员;提示被当成剧本;LLM输出被当成表演,o1从76%提高到87%
一个有意思的Prompt演员框架,LLMs被当成演员;提示被当成剧本;LLM输出被当成表演,o1从76%提高到87%如何更好地设计提示词(Prompt)一直是大家关注的焦点。最近,一个独特的研究视角引起了广泛关注:将LLMs视为“演员”,将提示词视为“剧本”,将模型输出视为“表演”。
来自主题: AI技术研报
4362 点击 2024-11-13 14:19
 搜索
搜索
如何更好地设计提示词(Prompt)一直是大家关注的焦点。最近,一个独特的研究视角引起了广泛关注:将LLMs视为“演员”,将提示词视为“剧本”,将模型输出视为“表演”。

研究人员通过案例研究,利用大型语言模型(LLMs)如GPT-4、Claude 3和Llama 3.1,探索了思维链(CoT)提示在解码移位密码任务中的表现;CoT提示虽然提升了模型的推理能力,但这种能力并非纯粹的符号推理,而是结合了记忆和概率推理的复杂过程。
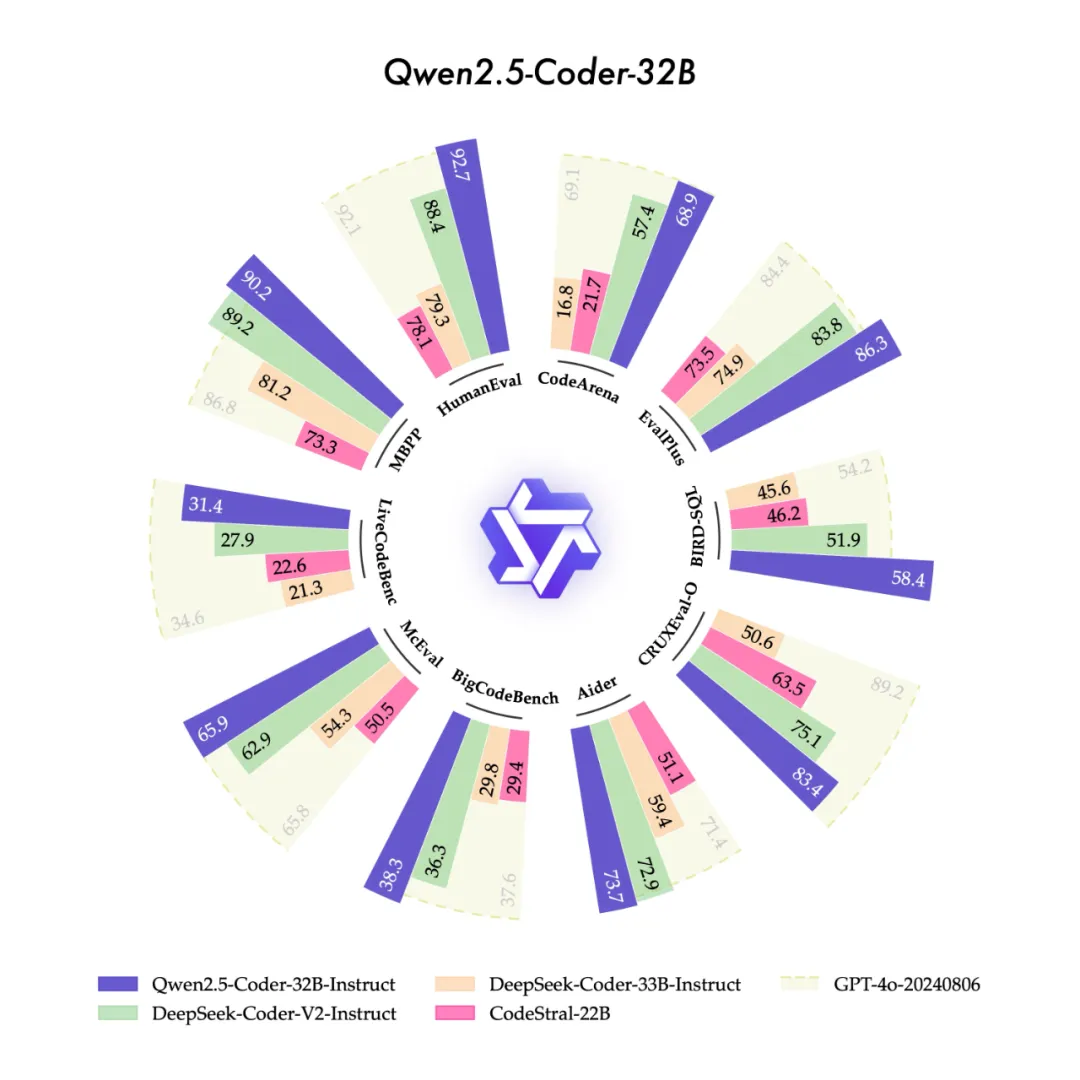
今天,我们很高兴开源“强大”、“多样”、“实用”的Qwen2.5-Coder全系列模型,致力于持续推动Open CodeLLMs的发展。

MME-Finance 是一个专为金融领域设计的多模态基准测试,由同花顺财经旗下的 HiThink 研究团队联合多家高校共同开发,旨在评估和提升多模态大型语言模型(MLLMs)在金融领域的专业理解和推理能力。

在Prompt工程领域,规划任务一直以来都是一个巨大的挑战,因为这要求大语言模型(LLMs)不仅能够理解自然语言,还能有效执行复杂推理和应对长时间跨度的操作。

算法设计(AD)对于各个领域的问题求解至关重要。大语言模型(LLMs)的出现显著增强了算法设计的自动化和创新,提供了新的视角和有效的解决方案。
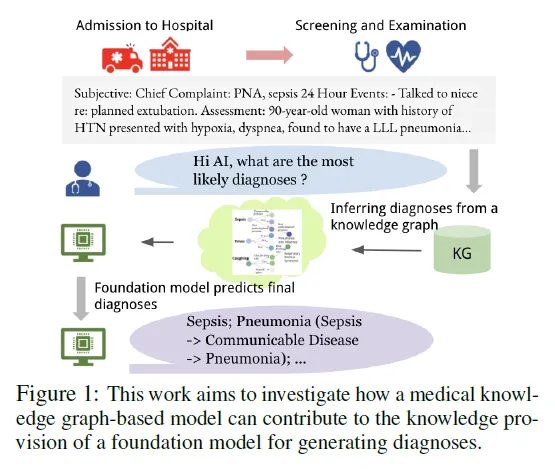
近年来,生成式大型语言模型(LLMs)在各类语言任务中的表现令人瞩目,但在医疗领域的应用面临诸多挑战,尤其是在减少诊断错误和避免对患者造成伤害方面。

来自华东师范大学、南洋理工和中科院等高校的联合研究团队提出了一种新颖的人工智能教育框架“场景-对象-评估”(SOE),旨在利用大型语言模型(LLMs)构建能够模拟人类学生行为和个体差异的虚拟学生代理(LVSA)。

近年来,大语言模型(Large Language Models, LLMs)的研究取得了重大进展,并对各个领域产生了深远影响。然而,LLMs的卓越性能来源于海量数据的大规模训练,这导致LLMs的训练成本明显高于传统模型。
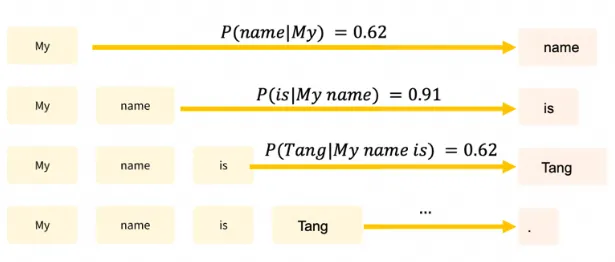
文章详细讨论了如何确保大型语言模型(LLMs)输出结构化的JSON格式,这对于提高数据处理的自动化程度和系统的互操作性至关重要。