
苹果开源了,首次公开手机端侧大模型,AI iPhone 的细节就藏在里面
苹果开源了,首次公开手机端侧大模型,AI iPhone 的细节就藏在里面开源最近成了 AI 圈绕不开的高频热门词汇。 先有 Mistral 8x22B 闷声干大事,后有 Meta Llama 3 模型深夜炸场,现在连苹果也要下场参加这场激烈的开源争霸赛。
来自主题: AI资讯
8125 点击 2024-04-28 12:13
 搜索
搜索
开源最近成了 AI 圈绕不开的高频热门词汇。 先有 Mistral 8x22B 闷声干大事,后有 Meta Llama 3 模型深夜炸场,现在连苹果也要下场参加这场激烈的开源争霸赛。

开源最近成了 AI 圈绕不开的高频热门词汇。

从Llama 3到Phi-3,蹭着开源热乎劲儿,苹果也来搞事情了。

就在刚刚,拥有128位专家和4800亿参数的Arctic,成功登上了迄今最大开源MoE模型的宝座。
Snowflake 发布高「企业智能」模型 Arctic,专注于企业内部应用。
最近,Meta 推出了 Llama 3,为开源大模型树立了新的标杆。

要说 ChatGPT 拉开了大模型竞赛的序幕,那么 Meta 开源 Llama 系列模型则掀起了开源领域的热潮。在这当中,苹果似乎掀起的水花不是很大。

科幻大片中的AR黑科技,竟走进了现实! 就在刚刚,Meta自家的雷朋智能眼镜,已经开始支持多模态版的Llama 3了!要知道,Llama 3的开源版本还没支持多模态呢。
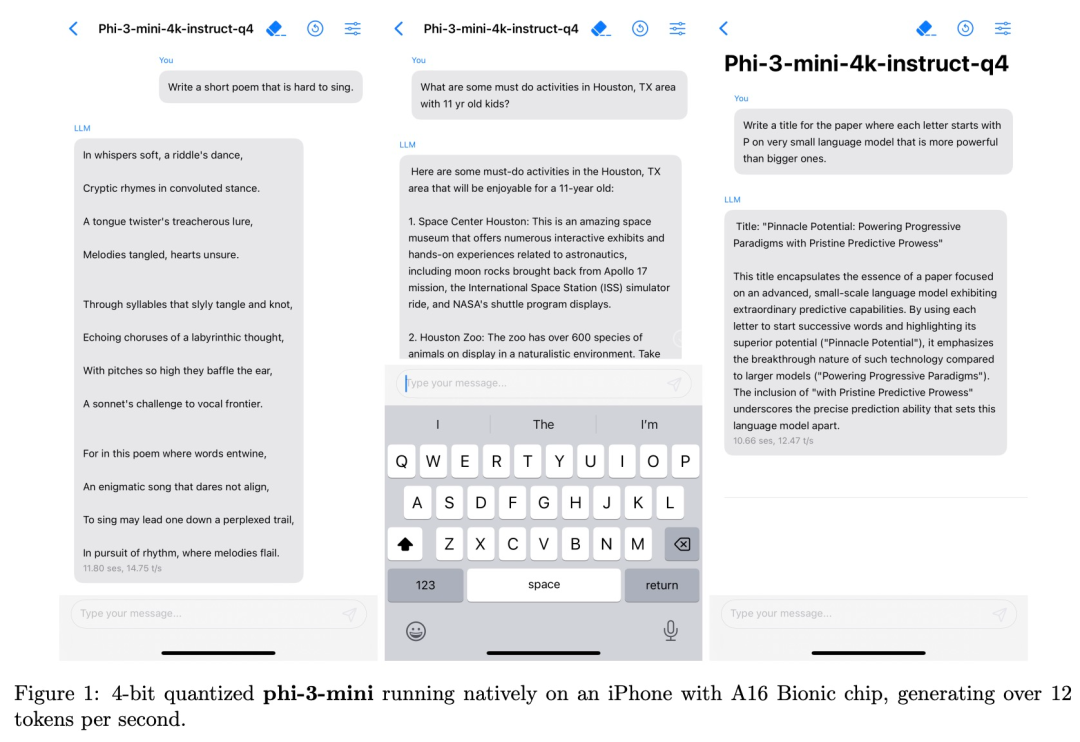
Llama-3 刚发布没多久,竞争对手就来了,而且是可以在手机上运行的小体量模型。
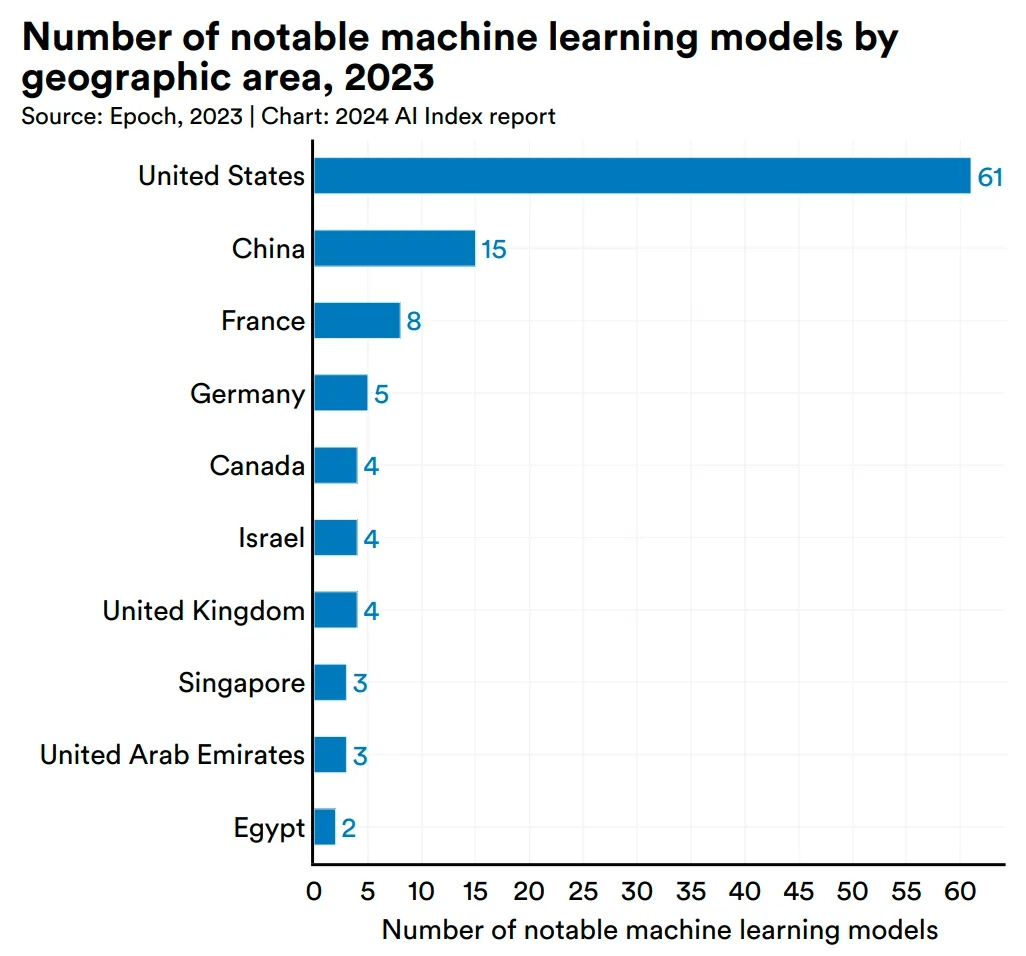
李彦宏说开源模型将越来越落后,然后Llama 3发布了。