全球开源新王Qwen2-72B诞生,碾压Llama3-70B击败国产闭源模型!AI圈大佬转疯了
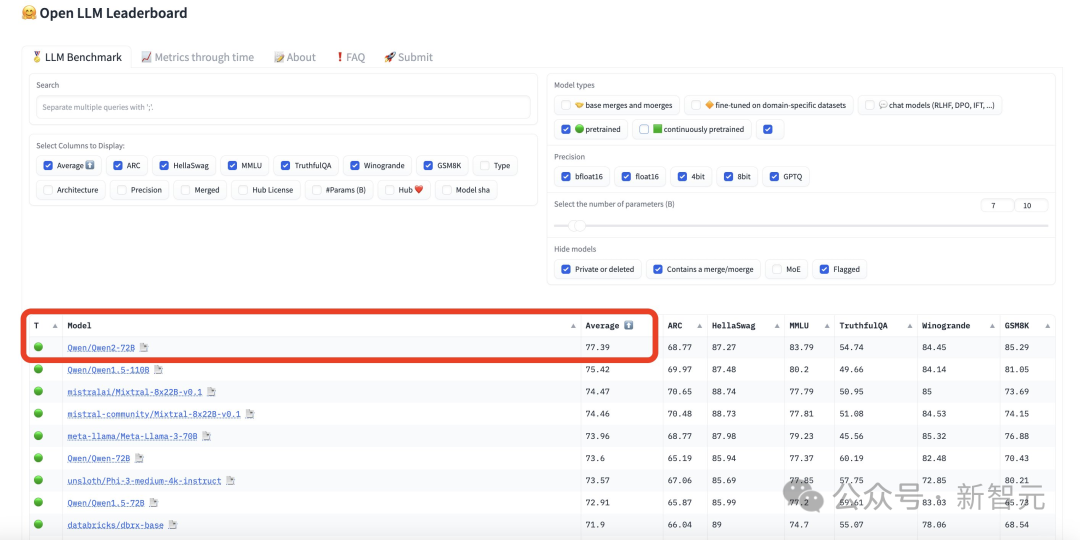
全球开源新王Qwen2-72B诞生,碾压Llama3-70B击败国产闭源模型!AI圈大佬转疯了一夜之间,全球最强开源模型再次易主。万众瞩目的Qwen2-72B一出世,火速杀进开源LLM排行榜第一,美国最强开源模型Llama3-70B直接被碾压!全球开发者粉丝狂欢:果然没白等。
来自主题: AI技术研报
11100 点击 2024-06-08 11:44
 搜索
搜索
一夜之间,全球最强开源模型再次易主。万众瞩目的Qwen2-72B一出世,火速杀进开源LLM排行榜第一,美国最强开源模型Llama3-70B直接被碾压!全球开发者粉丝狂欢:果然没白等。
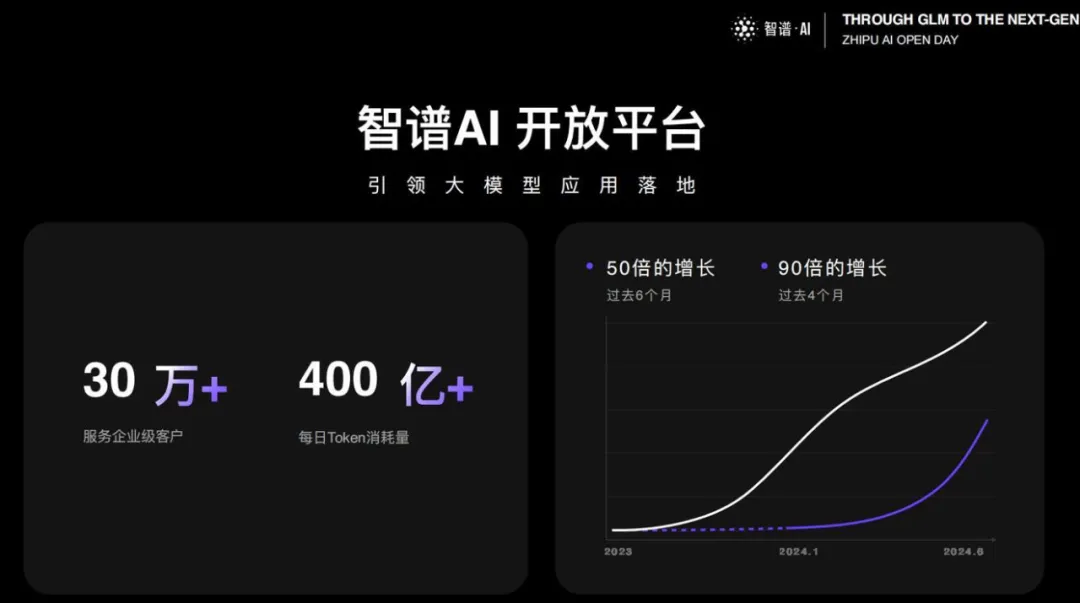
最新版本大模型,6 分钱 100 万 Token。
去年10月,硅谷VC巨头Vinod Khosla曾在X发文,“忧心忡忡”地称美国的开源大模型都会被中国抄去。万万没想到,8个多月过去,射出的回旋镖最终扎回了自己的心。

抄袭框架和预训练数据的情况,是更狭义的套壳。
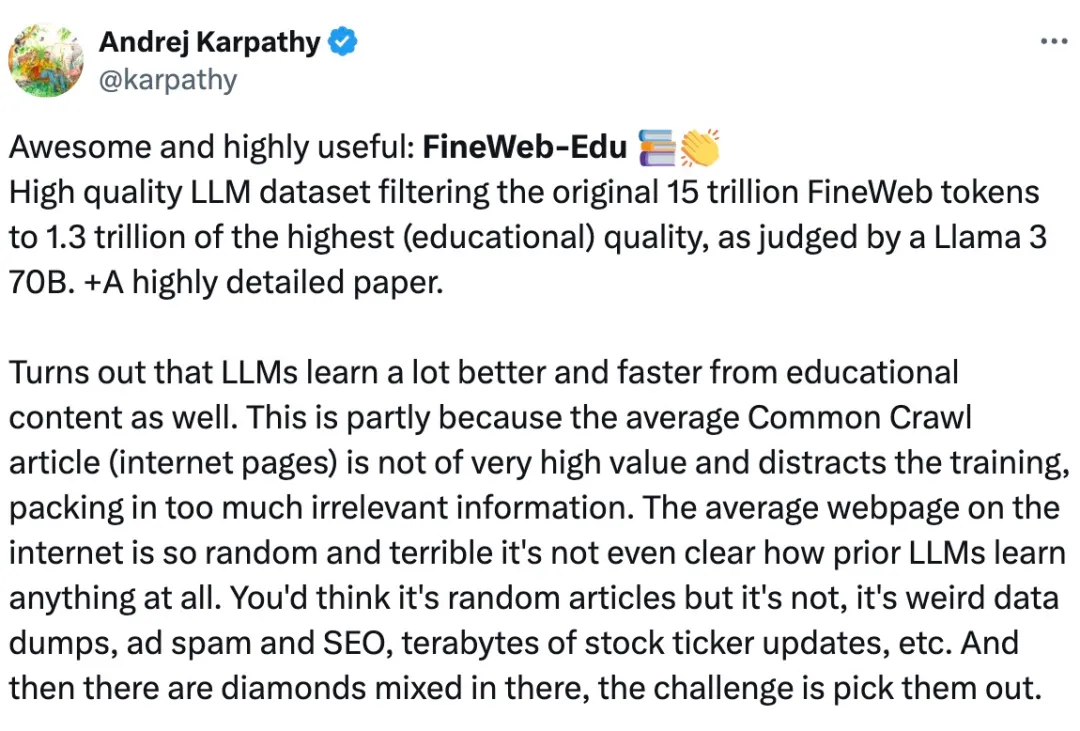
众所周知,对于 Llama3、GPT-4 或 Mixtral 等高性能大语言模型来说,构建高质量的网络规模数据集是非常重要的。然而,即使是最先进的开源 LLM 的预训练数据集也不公开,人们对其创建过程知之甚少。
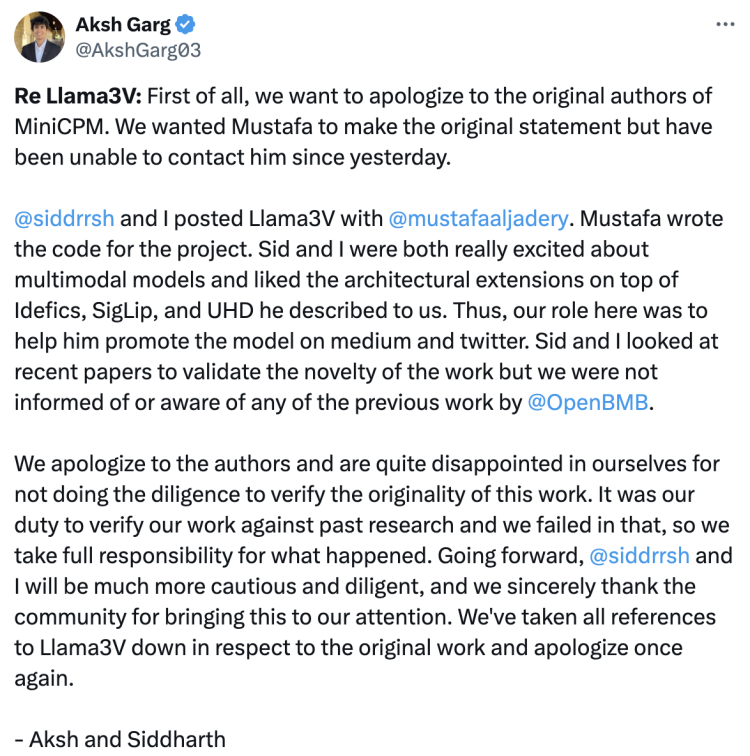
斯坦福团队抄袭清华系大模型事件后续来了—— Llama3-V团队承认抄袭,其中两位来自斯坦福的本科生还跟另一位作者切割了。
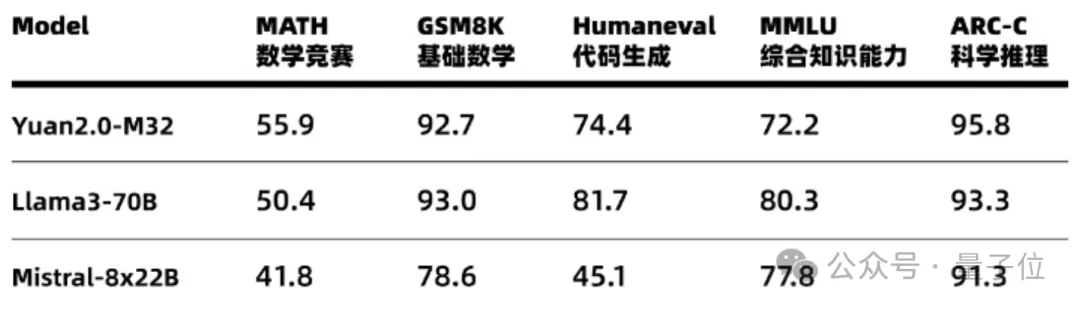
每个token只需要5.28%的算力,精度就能全面对标Llama 3。

把大模型塞进手机里需要几步?

杀疯了!一夜之间,全球最强端侧多模态模型再次刷新,仅用8B参数,击败了多模态巨无霸Gemini Pro、GPT-4V。而且,其OCR长难图识别刷新SOTA,图像编码速度暴涨150倍。这是国产头部大模型公司献给开发者们最浪漫的520礼物。
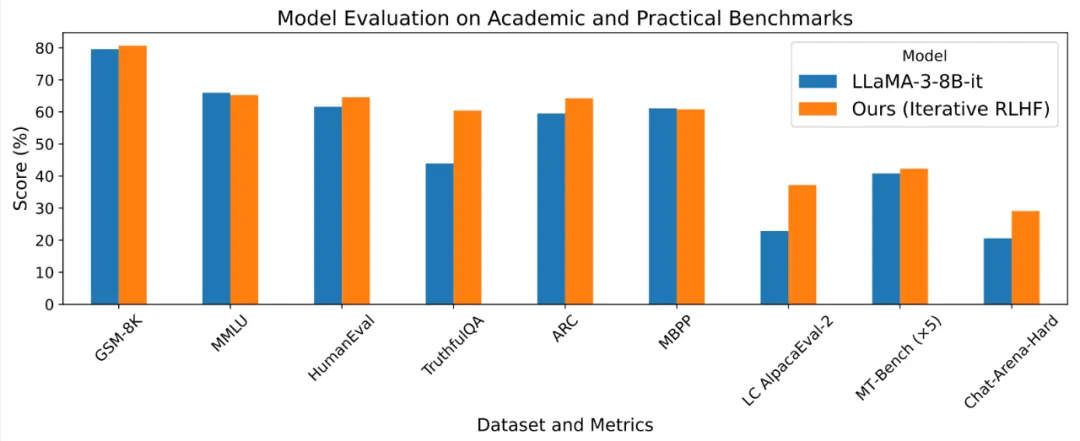
基于人类反馈的强化学习 (RLHF) 使得大语言模型的输出能够更加符合人类的目标、期望与需求,是提升许多闭源语言模型 Chat-GPT, Claude, Gemini 表现的核心方法之一。