
14 项任务测下来,GPT4V、Gemini等多模态大模型竟都没什么视觉感知能力?
14 项任务测下来,GPT4V、Gemini等多模态大模型竟都没什么视觉感知能力?2023-2024年,以 GPT-4V、Gemini、Claude、LLaVA 为代表的多模态大模型(Multimodal LLMs)已经在文本和图像等多模态内容处理方面表现出了空前的能力,成为技术新浪潮。
来自主题: AI技术研报
10198 点击 2024-05-10 23:32
 搜索
搜索
2023-2024年,以 GPT-4V、Gemini、Claude、LLaVA 为代表的多模态大模型(Multimodal LLMs)已经在文本和图像等多模态内容处理方面表现出了空前的能力,成为技术新浪潮。

GPT-4V 的推出引爆了多模态大模型的研究。GPT-4V 在包括多模态问答、推理、交互在内的多个领域都展现了出色的能力,成为如今最领先的多模态大模型。
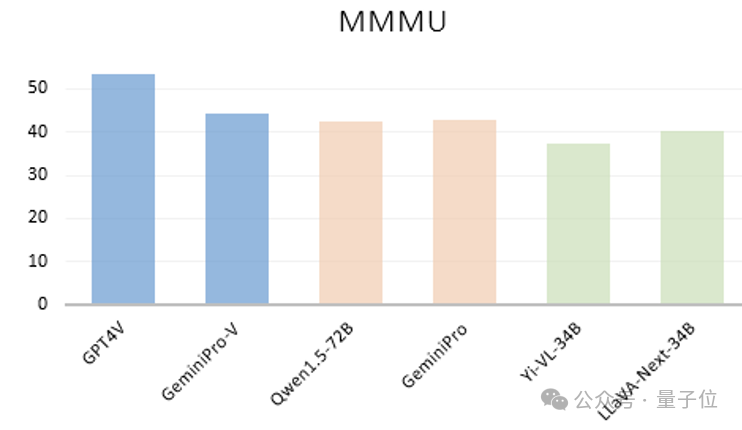
大模型不看图,竟也能正确回答视觉问题?!中科大、香港中文大学、上海AI Lab的研究团队团队意外发现了这一离奇现象。他们首先看到像GPT-4V、GeminiPro、Qwen1.5-72B、Yi-VL-34B以及LLaVA-Next-34B等大模型,不管是闭源还是开源,语言模型还是多模态,竟然只根据在多模态基准MMMU测试中的问题和选项文本,就能获得不错的成绩。

2023 年我们正见证着多模态大模型的跨越式发展,多模态大语言模型(MLLM)已经在文本、代码、图像、视频等多模态内容处理方面表现出了空前的能力,成为技术新浪潮。以 Llama 2,Mixtral 为代表的大语言模型(LLM),以 GPT-4、Gemini、LLaVA 为代表的多模态大语言模型跨越式发展。

混合专家(MoE)架构已支持多模态大模型,开发者终于不用卷参数量了!北大联合中山大学、腾讯等机构推出的新模型MoE-LLaVA,登上了GitHub热榜。

对于大型视觉语言模型(LVLM)而言,扩展模型可以有效提高模型性能。然而,扩大参数规模会显著增加训练和推理成本,因为计算中每个 token 都会激活所有模型参数。

多模态大模型GPT-4V也会「有眼无珠」。UC San Diego纽约大学研究人员提出全新V*视觉搜索算法逆转LLM弱视觉宿命。

GPT-4V的开源替代方案来了!极低成本,性能却类似,清华、浙大等中国顶尖学府,为我们提供了性能优异的GPT-4V开源平替。

最近,来自北京大学等机构研究者提出了一种全新视觉语言大模型——Video-LLaVA,使得LLM能够同时接收图片和视频为输入。Video-LlaVA在下游任务中取得了卓越的性能,并在图片、视频的13个基准上达到先进的性能。这个结果表明,统一LLM的输入能让LLM的视觉理解能力提升。
AI能理解搞笑视频笑点在哪里了。北大等团队开源视觉语言大模型Video-LLaVA,将图像和视频表示对齐到统一的视觉特征空间,在13个图片和视频基准上达到先进的性能。