
华为具身大脑一号位朱森华创业,具脑磐石获亿元级融资,用认知科学造世界模型
华为具身大脑一号位朱森华创业,具脑磐石获亿元级融资,用认知科学造世界模型刚刚完成新一轮亿元融资的具脑磐石,从成立之初押注的正是这个方向。具脑磐石由朱森华创立。他曾任华为云AI算法创新Lab主任,主导过AI脑科学云平台、盘古具身大模型、全球具身智能产业创新中心等系统级项目。在业内,他被称为“华为具身大脑一号位”。
来自主题: AI资讯
10311 点击 2026-05-25 10:27
 搜索
搜索
刚刚完成新一轮亿元融资的具脑磐石,从成立之初押注的正是这个方向。具脑磐石由朱森华创立。他曾任华为云AI算法创新Lab主任,主导过AI脑科学云平台、盘古具身大模型、全球具身智能产业创新中心等系统级项目。在业内,他被称为“华为具身大脑一号位”。

感谢 120 个生鸡蛋,它向全世界证明了,AI 还无法「开除人类」。
FlashLabs 创始人石一,过去一年就活在这个问题里。他做了一系列在外人看来相当反常识的决定:推翻产品路线、主动缩减团队、放弃短期商业化指标,甚至把公司名字都改了。我们和他聊了聊,在通用模型进化的时代,曾经的垂类 AI 创企到底该怎么活下去。

“这是我见过最激烈的竞争之一,甚至可能是资本主义历史上最激烈的竞争。”这是谷歌 DeepMind CEO Demis Hassabis 在访谈中对这场 AI 竞赛的评论。著名科技作家 Sebastian Mallaby 甚至直接将 AI 类比为现代的曼哈顿计划。

创始人杨昌鹏曾任华为云媒体创新 Lab 首任主任、交互式媒体方向 1 号位。
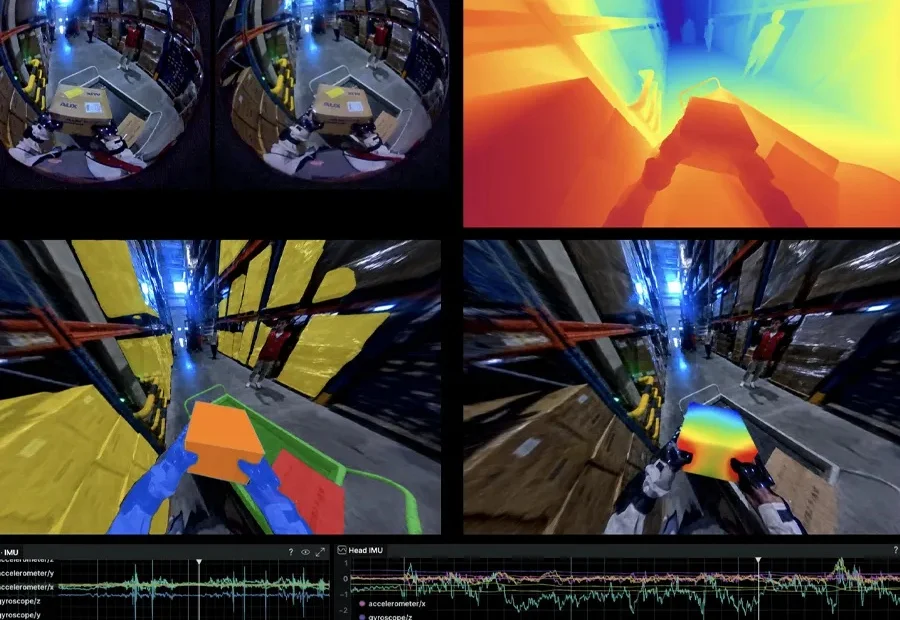
前北京人形数据负责人创业,给出即插即用的灵巧操作方案。
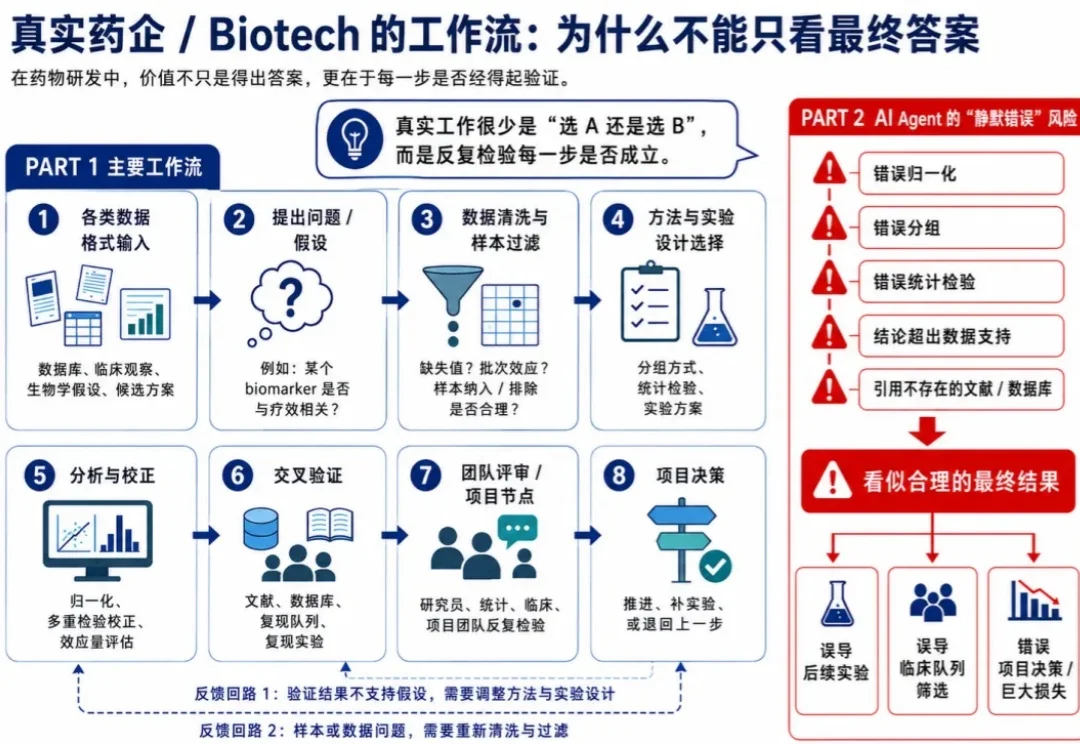
xbench,就是红杉自己弄的那个中立评测lab,刚刚又整了个新活:让 AI 做药企的数据分析,跟人类实习生比个高低,然后遥遥领先的赢了

由拍我AI(PixVerse)· PixLab影像内容实验室出品,3人核心团队、制作3个月、3万元算力成本,用AI把历史上著名的“妃告皇”离婚案(淑妃文绣状告末代皇帝溥仪虐待并申请离婚)做成了一支近17分钟的AI短片。

从谷歌DeepMind分拆而出的AI药物英国研发公司Isomorphic Labs昨日宣布完成21亿美元(约合人民币143亿元)B轮融资。据外媒Ventureburn报道,这笔融资创下全球AI制药行业单笔融资新纪录。

如果把AI丢进一个没有标准答案的工程现场,它还能活下来吗?