
教授何恺明在MIT的第二门课——《深度生成模型》,讲座PPT陆续已出
教授何恺明在MIT的第二门课——《深度生成模型》,讲座PPT陆续已出又有机会跟着大神学习了! 今年 2 月起,何恺明已经开始了自己在 MIT 的副教授职业生涯,并在 3 月 7 日走上讲台完成了「人生中教的第一堂课」。
来自主题: AI资讯
6279 点击 2024-11-10 14:21
 搜索
搜索
又有机会跟着大神学习了! 今年 2 月起,何恺明已经开始了自己在 MIT 的副教授职业生涯,并在 3 月 7 日走上讲台完成了「人生中教的第一堂课」。
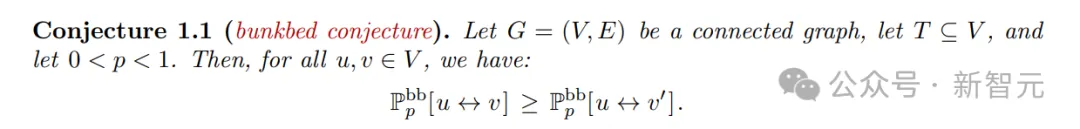
39年来一个看似理所当然的数学理论,刚刚被数学家证伪!UCLA和MIT的研究者证实:概率论中众所周知的假设「上下铺猜想」是错的。有趣的是,他们用AI已经证明到了99.99%的程度,但最终,靠的还是理论论证。

Max Tegmark团队又出神作了!他们发现,LLM中居然存在人类大脑结构一样的脑叶分区,分为数学/代码、短文本、长篇科学论文等部分。这项重磅的研究揭示了:大脑构造并非人类独有,硅基生命也从属这一法则。

TimeMixer++是一个创新的时间序列分析模型,通过多尺度和多分辨率的方法在多个任务上超越了现有模型,展示了时间序列分析的新视角,在预测和分类等任务带来了更高的准确性和灵活性。

斯坦福吴佳俊团队与MIT携手打造的最新研究成果,让我们离实时生成开放世界游戏又近了一大步。

TL;DR:DuoAttention 通过将大语言模型的注意力头分为检索头(Retrieval Heads,需要完整 KV 缓存)和流式头(Streaming Heads,只需固定量 KV 缓存),大幅提升了长上下文推理的效率,显著减少内存消耗、同时提高解码(Decoding)和预填充(Pre-filling)速度,同时在长短上下文任务中保持了准确率。


一台4090笔记本,秒生1K质量高清图。英伟达联合MIT清华团队提出的Sana架构,得益于核心架构创新,具备了惊人的图像生成速度,而且最高能实现4k分辨率。
近日,来自斯坦福、MIT、纽约大学和Meta-FAIR等机构的研究人员,通过新的研究重新定义了最大流形容量表示法(MMCR)的可能性。

近日,MIT团队推出了自动搞科研的AI系统——SciAgents。在仿生材料的研究中,模型揭示了以前被认为无关的一些跨学科联系,实现了超越传统人类研究方法的规模、精度和探索能力。