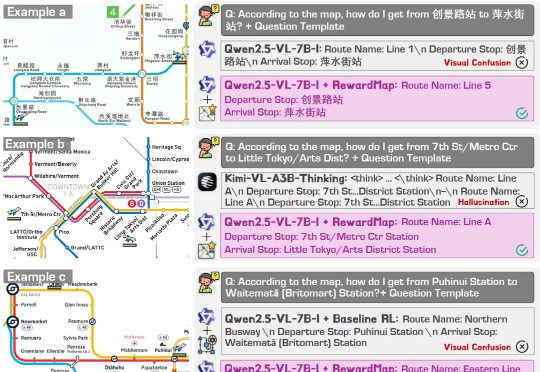
RewardMap: 通过多阶段强化学习解决细粒度视觉推理的Sparse Reward
RewardMap: 通过多阶段强化学习解决细粒度视觉推理的Sparse Reward近年来,大语言模型(LLMs)以及多模态大模型(MLLMs)在多种场景理解和复杂推理任务中取得突破性进展。
来自主题: AI技术研报
7419 点击 2025-10-21 15:53
 搜索
搜索
近年来,大语言模型(LLMs)以及多模态大模型(MLLMs)在多种场景理解和复杂推理任务中取得突破性进展。

近年来,多模态大语言模型(Multimodal Large Language Models, MLLMs)在图文理解、视觉问答等任务上取得了令人瞩目的进展。然而,当面对需要精细空间感知的任务 —— 比如目标检测、实例分割或指代表达理解时,现有模型却常常「力不从心」。
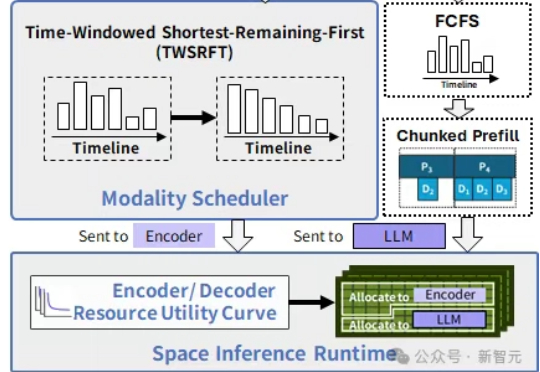
在中国科学院计算技术研究所入选NeurIPS 2025的新论文中,提出了SpaceServe的突破性架构,首次将LLM推理中的P/D分离扩展至多模态场景,通过EPD三阶解耦与「空分复用」,系统性地解决了MLLM推理中的行头阻塞难题。
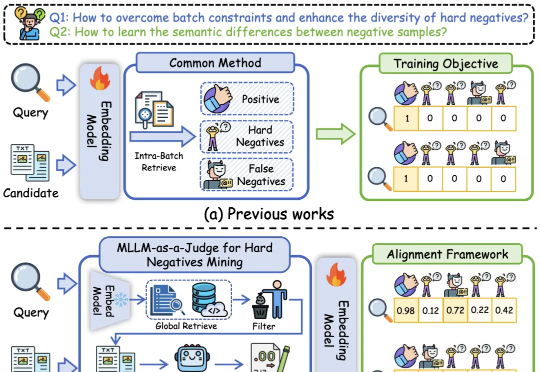
基于多模态大模型语义理解能力的统一多模态嵌入模型UniME-V2。该方法首先通过全局检索构建潜在困难负例集,随后创新性地引入“MLLM-as-a-Judge”机制:利用MLLM对查询-候选对进行语义对齐评估,生成软语义匹配分数。
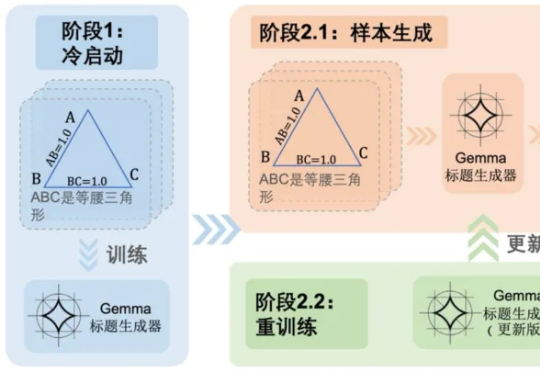
随着多模态大语言模型(MLLMs)在视觉问答、图像描述等任务中的广泛应用,其推理能力尤其是数学几何问题的解决能力,逐渐成为研究热点。 然而,现有方法大多依赖模板生成图像 - 文本对,泛化能力有限,且视

在科研、新闻报道、数据分析等领域,图表是信息传递的核心载体。要让多模态大语言模型(MLLMs)真正服务于科学研究,必须具备以下两个能力
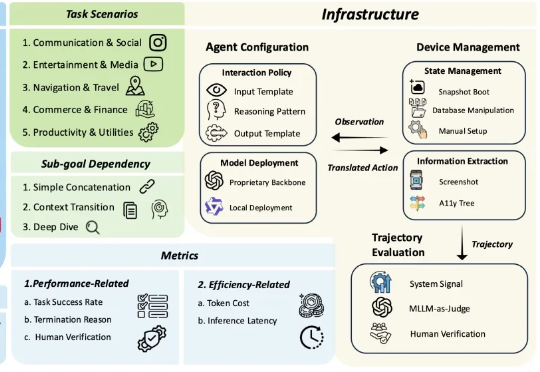
多模态大模型 (MLLM) 驱动的 OS 智能体在单屏动作落实(如 ScreenSpot)、短链操作任务(如 AndroidControl)上展现出突出的表现,标志着端侧任务自动化的初步成熟。

近年来,多模态大模型(MLLMs)发展迅猛,从看图说话到视频理解,似乎无所不能。
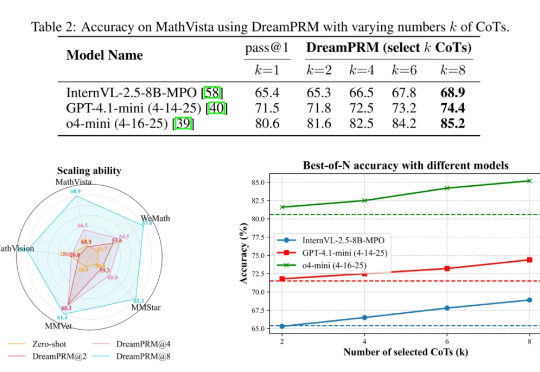
使用过程奖励模型(PRM)强化大语言模型的推理能力已在纯文本任务中取得显著成果,但将过程奖励模型扩展至多模态大语言模型(MLLMs)时,面临两大难题:

在多模态大语言模型(MLLMs)应用日益多元化的今天,对模型深度理解和分析人类意图的需求愈发迫切。尽管强化学习(RL)在增强大语言模型(LLMs)的推理能力方面已展现出巨大潜力,但将其有效应用于复杂的多模态数据和格式仍面临诸多挑战。