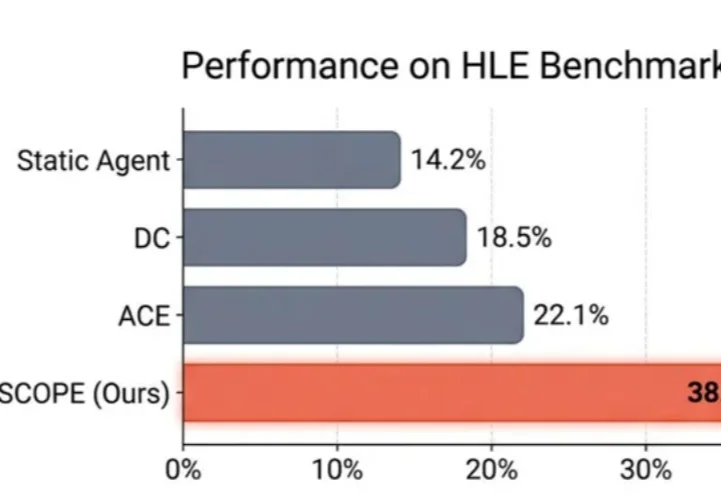
Agent「记吃不记打」?华为诺亚&港中文发布SCOPE:Prompt自我进化,让HLE成功率翻倍
Agent「记吃不记打」?华为诺亚&港中文发布SCOPE:Prompt自我进化,让HLE成功率翻倍在 LLM Agent 领域,有一个常见的问题:Agent 明明 "看到了" 错误信息,却总是重蹈覆辙。
来自主题: AI技术研报
8777 点击 2025-12-30 09:54
 搜索
搜索
在 LLM Agent 领域,有一个常见的问题:Agent 明明 "看到了" 错误信息,却总是重蹈覆辙。
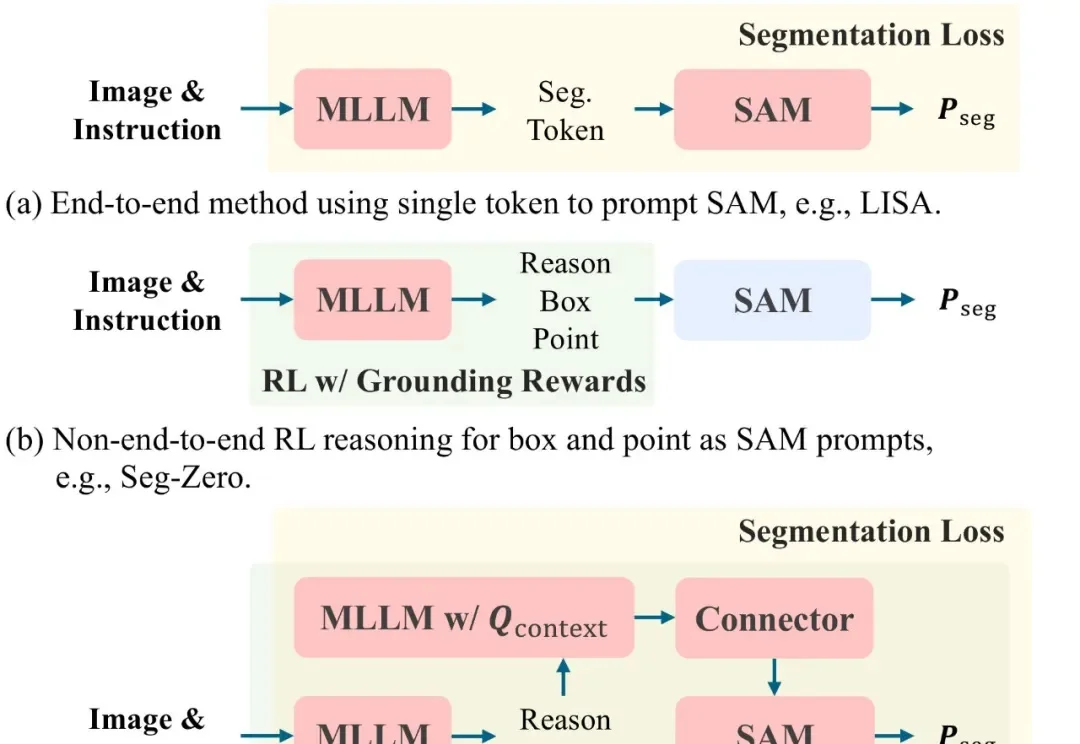
文本提示图像分割(Text-prompted image segmentation)是实现精细化视觉理解的关键技术,在人机交互、具身智能及机器人等前沿领域具有重大的战略意义。这项技术使机器能够根据自然语言指令,在复杂的视觉场景中定位并分割出任意目标。

最初只是我写了一个特别好玩的 prompt,那个 prompt 是一个代入修仙世界的文字游戏,没想到这个 prompt 会成为所有故事的起点。后来我们把 prompt 包了一下,上了个简单的网页,实际上开发1周,形态是chatbox,纯文本+流式输出,有选项、死亡状态,非常简单的一波流的小玩具,但是也收到了很多正向反馈。

最绝望的事,莫过于,错过了自己那个本该精彩的人生。所以,我突然有一个想法,就是AI明明现在都这么强了。那,为什么不可以,帮我挖掘我们自己真正的天赋呢?说干就干,在花了一下午时间,迭代了好多版Prompt之后。

用零手写代码、零成本、零部署压力的“三无”AI生成应用,把Prompt换成真金白银的第一批“野生开发者”已经出现了。

正如奥特曼执意打造硬件,试图打破手机屏束缚,要让 AI 感受物理世界;Looki 的诞生也源于同样的渴望:补齐大模型「感官智能」的最后拼图,将现实场景实时转化为上下文,驱动人机交互从「被动问答」进化为「主动共鸣」。
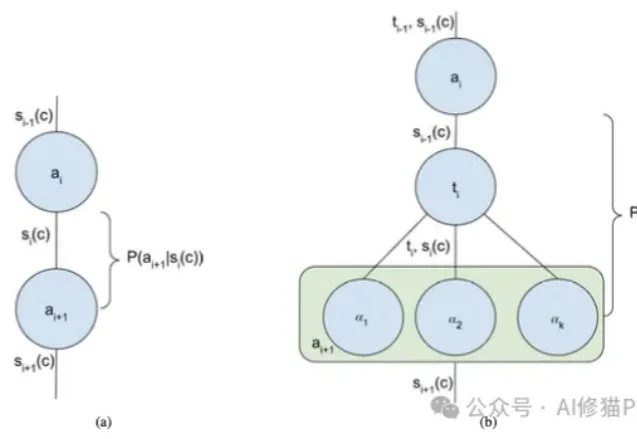
我们正处在一个AI Agent(智能体)爆发的时代。从简单的ReAct循环到复杂的Multi-Agent Swarm(多智能体蜂群),新的架构层出不穷。但在这些眼花缭乱的名词背后,开发者的工作往往更像是一门“玄学”,我们凭直觉调整提示词,凭经验增加Agent的数量,却很难说清楚为什么某个架构在特定任务上表现更好。
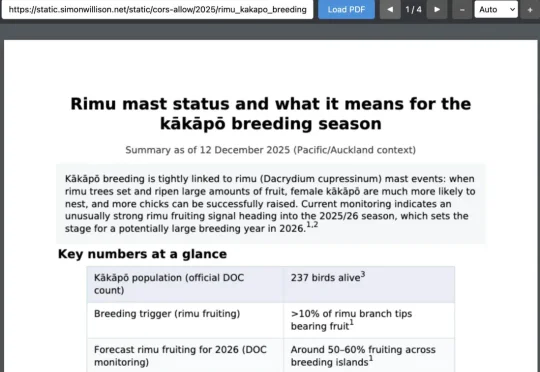
还在争论Skills是不是prompt?已经可以停下火了。因为,刚刚得到的消息消息,OpenAI已经悄悄地用上了Skills了。今天,知名博主、Django Web 框架联合创始人Simon Willson爆料:

宾夕法尼亚大学沃顿商学院(The Wharton School)今年发布了一系列名为《Prompting Science Reports》的重磅研究报告。他们选取了2024-2025最常用的模型(如GPT-4o, Claude 3.5 Sonnet, Gemini Pro/Flash等),在极高难度的博士级基准测试(GPQA Diamond)上进行了数万次的严谨测试。

最近口述采样很火。如果您经常使用经过“对齐”训练(如RLHF)的LLM,您可能已经注意到一个现象:模型虽然变得听话、安全了,但也变得巨“无聊”。