
Markdown要凉…卡帕西也站HTML了
Markdown要凉…卡帕西也站HTML了Markdown,当死。
来自主题: AI资讯
10557 点击 2026-05-12 14:54
 搜索
搜索
Markdown,当死。

Claw-Eval-Live提出「活的」benchmark概念,通过信号采集与任务筛选,确保评测内容紧跟企业实际痛点,而非固定不变的题库。评测不仅关注结果,还追踪执行过程,从数据调用到状态变更,全面验证Agent的真实能力。
刚刚,在X上Claude Code工程师Thariq的一篇分享——他几乎停止使用 Markdown,转而使用 Claude Code 生成 HTML 文件。在短短几个小时里,这篇帖子的浏览量就突破了 200 万。
随手打开 GitHub,2026 年的 Agent 项目热榜上有这样一个仓库: • 27,000+ stars,1,800+ forks • 零行 Python,零行 TypeScript,零行 JS • 作者是 Obsidian 的 CEO 本人,kepano • 整个仓库就是 5 个 Markdown 文件

5月6日,主营AI招聘的初创公司Ethos宣布完成2275万美元(约合人民币1.55亿元)的A轮融资,由a16z领投,General Catalyst、XTX Markets、Evantic Capital和Common Magic跟投。

SWE-Bench 的创建者,刚刚又放出了一个地狱级新 benchmark。

这个人叫 Alex Gerko,今年 46 岁,他是量化交易巨头 XTX Markets 的创始人。早在 ChatGPT 成为全民话题之前,他就已经搭建起一套纯粹以盈利为目的的 AI 交易系统。他在冰岛部署的这台超级计算机,正是 XTX 交易帝国的“算力大脑”。这台机器存储着超过 400 PB(约相当于 80 万亿张高清数码照片)的全球金融市场数据,并驱动着庞大的 GPU 集群。
一款名为 MotuBrain 的神秘世界模型,悄无声息地登上两个国际 benchmark 的榜首,没有任何公司署名。如果只是单榜第一,这件事或许并不稀奇。但问题在于,它同时拿下的,是两个几乎代表行业「两个极点」的榜单:一个是衡量世界模型「是否真正理解和预测现实世界」的 WorldArena
现象级AI视频技术、字节Seedance 2.0在arXiv发论文了。晒了26页的Benchmark,和贡献者名单。170位团队成员全公开,署名和尊重都拉满了,不过嘛这就不怕……嘛?
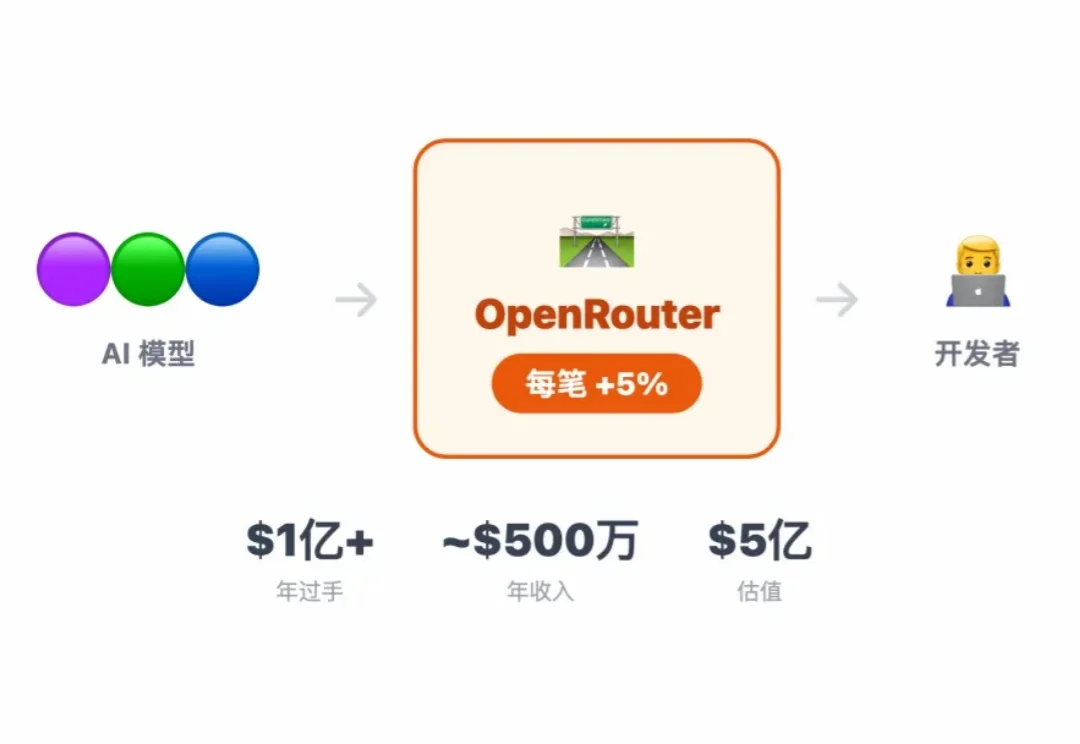
本文是「小龙虾搞钱指南」系列第 4 篇。前两篇拆了 Polymarket 交易 Bot 和 Skill 经济变现 以及用 ai 实现股票快速跟踪,这篇聊一个更底层的生意——帮别人调 AI 的"中间商",是怎么赚到钱的。