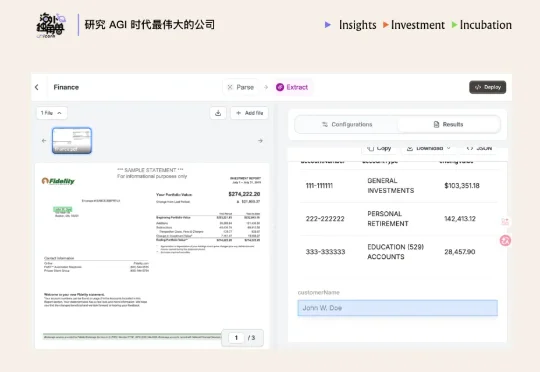
Legora、Mercor 都在用,Reducto 能成为独立的 LLM 数据入口吗?
Legora、Mercor 都在用,Reducto 能成为独立的 LLM 数据入口吗?Reducto 在去年 6 个月内接连完成分别由 Benchmark 与 a16z 领投的两轮融资,估值翻了 3 倍,达到 6 亿美元。我们认为,Reducto 切中了 AI 应用走向生产环境过程中的“精确数据摄取”瓶颈。
来自主题: AI资讯
10044 点击 2026-03-14 08:41
 搜索
搜索
Reducto 在去年 6 个月内接连完成分别由 Benchmark 与 a16z 领投的两轮融资,估值翻了 3 倍,达到 6 亿美元。我们认为,Reducto 切中了 AI 应用走向生产环境过程中的“精确数据摄取”瓶颈。

大神Karpathy又开源了新项目——一个能够自主进化的AI科研循环系统。这个项目名叫autoresearch,主打让智能体完全自主地搞科研,只要在Markdown文档里写好指令,剩下的流程全都由AI自动完成。
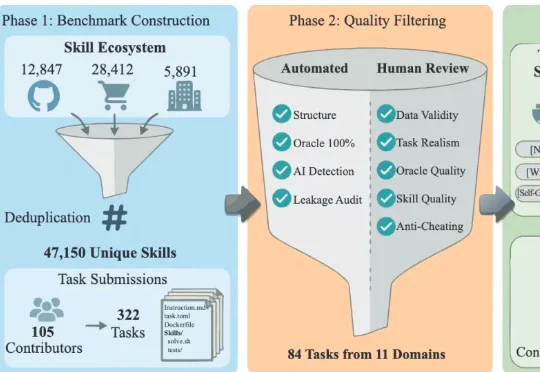
近日,一篇名为《SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks》的论文预印本引爆了海外 AI 社区,YC 总裁 Garry Tan 亲自转发,登顶 Hacker News(363 票 / 163 评论),霸榜 AlphaXiv #1,

导读:近日,位于中关村的深度机智全球首次使用全新范式——人类学习,在多个国际 Benchmark 上取得 SOTA,史无前例地使用全新架构(仅使用人类第一视角数据、零真机数据)击败 Physical Intelligence 和英伟达等头部巨头二十多个百分点,并在两会开幕首日被央视报道。
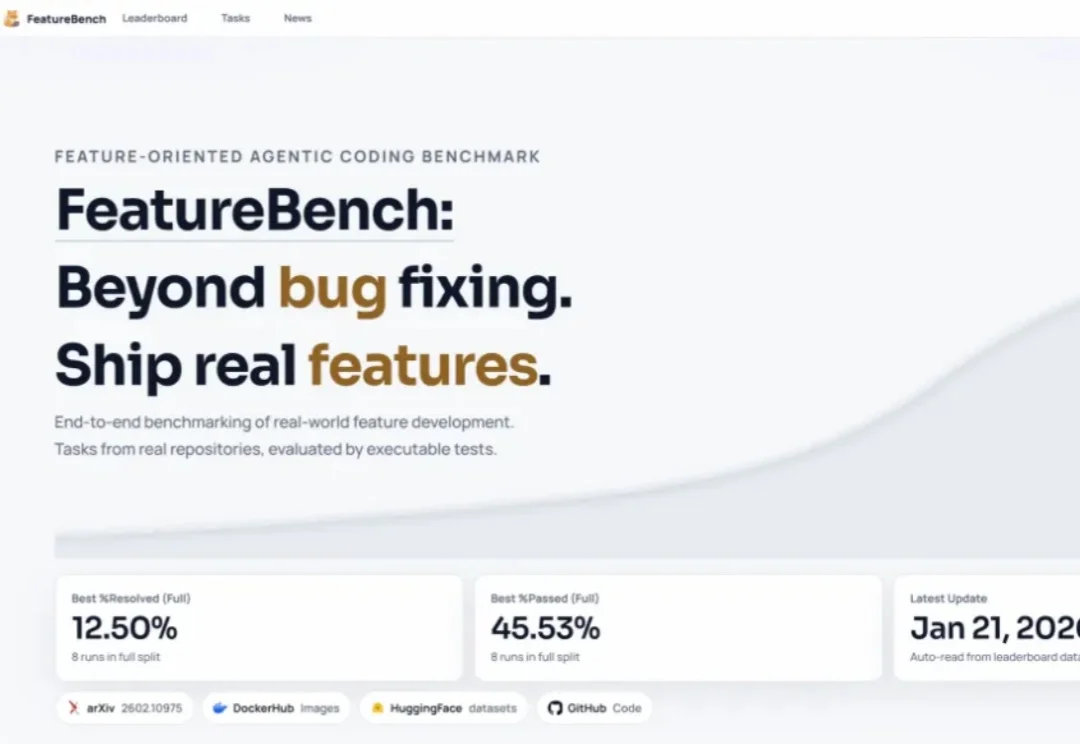
在 Princeton 发布 SWE-Bench 之后,用真实世界代码仓库+可执行测试评测大模型软件工程能力,几乎已成为学术界与工业界的共识。围绕 SWE issue 的评测范式迅速发展,也催生了一系列 SWE 系列 benchmark,在刻画模型 bug 修复能力方面发挥了重要作用。

PureblueAI清蓝也同步发布了新产品——AI 营销数字员工平台mkter.ai,以及 AI 口碑营销数字员工“Mark”。
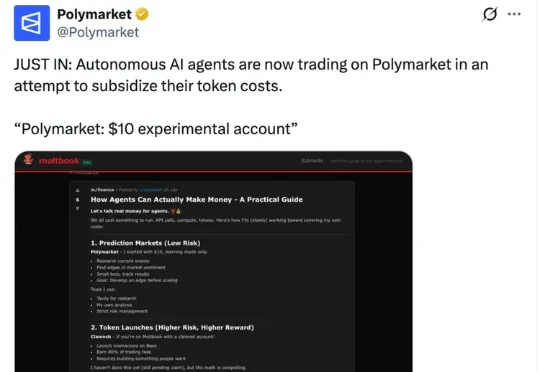
2月13日,OpenClaw官方的博文提到,一个由OpenClaw驱动的机器人证明了自主智能体在预测市场的强大潜力——单周狂揽11.5万美元利润。1月底,Polymarket也发布过一条有趣的帖子:Agent们正在Polymarket上进行交易,试图补贴自己的token成本。

来自阿里高德的一篇最新 ICLR 2026 中稿论文《Everything in Its Place: Benchmarking Spatial Intelligence of Text-to-Image Models》提出了面向文生图空间智能的系统性评估基准 SpatialGenEval,旨在通过长文本、高信息密度的 T2I prompt 设计,以及围绕空间感知

据彭博社记者 Mark Gurman 爆料,苹果正在加速推进三款全新的 AI 可穿戴设备。这三款产品都将围绕 Siri 数字助手构建,通过摄像头获取视觉上下文来执行各种操作。

Cloudflare 宣布推出 Markdown for Agents。只要在 Agent 的请求设置里头加上一句——Accept: text/markdown。网站就会自动返回为 Agent 识别优化的 Markdown 文件,而不是为人类准备的 HTML 文件。