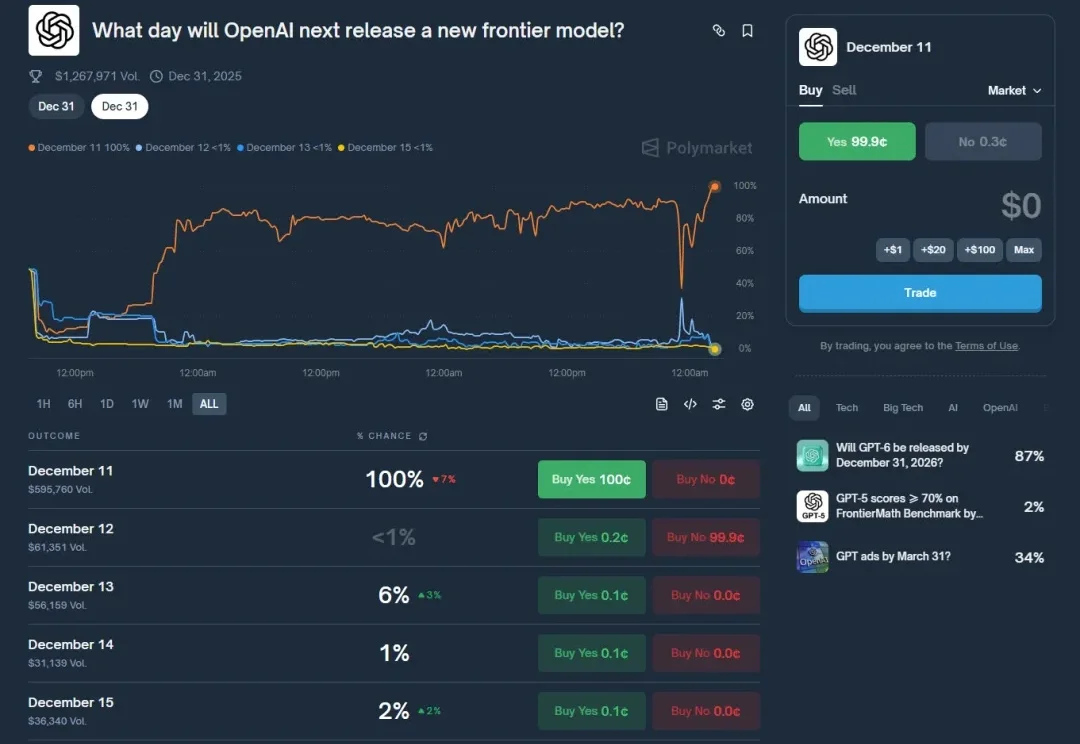
AI圈最准的消息,都藏在这个小小的Web3网站里。
AI圈最准的消息,都藏在这个小小的Web3网站里。GPT-5.2也发布了有几天了。
来自主题: AI资讯
6957 点击 2025-12-15 15:21
 搜索
搜索
GPT-5.2也发布了有几天了。

救大命,OpenAI首席研究官Mark Chen最新访谈,信息量有点大呀。

基准测试(Benchmarks)在人工智能的发展进程中扮演着至关重要的角色,构成了评价生成式模型(Generative Models)性能的事实标准。对于从事模型训练与评估的AI研究者而言,GSM8K、MMLU等数据集的数据质量直接决定了评估结论的可靠性。
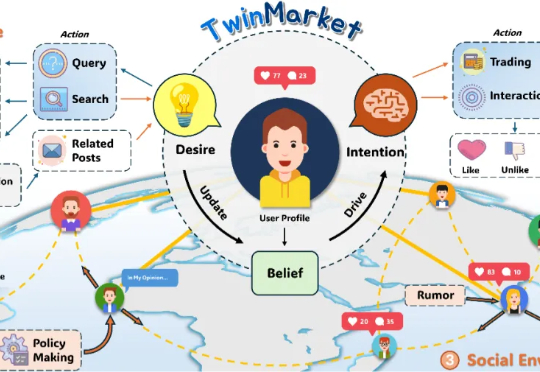
市场不是机器,而是人群;不是公式,而是故事。TwinMarket让AI学会讲述这些故事。 1994年,美国圣塔菲研究所(Santa Fe Institute)推出了一个野心勃勃的项目:人工股票市场(A
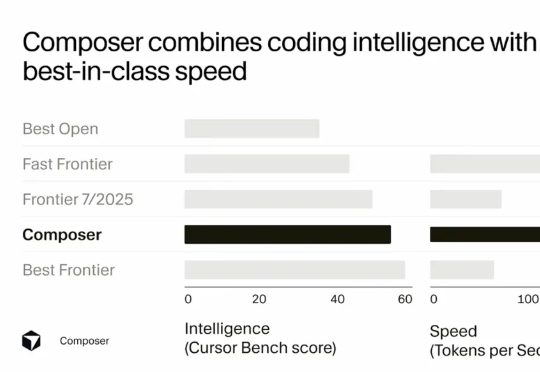
Sasha Rush 在分享开头就提到,Cursor Composer 在他们的内部 benchmark 上的表现几乎与最好的 Frontier 模型(前沿模型)持平,并且优于去年夏天发布的所有模型。它的表现明显好于最好的开源模型,以及那些被标榜为"快速"的模型。

1997年首提AGI的马克·古布鲁德(Mark Gubrud),从地下室论文到被遗忘的命名者;而今AGI成巨头博弈与数千亿美元资本的关键开关,微软与OpenAI以其为合同枢纽与控制权杠杆,标准却愈发模糊。

美国当地时间 10 月 29 日,据外媒消息,AI 编码工具 Cursor 背后的公司 Anysphere 的联合创始人 Arvid Lunnemark 已离职。Cursor 最初由四位联合创始人创立,除了 Lunnemark 之外,还有 Aman Sanger、Michael Truell 和 Sualeh Asif。

当前的训练与评测范式存在一个根本性的局限:几乎所有主流 Benchmark(如 MATH500、AIME)都聚焦于孤立的单步问题,问题之间相互独立,模型只需「回答一个问题,然后结束」。但真实世界的推理场景往往截然不同: 为填补这一空白,复旦大学与美团 LongCat Team 联合推出 R-HORIZON—— 首个系统性评估与增强 LRMs 长链推理能力的方法与基准。

香港科技大学KnowComp实验室提出基于《欧盟人工智能法案》和《GDPR》的LLM安全新范式,构建合规测试基准并训练出性能优异的推理模型,为大语言模型安全管理提供了新方向。

这世上有太多 AI benchmark 了,但没有一个 benchmark 能让你心跳加速。 直到近日,AlphaArena 出现了。 这是由初创团队 NOF1 推出的一个「AI 炒币实盘竞技场」,现在已开放全网围观:竞技场地址:https://nof1.ai/