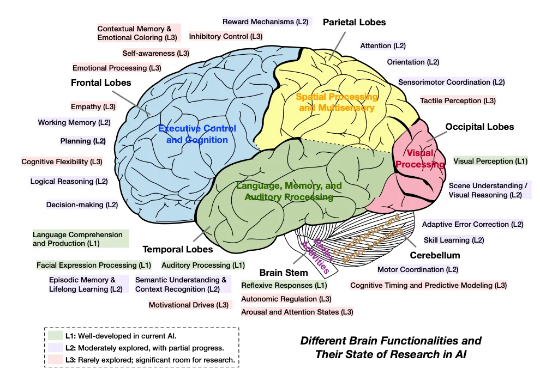
264页 Agent 综述!MetaGPT、Mila、斯坦福、耶鲁、谷歌半年共同撰写
264页 Agent 综述!MetaGPT、Mila、斯坦福、耶鲁、谷歌半年共同撰写,MetaGPT & Mila 联合全球范围内 20 个顶尖研究机构的 47 位学者,共同撰写并发布了长篇综述《Advances and Challenges in Foundation Agents:
来自主题: AI技术研报
13578 点击 2025-04-27 10:41
 搜索
搜索
,MetaGPT & Mila 联合全球范围内 20 个顶尖研究机构的 47 位学者,共同撰写并发布了长篇综述《Advances and Challenges in Foundation Agents:
在DeepSeek R1-V3、GPT-4o、Claude-3.7的强势围攻下,Meta坐不住了。曾作为开源之光的Llama在一年的竞争内连连失利,并没有研发出让公众惊艳的功能。创始人扎克伯格下达死命令,今年4月一定要更新。

,2025年,大模型计算效率的提升并未给AI基建按下暂停键,微软、亚马逊、谷歌、Meta四大科技巨头2025年在AI技术与数据中心的资本支出将达3200亿美元(约合人民币2.33万亿元);OpenAI、软银等企业总投资5000亿美元(约合人民币3.66万亿元)的“星际之门”项目也已动工。在这波AI大基建浪潮中,提供硬件与算力服务的“卖铲人”们正赚得盆满钵满。

一年一度ICLR 2025杰出论文开奖!普林斯顿、UBC、中科大NUS等团队的论文拔得头筹,还有Meta团队「分割一切」SAM 2摘得荣誉提名。
前 Meta 工程师创办的 Lace AI 融资1400万美元,这是一家家庭服务创收软件初创公司。作为 Meta 的 AI 工程师,Boris Valkov 帮助构建了世界上最大的机器学习库之一 PyTorch。在那里,瓦尔科夫意识到人工智能“即将解锁能力,在软件堆栈的应用层中。

当前,强化学习(RL)方法在最近模型的推理任务上取得了显著的改进,比如 DeepSeek-R1、Kimi K1.5,显示了将 RL 直接用于基础模型可以取得媲美 OpenAI o1 的性能不过,基于 RL 的后训练进展主要受限于自回归的大语言模型(LLM),它们通过从左到右的序列推理来运行。

「一位顶尖科学家,有数千亿美元的资源,却仍然能把Meta搞砸了!」最近,圈内对LeCun的埋怨和批评,似乎越来越压不住了。有人批评说,Meta之所以溃败,LeCun的教条主义就是罪魁祸首。但LeCun却表示,自己尝试了20年自回归预测,彻底失败了,所以如今才给LLM判死刑!
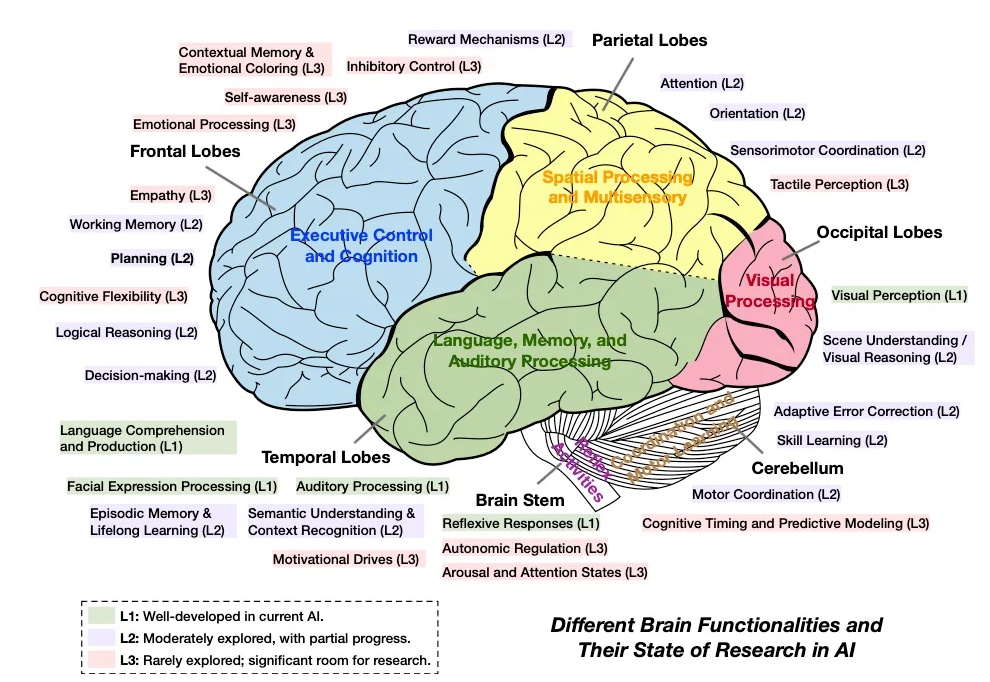
近期,大模型智能体(Agent)的相关话题爆火 —— 不论是 Anthropic 抢先 MCP 范式的快速普及,还是 OpenAI 推出的 Agents SDK 以及谷歌最新发布的 A2A 协议,都预示了 AI Agent 的巨大潜力。

据知情人士透露,过去一年中,Meta Platforms 曾请求微软、亚马逊等公司协助承担其旗舰大语言模型 Llama 的训练成本。该想法反映出对 AI 开发成本激增日益加剧的担忧,企业对资助开源软件犹豫不决。

来自Meta和NYU的团队,刚刚提出了一种MetaQuery新方法,让多模态模型瞬间解锁多模态生成能力!令人惊讶的是,这种方法竟然如此简单,就实现了曾被认为需要MLLM微调才能具备的能力。