
Meta:AI基础设施的未来(演讲/PPT)
Meta:AI基础设施的未来(演讲/PPT)在2024年AI Infra @Scale会议上发表开幕主旨演讲
来自主题: AI资讯
10399 点击 2024-08-28 11:34
 搜索
搜索
在2024年AI Infra @Scale会议上发表开幕主旨演讲

Meta的开源大模型Llama 3在市场上遇冷,进一步加剧了大模型开源与闭源之争的关注热度。
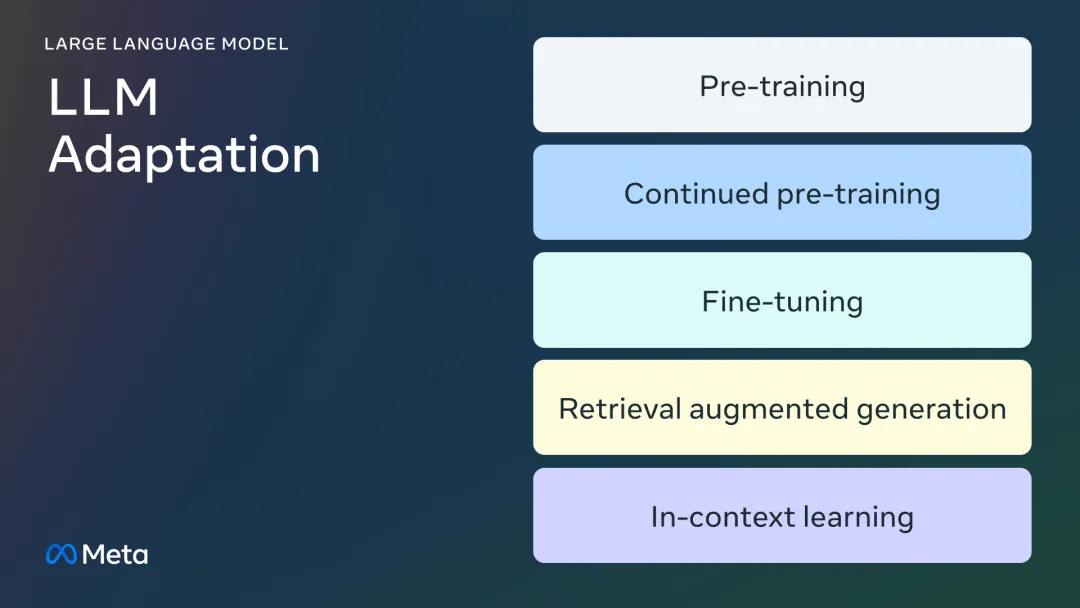
微调的所有门道,都在这里了。

随着LLM不断迭代,偏好和评估数据中大量的人工标注逐渐成为模型扩展的显著障碍之一。Meta FAIR的团队最近提出了一种使用迭代式方法「自学成才」的评估模型训练方法,让70B参数的Llama-3-Instruct模型分数超过了Llama 3.1-405B。

本文引入了 Transfusion,这是一种可以在离散和连续数据上训练多模态模型的方法。

就在刚刚,Meta最新发布的Transfusion,能够训练生成文本和图像的统一模型了!完美融合Transformer和扩散领域之后,语言模型和图像大一统,又近了一步。也就是说,真正的多模态AI模型,可能很快就要来了!

人自信的时候,说话都会变得坦率很多。

一键下载最大的视频分割数据集
AI产品整体流量合计超过50亿,环比降低7.87%,Chat助手类产品流量占据57.74%。

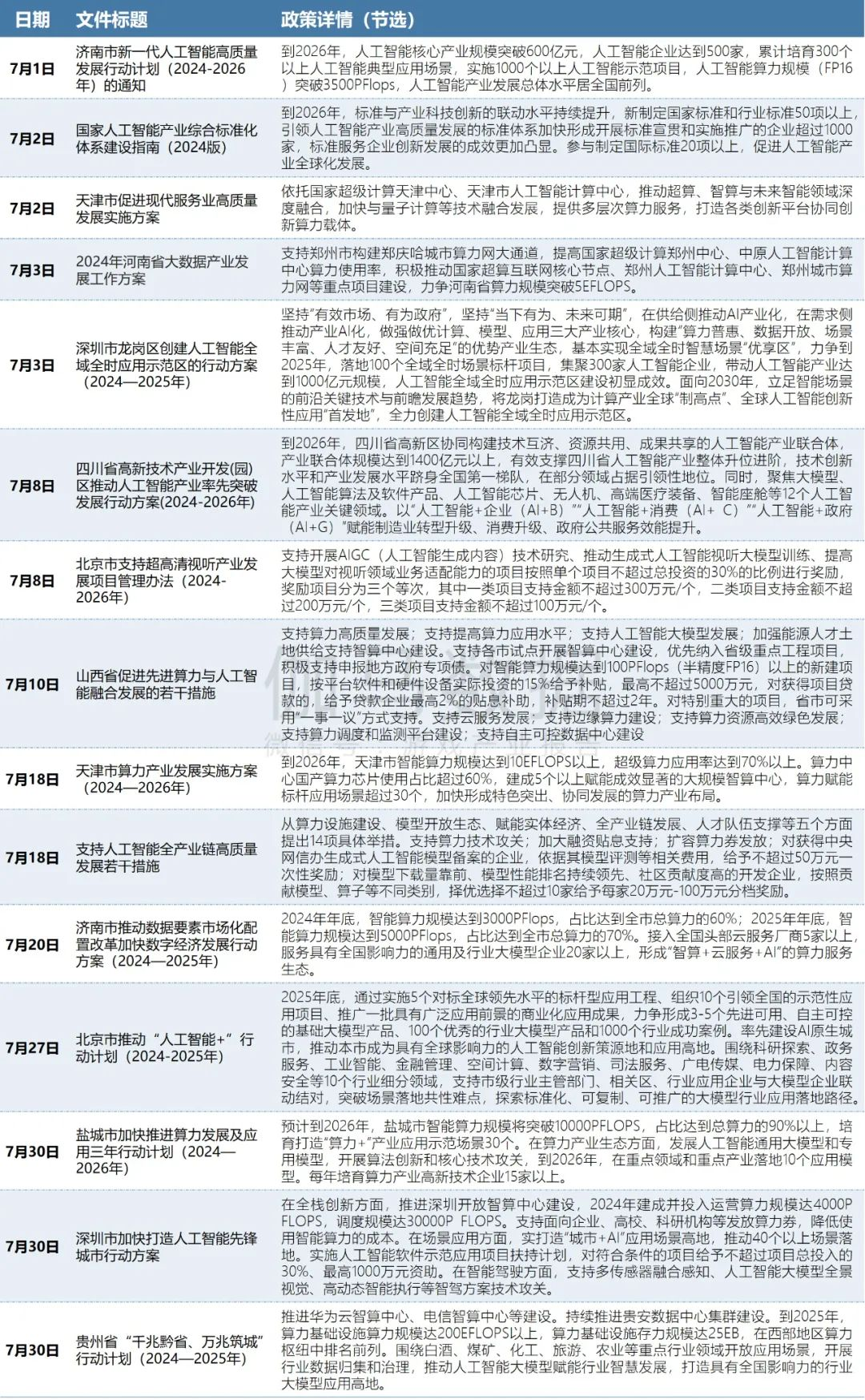
Meta加强推广Llama模型,谋求AI市场领导