
仅用250美元,Hugging Face技术主管手把手教你微调Llama 3
仅用250美元,Hugging Face技术主管手把手教你微调Llama 3我们知道,Meta 推出的 Llama 3、Mistral AI 推出的 Mistral 和 Mixtral 模型以及 AI21 实验室推出的 Jamba 等开源大语言模型已经成为 OpenAI 的竞争对手。
来自主题: AI技术研报
11930 点击 2024-05-06 17:49
 搜索
搜索
我们知道,Meta 推出的 Llama 3、Mistral AI 推出的 Mistral 和 Mixtral 模型以及 AI21 实验室推出的 Jamba 等开源大语言模型已经成为 OpenAI 的竞争对手。

对于小型语言模型(SLM)来说,数学应用题求解是一项很复杂的任务。

开源最近成了 AI 圈绕不开的高频热门词汇。 先有 Mistral 8x22B 闷声干大事,后有 Meta Llama 3 模型深夜炸场,现在连苹果也要下场参加这场激烈的开源争霸赛。

开源最近成了 AI 圈绕不开的高频热门词汇。
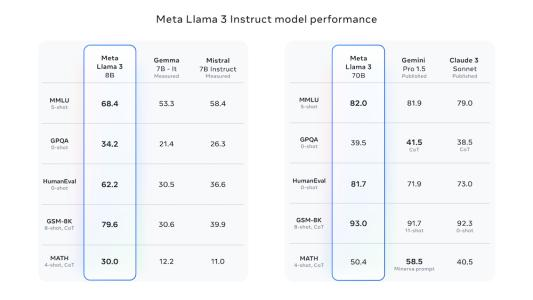
智东西4月19日消息,Meta推出迄今为止能力最强的开源大模型Llama 3系列,发布8B和70B两个版本。 Llama 3在一众榜单中取得开源SOTA(当前最优效果)。Llama 3 8B在MMLU、GPQA、HumanEval、GSM-8K等多项基准上超过谷歌Gemma 7B和Mistral 7B Instruct。

太平洋时间4月9日,谷歌、OpenAl、Mistral在24小时内,接连发布大模型重磅更新。
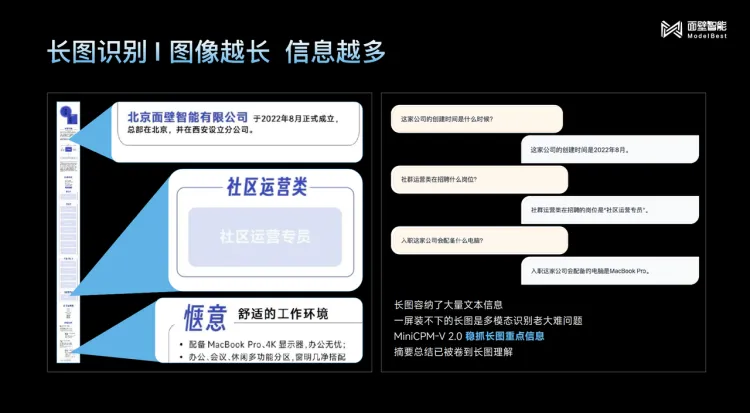
时隔七十多天,面壁在发布了MiniCPM-2B后又带来四个特性鲜明的模型,同时它还官宣了数亿元的新融资。
一条磁力链,Mistral AI又来闷声不响搞事情。
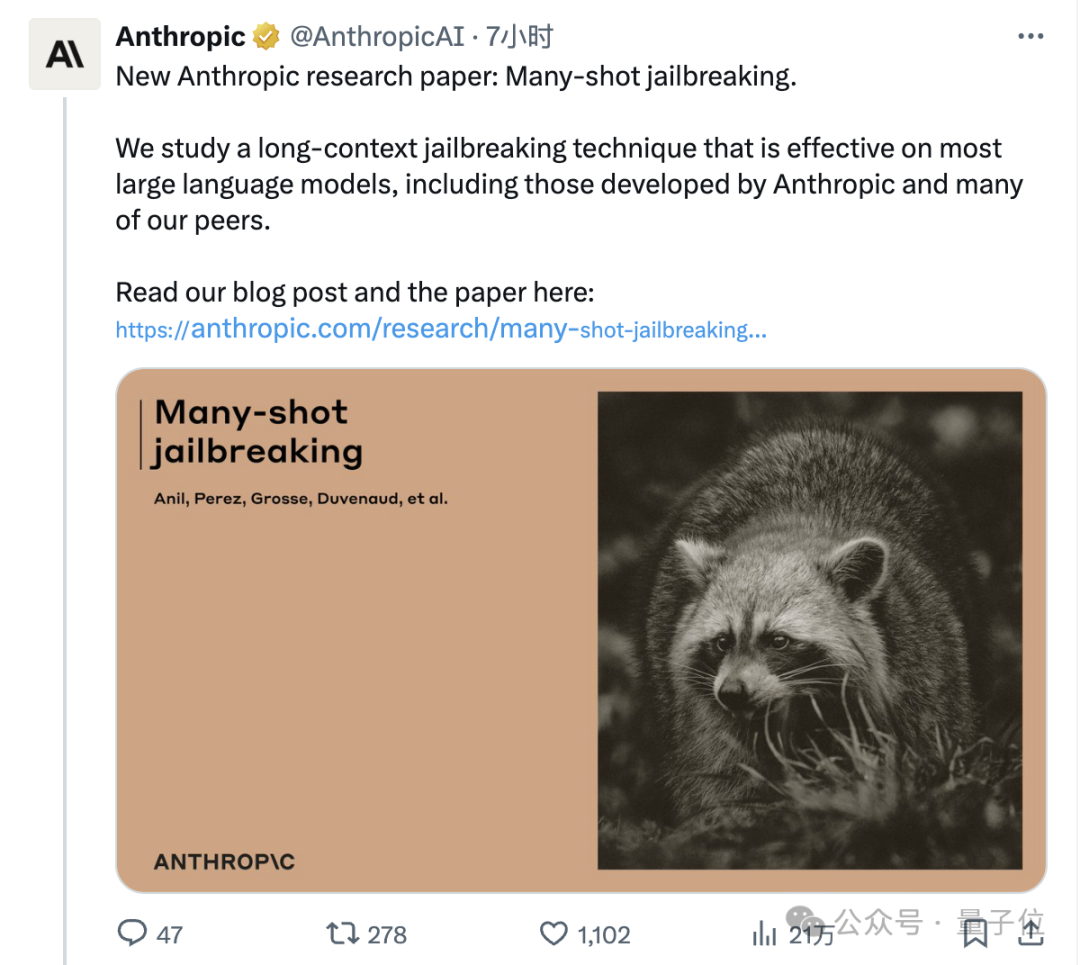
大模型厂商在上下文长度上卷的不可开交之际,一项最新研究泼来了一盆冷水——Claude背后厂商Anthropic发现,随着窗口长度的不断增加,大模型的“越狱”现象开始死灰复燃。无论是闭源的GPT-4和Claude 2,还是开源的Llama2和Mistral,都未能幸免。

作为 Meta 的前 CTO,Quora CEO Adam D'Angelo 目前还是 OpenAI 的董事会成员,在 Quora 之外推出的 Poe,成为当下接入大模型最多的 Chatbot 平台:GPT-4、Claude3、Mistral 等模型都有,用户也可以在上面搭建自己的 Chatbot 机器人,如果有别的用户使用,还可以产生收益。