
我为马斯克扮演机器人!擎天柱背后竟是最贵「演员团」
我为马斯克扮演机器人!擎天柱背后竟是最贵「演员团」擎天柱靓丽演示背后,是近百号员工每日8小时,疯狂重复固定动作,擦桌子、扮大猩猩等,他们正用体力「喂饱」擎天柱。
来自主题: AI资讯
11620 点击 2025-11-04 11:34
 搜索
搜索
擎天柱靓丽演示背后,是近百号员工每日8小时,疯狂重复固定动作,擦桌子、扮大猩猩等,他们正用体力「喂饱」擎天柱。

最新最强的开源原生多模态世界模型—— 北京智源人工智能研究院(BAAI)的悟界·Emu3.5来炸场了。 图、文、视频任务一网打尽,不仅能画图改图,还能生成图文教程,视频任务更是增加了物理真实性。

AI已经不止会写代码、画图、做PPT,它也开始「上班」了!CMU与斯坦福的研究团队首次完整追踪了AI的工作过程,发现一个惊人事实:它并不是在模仿人类,而是在用编程的方式重写工作的定义。这场关于「谁在工作」的实验,正在重构未来职场的逻辑。

今天,北京智源人工智能研究院(BAAI)重磅发布了其多模态系列模型的最新力作 —— 悟界・Emu3.5。这不仅仅是一次常规的模型迭代,Emu3.5 被定义为一个 “多模态世界大模型”(Multimodal World Foudation Model)。
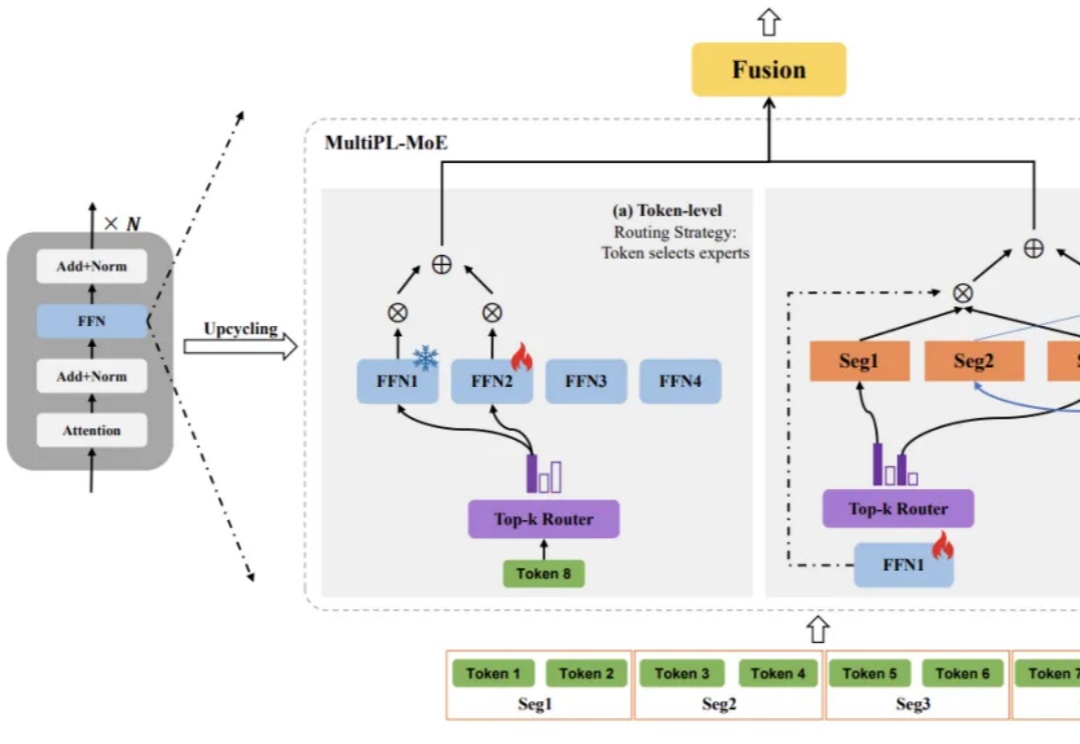
大语言模型(LLM)虽已展现出卓越的代码生成潜力,却依然面临着一道艰巨的挑战:如何在有限的计算资源约束下,同步提升对多种编程语言的理解与生成能力,同时不损害其在主流语言上的性能?

微软 AI 首席执行官穆斯塔法·苏莱曼(Mustafa Suleyman)正试图走一条微妙的路线。
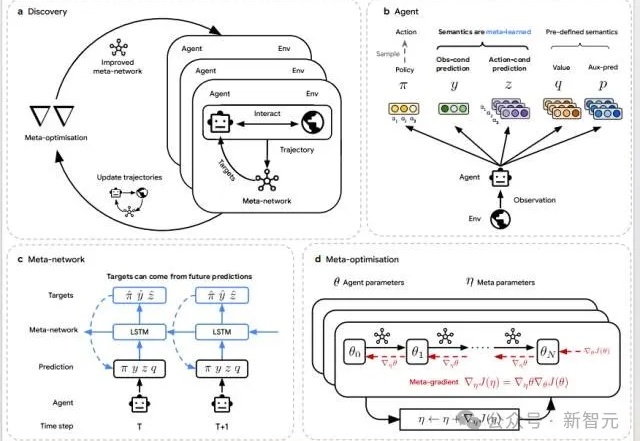
当AI开始「自己学会学习」,人类的角色正在被重写。DeepMind最新研究DiscoRL,让智能体在多环境交互中自主发现强化学习规则——无需人类设计算法。它在Atari基准中击败MuZero,在从未见过的游戏中依旧稳定高效。

彭超曾在华为印度、阿里任消费硬件业务1号位;联合创始人齐炜祯为Multi-token架构开创学者,被Deepseek、Qwen引入预训练方法。
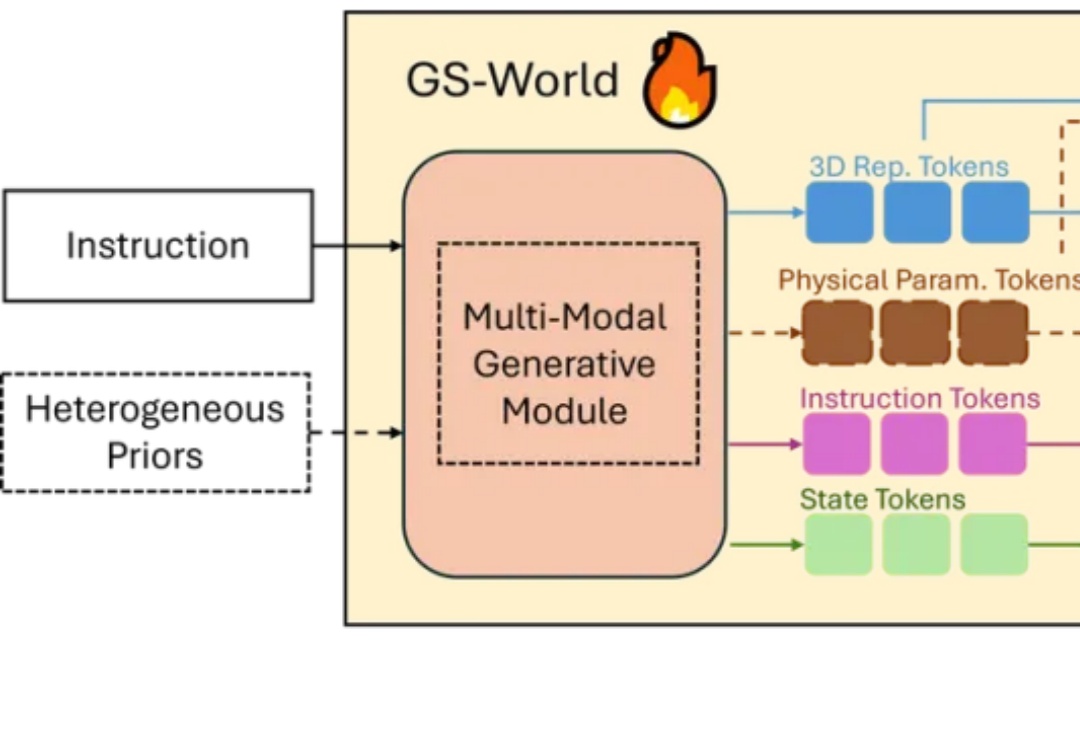
2025 年秋的具身智能赛道正被巨头动态点燃:特斯拉上海超级工厂宣布 Optimus 2.0 量产下线,同步开放开发者平台提供运动控制与环境感知 SDK,试图通过生态共建破解数据孤岛难题;英伟达则在 SIGGRAPH 大会抛出物理 AI 全栈方案,其 Omniverse 平台结合 Cosmos 世界模型可生成高质量合成数据,直指真机数据短缺痛点。
在 AI 时代,最赚钱的可能不是那些会写代码的人,而是那些能把专业经验「产品化」的人。大量专业人士手里握着宝贵的行业 know-how,却找不到一个合适的方式把它变成持续收入。直到我看到 MuleRun,才发现有人正在尝试打破这个困局——让不懂代码的专业人士,也能把自己的工作流变成可交易的「商品」。