一夜颠覆Sora神话,H200单卡5秒出片!全华人团队开源AI引爆视频圈
一夜颠覆Sora神话,H200单卡5秒出片!全华人团队开源AI引爆视频圈AI视频生成进入了秒生极速时代!UCSD等机构发布的FastWan系模型,在一张H200上,实现了5秒即生视频。稀疏蒸馏,让去噪时间大减,刷新SOTA。
来自主题: AI资讯
7988 点击 2025-08-07 17:55
 搜索
搜索
AI视频生成进入了秒生极速时代!UCSD等机构发布的FastWan系模型,在一张H200上,实现了5秒即生视频。稀疏蒸馏,让去噪时间大减,刷新SOTA。
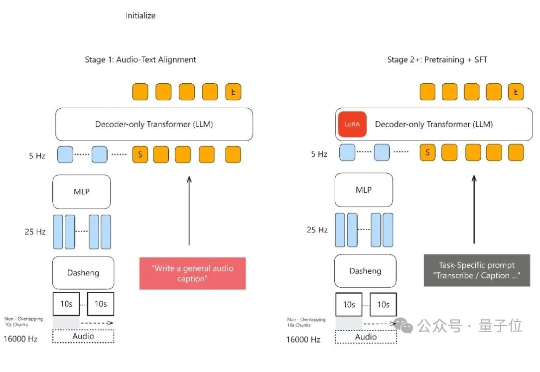
声音理解能力新SOTA,小米全量开源了模型。 MiDashengLM-7B,基于Xiaomi Dasheng作为音频编码器和Qwen2.5-Omni-7B Thinker作为自回归解码器,通过创新的通用音频描述训练策略,实现了对语音、环境声音和音乐的统一理解。

全球社交应用市场似乎正在迎来一波变革。

电影级视频生成模型来了。

基于Qwen2.5架构,采用DeepSeek-R1-0528生成数据,英伟达推出的OpenReasoning-Nemotron模型,以超强推理能力突破数学、科学、代码任务,在多个基准测试中创下新纪录!数学上,更是超越了o3!
近年来,随着扩散模型(Diffusion Models)和扩散 Transformer(DiT)在视频生成领域的广泛应用,AI 合成视频的质量和连贯性有了飞跃式提升。像 OpenAI Sora、HunyuanVideo、Wan2.1 等大模型,已经能够生成结构清晰、细节丰富且高度连贯的长视频内容,为数字内容创作、虚拟世界和多媒体娱乐带来了巨大变革。

智源统一图像生成模型OmniGen2发布后,立刻在AI图像生成领域掀起巨响,多模态技术生态进一步打通。才一周,GitHub星标就已经破了2000,X上的话题浏览数直接破数十万。

值得买科技发布了自己的 MCP Server “海纳”,在 AI Agent 时代打造消费领域的基础设施。值得买在数据提供与适配方面有着丰富经验,在电商消费行业有着深刻积累,正是因为有了在垂直领域深耕的行业 know how,所以才有能力向行业提供高质量的、场景相关的数据内容。

6 月 6 日,小红书 hi lab(Humane Intelligence Lab,人文智能实验室)团队首次开源了文本大模型 dots.llm1,采用 MIT 许可证。

此次开源的 Wan2.1-VACE-1.3B 支持 480P 分辨率,Wan2.1-VACE-14B 支持 480P 和 720P 分辨率。通过 VACE,用户可一站式完成文生视频、图像参考生成、局部编辑与视频扩展等多种任务,无需频繁切换模型或工具,真正实现高效、灵活的视频创作体验。