
文本已死,视觉当立!Karpathy狂赞DeepSeek新模型,终结分词器时代
文本已死,视觉当立!Karpathy狂赞DeepSeek新模型,终结分词器时代AI新突破!DeepSeek-OCR以像素处理文本,压缩率小于1/10,基准测试领跑。开源一夜4.4k星,Karpathy技痒难耐,展望视觉输入的通用性。
来自主题: AI技术研报
8041 点击 2025-10-21 16:48
 搜索
搜索
AI新突破!DeepSeek-OCR以像素处理文本,压缩率小于1/10,基准测试领跑。开源一夜4.4k星,Karpathy技痒难耐,展望视觉输入的通用性。

刚刚,DeepSeek 推出了全新的视觉文本压缩模型 DeepSeek-OCR。 该模型最大的突破在于极高的压缩效率: 20 个节点每天可处理 3300 万页数据,硬件要求仅为 A100-40G。
百度登顶全球第一!最新模型「PaddleOCR-VL」以0.9B参数量,在全球权威榜单OmniDocBench V1.5中以92.6分夺得综合性能第一,横扫文本识别、公式识别、表格理解与阅读顺序四项SOTA。

最近,美国多家 AI+医疗明星公司接连传来进展:OpenEvidence(医学知识搜索) 的 ARR 已突破 1000 万美元,每天有上万名医生付费使用;Abridge(临床文档转写) 完成 2.5 亿美元融资;Tempus AI(肿瘤学与精准医疗) 已在纳斯达克上市,市值一度超过 60 亿美元;Hippocratic AI(医疗专属大模型) 估值也已达数十亿美元。
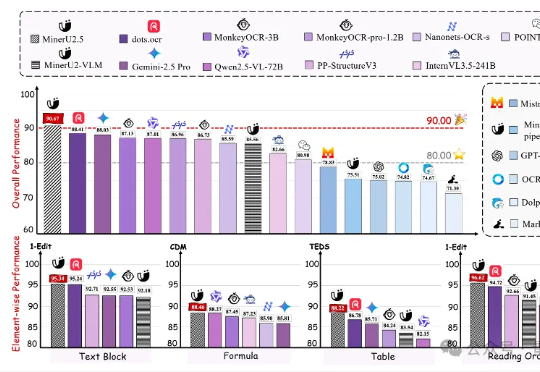
上海人工智能实验室发布新一代文档解析大模型——MinerU2.5。作为MinerU系列最新成果,该模型仅以1.2B参数规模,就在OmniDocBench、olmOCR-bench、Ocean-OCR等权威评测上,全面超越Gemini2.5-Pro、GPT-4o、Qwen2.5-VL-72B等主流通用大模型,以及dots.ocr、MonkeyOCR、PP-StructureV3等专业文档解析工具。
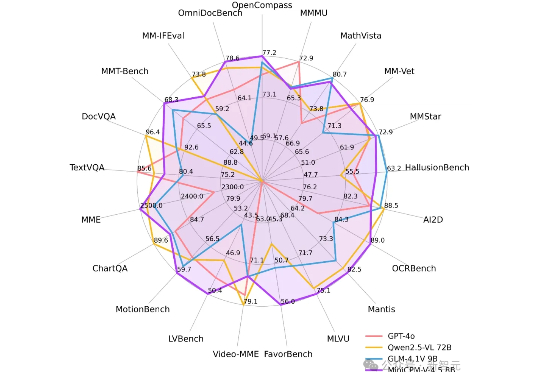
行业首个具备“高刷”视频理解能力的多模态模型MiniCPM-V 4.5的技术报告正式发布!报告提出统一的3D-Resampler架构实现高密度视频压缩、面向文档的统一OCR和知识学习范式、可控混合快速/深度思考的多模态强化学习三大技术。
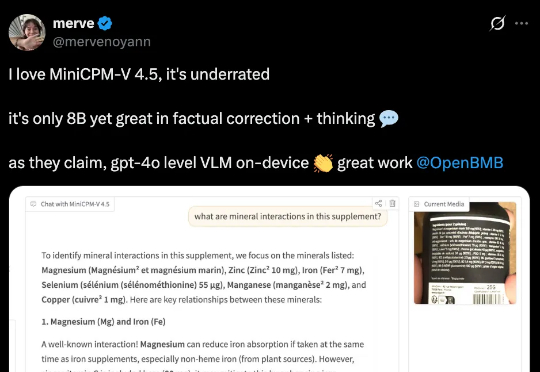
刚刚,面壁智能再放大招——MiniCPM-V 4.5多模态端侧模型横空出世:8B参数,越级反超72B巨无霸,图片、视频、OCR同级全线SOTA!不仅跑得快、看得清,还能真正落地到车机、机器人等。这一次,它不只是升级,而是刷新了端侧AI的高度。

今天,我们正式开源 8B 参数的面壁小钢炮 MiniCPM-V 4.5 多模态旗舰模型,成为行业首个具备“高刷”视频理解能力的多模态模型,看得准、看得快,看得长!高刷视频理解、长视频理解、OCR、文档解析能力同级 SOTA,且性能超过 Qwen2.5-VL 72B,堪称最强端侧多模态模型。

首个开源多模态Deep Research Agent来了。整合了网页浏览、图像搜索、代码解释器、内部 OCR 等多种工具,通过全自动流程生成高质量推理轨迹,并用冷启动微调和强化学习优化决策,使模型在任务中能自主选择合适的工具组合和推理路径。
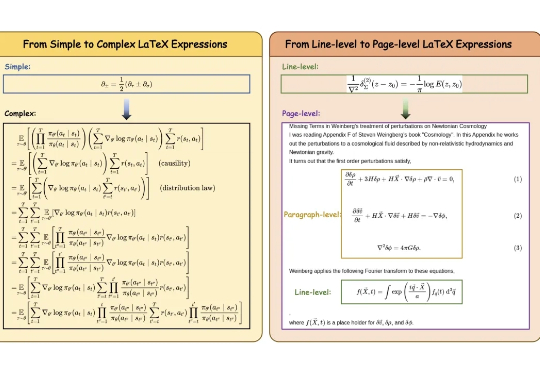
LaTeX 公式的光学字符识别(OCR)是科学文献数字化与智能处理的基础环节,尽管该领域取得了一定进展,现有方法在真实科学文献处理时仍面临诸多挑战: