
8张GPU训出近SOTA模型,超低成本图像生成预训练方案开源
8张GPU训出近SOTA模型,超低成本图像生成预训练方案开源超低成本图像生成预训练方案来了——仅需8张GPU训练,就能实现近SOTA的高质量图像生成效果。
来自主题: AI技术研报
10041 点击 2025-03-18 16:04
 搜索
搜索
超低成本图像生成预训练方案来了——仅需8张GPU训练,就能实现近SOTA的高质量图像生成效果。

角色扮演 AI(Role-Playing Language Agents,RPLAs)作为大语言模型(LLM)的重要应用,近年来获得了广泛关注。
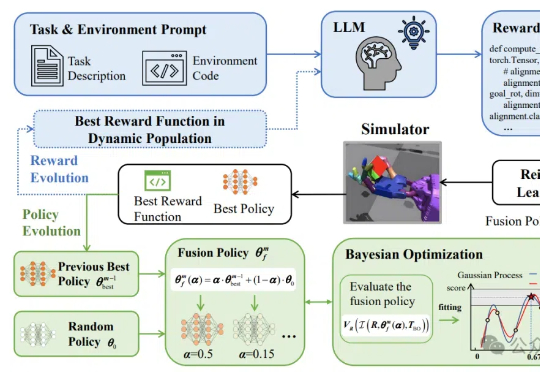
让机器人轻松学习复杂技能有新框架了!

今年,CVPR共有13008份有效投稿并进入评审流程,其中2878篇被录用,最终录用率为22.1%。
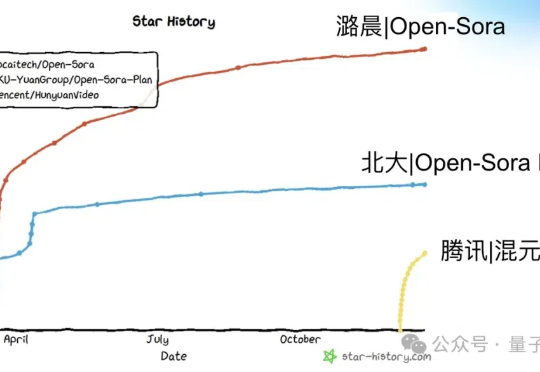
224张GPU,训出开源视频生成新SOTA!Open-Sora 2.0正式发布。 11B参数规模,性能可直追HunyuanVideo和Step-Video(30B)。
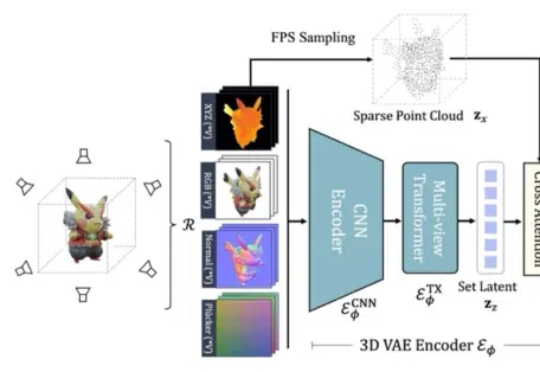
在 ICLR 2025 中,来自南洋理工大学 S-Lab、上海 AI Lab、北京大学以及香港大学的研究者提出的基于 Flow Matching 技术的全新 3D 生成框架 GaussianAnything,针对现有问题引入了一种交互式的点云结构化潜空间,实现了可扩展的、高质量的 3D 生成,并支持几何-纹理解耦生成与可控编辑能力。

TimeDistill通过知识蒸馏,将复杂模型(如Transformer和CNN)的预测能力迁移到轻量级的MLP模型中,专注于提取多尺度和多周期模式,显著提升MLP的预测精度,同时保持高效计算能力,为时序预测提供了一种高效且精准的解决方案。
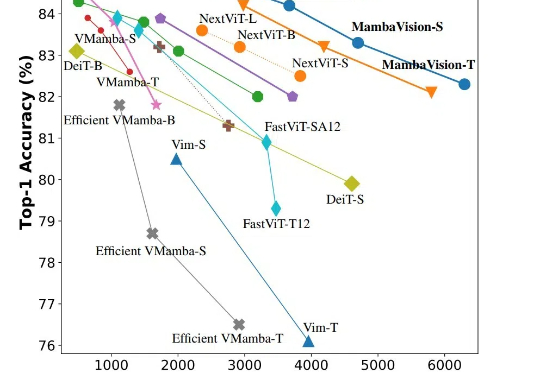
CVPR 2025,混合新架构MambaVision来了!Mamba+Transformer混合架构专门为CV应用设计。MambaVision 在Top-1精度和图像吞吐量方面实现了新的SOTA,显著超越了基于Transformer和Mamba的模型。

智源联手多所顶尖高校发布的多模态向量模型BGE-VL,重塑了AI检索领域的游戏规则。它凭借独创的MegaPairs合成数据技术,在图文检索、组合图像检索等多项任务中,横扫各大基准刷新SOTA。

DeepSeek R1 催化了 reasoning model 的竞争:在过去的一个月里,头部 AI labs 已经发布了三个 SOTA reasoning models:OpenAI 的 o3-mini 和deep research, xAI 的 Grok 3 和 Anthropic 的 Claude 3.7 Sonnet。