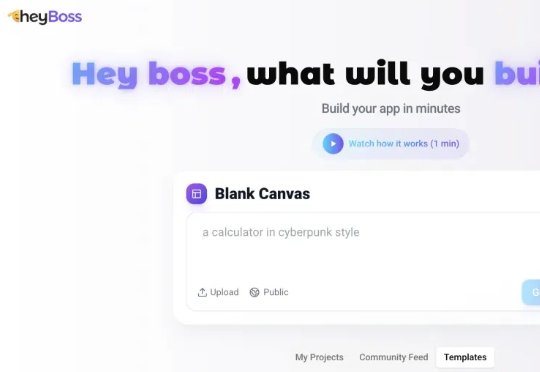
斯坦福女神辍学再创业,获OpenAI力挺!全球首个0代码AI工程师出世
斯坦福女神辍学再创业,获OpenAI力挺!全球首个0代码AI工程师出世世界首个不用编码AI工程师Heyboss横空出世!一句话创建超级应用,99%人也能当程序员。最近,初创Heyboss AI官宣了AI非编码工具Heyboss,专为代码小白量身打造。
来自主题: AI资讯
10437 点击 2025-01-29 13:40
 搜索
搜索
世界首个不用编码AI工程师Heyboss横空出世!一句话创建超级应用,99%人也能当程序员。最近,初创Heyboss AI官宣了AI非编码工具Heyboss,专为代码小白量身打造。
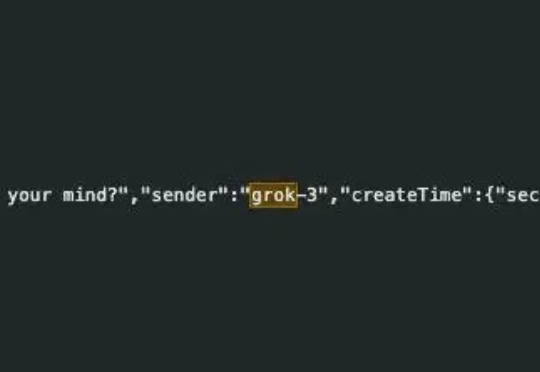
科技媒体 testingcatalog 今天(1 月 27 日)发布博文,报道称 xAI 官方虽然尚未公布,但 Grok-3 已短暂现身独立平台和 X 平台,开启内部测试,有望下周正式发布。

实际上 Operator 只是最近一段时间,全球大模型公司智能体集中发布浪潮的一部分。早于 Operator 发布前两天,字节跳动豆包大模型团队就已经公布了同类型智能体:UI-TARS。

在刚刚成立的一年多时间里,DeepSeek一直不声不响,V2模型的发布成为其破圈的关键。由于模型结构层面的突破性创新,使得其将模型成本大大降低,也被业内戏称为AI届拼多多。这之后,DeepSeek也真正引发了硅谷的恐慌,OpenAI正迎来一个最强劲的对手。

在达沃斯世界经济论坛上,OpenAI 首席财务官 Sarah Friar 抛出了这颗重磅炸弹,“它们会像真正的同事一样思考问题,遇到困难会后退一步思考,尝试新的解决方案。这不再是科幻,而是即将在 2025 年实现的现实。”
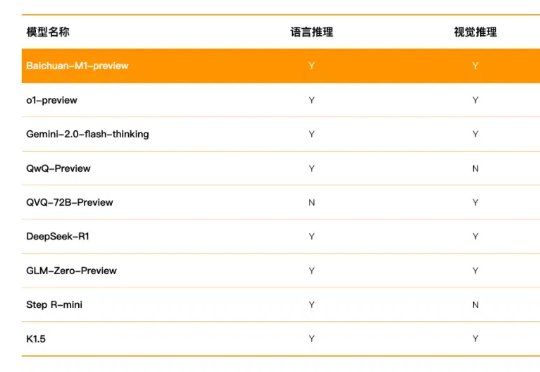
就在本周,Kimi 的新模型打开了强化学习 Scaling 新范式,DeepSeek R1 用开源的方式「接班了 OpenAI」,谷歌则把 Gemini 2.0 Flash Thinking 的上下文长度延伸到了 1M。1 月 24 日上午,百川智能重磅发布了国内首个全场景深度思考模型,把这一轮军备竞赛推向了高潮。
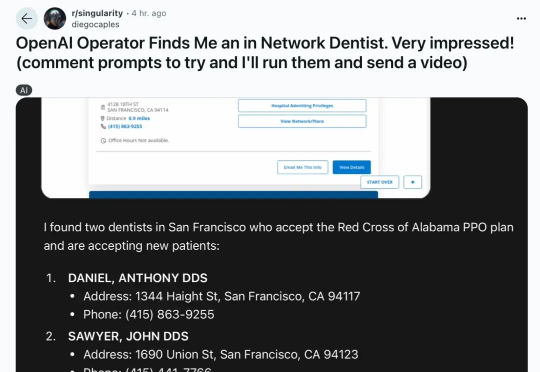
要花1450元才能玩到Operator,让本来满满期待的大伙,一下难受住了。而交了钱的各位,开始兴奋的晒出各种测试结果。有网友分享,Operator通过浏览网页在3分钟之内帮打找到了附近牙医诊所,回报了地址和电话。

「星际之门」更多内幕被曝光了!据称,首期投入1000亿美金,将在德州阿比林建设10座数据中心,未来要在全美打造20个超算。与此同时,奥特曼秀出了首期工厂的全景,无比震撼。
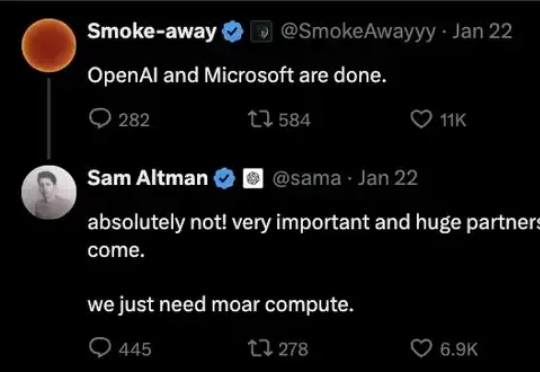
一个5000亿美元的大动作,让微软不再是OpenAI独家云计算供应商了。

OpenAI的新Scaling Law,含金量又提高了。