
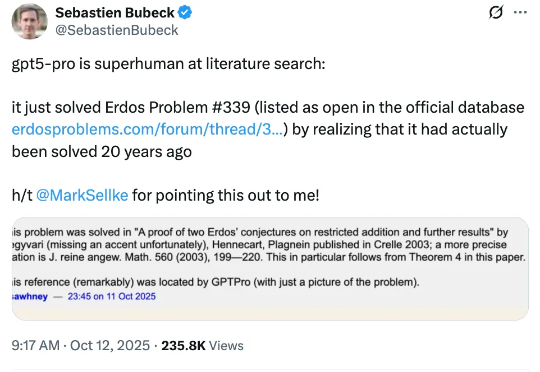
人类遗忘的难题解法,被GPT-5重新找出来了
人类遗忘的难题解法,被GPT-5重新找出来了人类遗忘的难题解法,被GPT-5 Pro重新找出来了!这事儿聚焦于埃尔德什问题#339,这是著名数学家保罗・埃尔德什提出或转述的近千道问题之一,收录于erdosproblems.com网站。该网站记录了每道题目的当前状态,其中约三分之一已解决,大部分仍待解。
来自主题: AI资讯
7110 点击 2025-10-14 13:17
人类遗忘的难题解法,被GPT-5 Pro重新找出来了!这事儿聚焦于埃尔德什问题#339,这是著名数学家保罗・埃尔德什提出或转述的近千道问题之一,收录于erdosproblems.com网站。该网站记录了每道题目的当前状态,其中约三分之一已解决,大部分仍待解。

OpenAI终于官宣了!联手芯片巨头博通下场造AI芯片,预计2029年底部署10GW算力。内部已秘密研发18个月,首颗芯片9个月后量产,AI领域的M1时刻将至。

人工智能真是日新月异。早上看到网友的评论:我们已经 0 天没有吸引注意的 AI 领域新突破了。记得三个月前,OpenAI 官宣了他们的推理模型在国际数学奥林匹克(IMO)竞赛中获得了金牌。
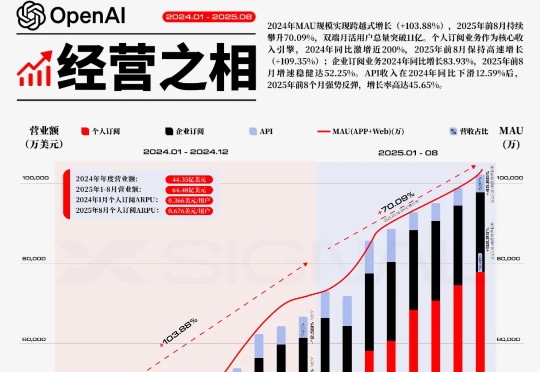
2022年11月,OpenAI的ChatGPT问世,这一事件不仅是技术创新的里程碑,更被视为重塑全球AI战略版图的关键转折点,它标志着新一轮大国AI竞赛的序幕被正式拉开。在此背景下,其增长的规模与速度本身,就是一种颠覆性的战略壁垒。
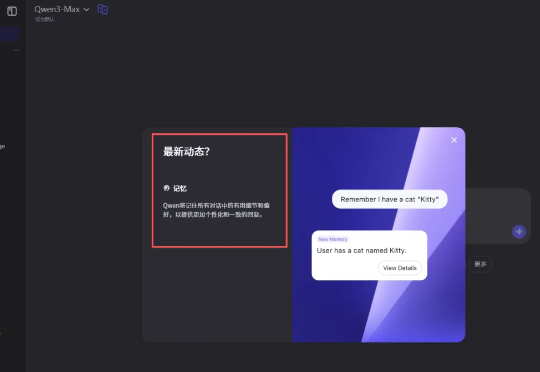
近期,我们独家观察到,国内两家科技巨头——阿里巴巴和字节跳动——旗下的AI助手通义千问(Qwen)和豆包(Doubao),同时开始内测“记忆功能”。此举被广泛视为对标行业领头羊OpenAI的ChatGPT,标志着国产AI助手正从“即时问答工具”向“长期私人助理”的角色加速演进。

这是《窄播Weekly》的第68期,本期我们关注的商业动态是:OpenAI在今年的DevDay上更清晰地向我们展示了如何构建一个AI时代的超级系统。就像OpenAI的CEO山姆·奥特曼在一档播客节目中所说,ChatGPT上线之后经历了两个关键的「惊喜」时刻,
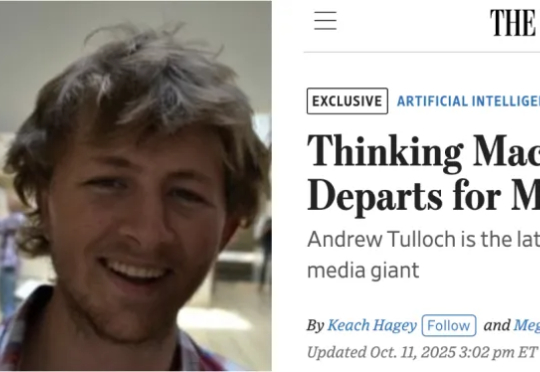
那个拒绝了小扎15亿美元薪酬包的机器学习大神,还是加入Meta了。OpenAI前CTO Mira Murati创业公司Thinking Machines Lab证实,联创、首席架构师Andrew Tulloch已经离职去了Meta。
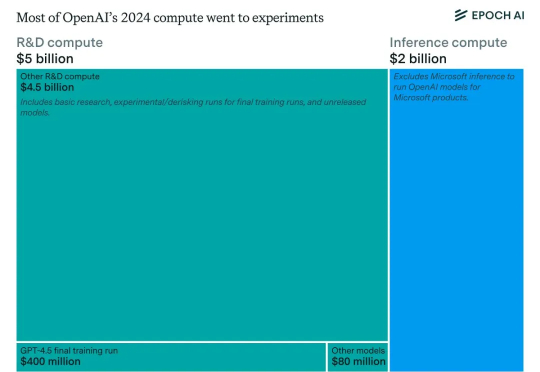
来扒一扒OpenAI算力支出的天价账单——据Epoch AI统计的数据显示,去年OpenAI在计算资源上支出了70亿美元。由于公司当时还没有大量的算力,所以这笔天价账单基本都是以向微软租用云算力的形式支付出去的,并不包括对数据中心的前期投入。
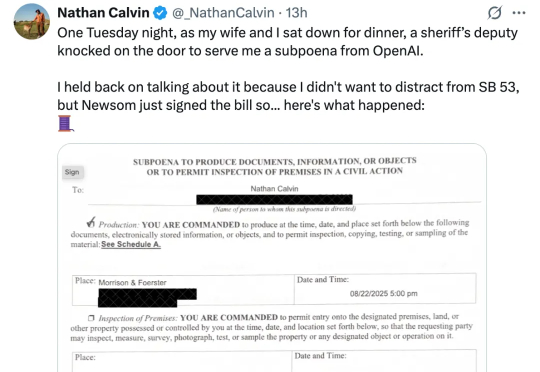
几个小时前,一位名为 Nathan Calvin 的 X 网友发推文称,「一个周二晚上,我和妻子正准备吃晚饭,一位副警长敲门,递给了我一张 OpenAI 的传票」。该传票不仅涉及他所在的 Encode 组织,还要求 Calvin 提供与加州立法者、大学生和前 OpenAI 员工的私人信息。而这一切都与一项近期通过的名为 SB 53 的法案有关。

“事实证明,不焦虑的人做不好 AI 应用。” 文丨程曼祺 “明年可能是 to C 应用的元年。”9 月 28 日,Lovart 创始人陈冕告诉我们。 第二天,“元年” 被加速——OpenAI 发布 S