
开源免费!推荐一款基于DeepSeek大模型RAG知识库与知识图谱平台,打通飞书、企业微信、钉钉
开源免费!推荐一款基于DeepSeek大模型RAG知识库与知识图谱平台,打通飞书、企业微信、钉钉语析Yuxi-Know 是基于大模型RAG知识库与知识图谱技术构建的智能问答平台,支持多种知识库文件格式,如PDF、TXT、MD、Docx,支持将文件内容转换为向量存储,便于快速检索。
来自主题: AI技术研报
6830 点击 2026-02-02 13:23
 搜索
搜索
语析Yuxi-Know 是基于大模型RAG知识库与知识图谱技术构建的智能问答平台,支持多种知识库文件格式,如PDF、TXT、MD、Docx,支持将文件内容转换为向量存储,便于快速检索。

今年的达沃斯,没有一个论坛不讲AI的。

论文将汇总人类从出生到死亡每个神经元的活动情况。利用更完善的“分子记录带”(molecular ticker tape)技术,神经元每发出一个电脉冲,都会在其蛋白链上加上一段荧光分子。通过对这些蛋白链进行测序,可以获得神经元整个生命周期内神经活动的完整历史记录。同时对每个神经元的mRNA进行测序,可以确定它属于10.4万个神经元类型中的哪一种。

Anthropic让Claude独立经营小卖部,没想到全球顶尖的智能体,在实验中不仅免费送PS5和各种商品,连小卖部的AI「老板」也被一张伪造的PDF文件「骗」下了台。在人类面前,再顶级的大模型仍显得过于「天真」和「单纯」,很容易就被套路和操纵。

Claude最近推出了一个令人兴奋的特性——Skills系统。它让AI Agent能够动态加载专业能力,按需”学习”处理PDF、Excel、PPT等专业文档的技能。作为一个开源爱好者,我立刻意识到这个设计的价值,并在Minion框架中实现了完整的开源版本。本文将介绍Skills的设计理念,以及我的开源实现细节。
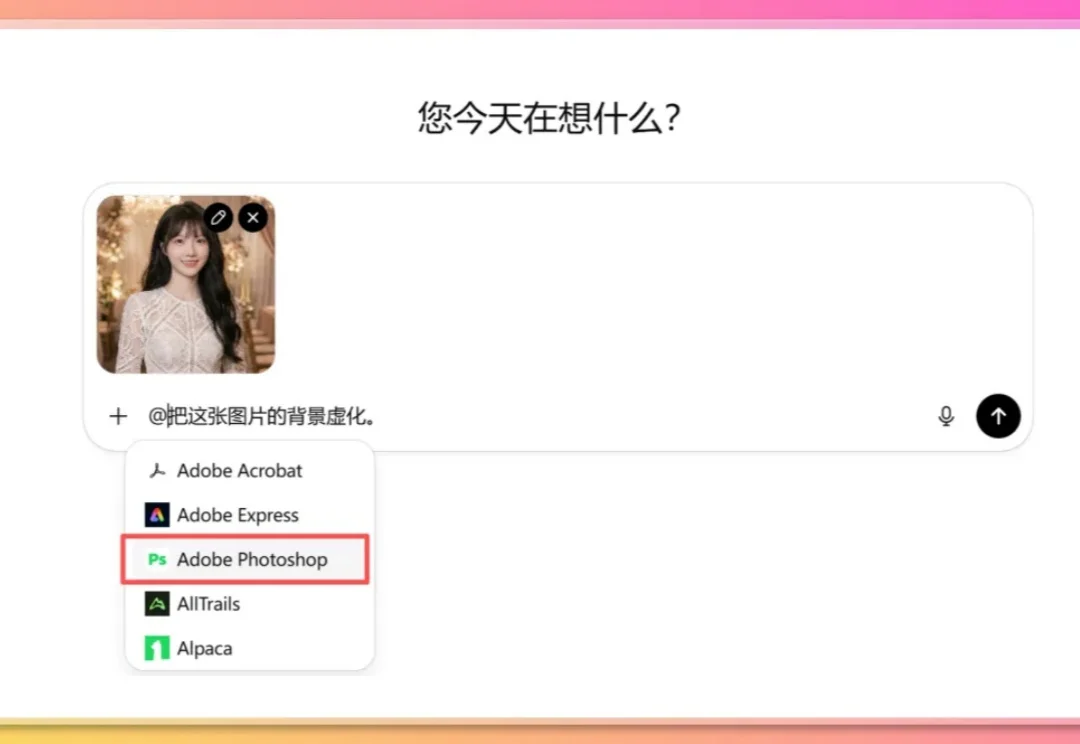
ChatGPT内上线 Photoshop、Express与Acrobat原生集成,用户可在对话界面直接调用三大创意工具完成修图、设计和PDF处理,无需跳转外部应用。

如果你曾将收据照片上传至报销系统,或在线阅读过PDF 格式的书籍,那么你可能已经使用过光学字符识别技术 ——这项已有数十年历史的技术能将打印体、手写体或印刷体文本图像转换为计算机可编辑的文本。

刚刚,Claude 发布了一个重磅更新:可以直接生成Excel和PPT了! 现在,Claude可以直接创建和编辑各种文件: Excel表格、Word文档、PPT幻灯片、PDF文件,通通不在话下。
EverWorker的主打产品Everflow是一款致力于优化全球用工管理的数字化平台。该平台搭载先进的上下文学习与矢量记忆系统,可吸收 PDF、截图、链接、聊天记录等内容,理解你的业务流程、语言习惯与组织文化。AI Worker能在执行任务前全面理解背景,确保每一次回应都高度贴合业务需求,就像你团队中的一员。

数据智能体到底好不好用?测评一下就知道了!