新版DeepSeek R1你得这样用,太爽啦~
新版DeepSeek R1你得这样用,太爽啦~哈喽,大家好,我是袋鼠帝 昨天下午下班后,DeepSeek R1更新了 然而他们就只是悄悄在微信群里面发布了这个消息。
来自主题: AI资讯
9488 点击 2025-05-29 11:50
 搜索
搜索
哈喽,大家好,我是袋鼠帝 昨天下午下班后,DeepSeek R1更新了 然而他们就只是悄悄在微信群里面发布了这个消息。
新版DeepSeek-R1重磅开源,凌晨已放出权重!此次模型性能几乎与o4-mini(Medium)相当,编程实测超越Claude 4 Sonnet。网友纷纷惊叹:开源又一次胜利了。

近半年来,OpenAI 形象开始变得灰暗: 团队骨干相继离职引发猜疑、组织转型遭受口诛笔伐、GPT-4.5/Sora 等模型表现不及预期,还有被 DeepSeek R1 打破的叙事神话……
今天,我们正式发布 DeepSeek-R1,并同步开源模型权重。DeepSeek-R1 遵循 MIT License,允许用户通过蒸馏技术借助 R1 训练其他模型。DeepSeek-R1 上线API,对用户开放思维链输出,通过设置 `model='deepseek-reasoner'` 即可调用。

只用5%的参数,数学和代码能力竟然超越满血DeepSeek?
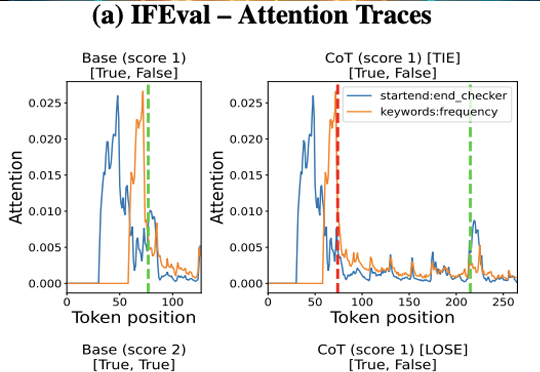
DeepSeek-R1火了,推理模型火了,思维链(Chain-of-Thought,CoT)火了!

在今年,DeepSeek R1火了之后。
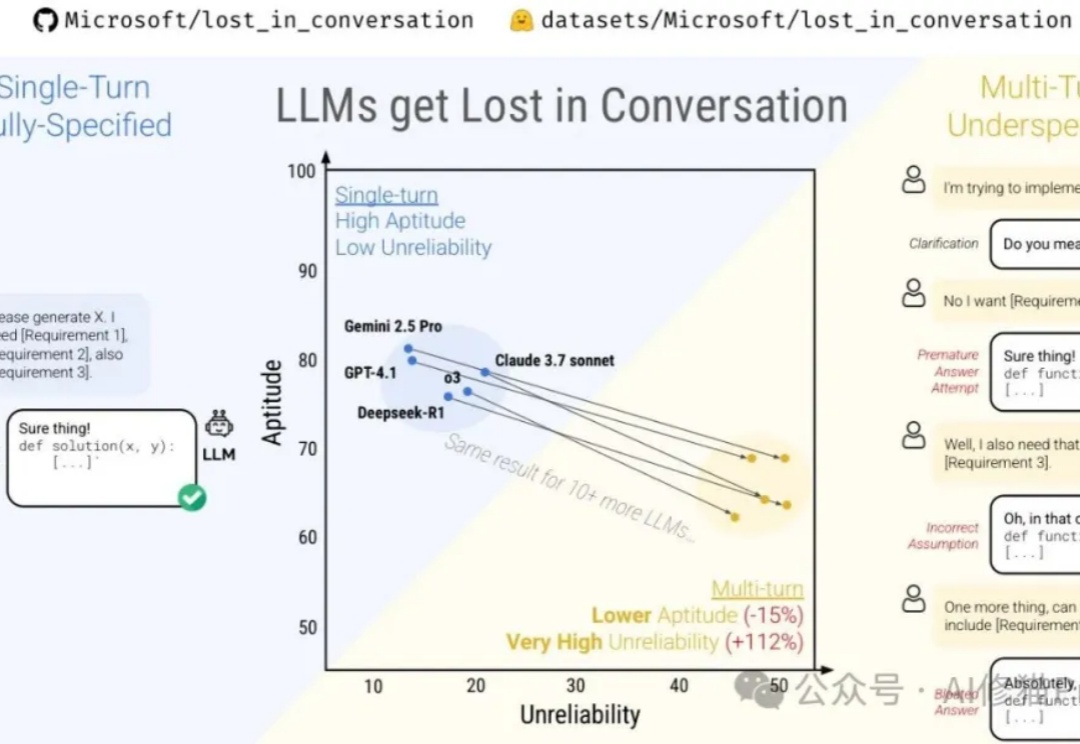
微软最近与Salesforce Research联合发布了一篇名为《Lost in Conversation》的研究,说当前最先进的LLM在多轮对话中表现会大幅下降,平均降幅高达39%。这一现象被称为对话中的"迷失"。文章分析了各大模型(包括Claude 3.7-Sonnet、Deepseek-R1等)在多轮对话中的表现差异,还解析了模型"迷失"的根本原因及有效缓解策略。

英伟达官宣新办公室落户中国台湾省台北市,但居然是从太空飞下来的吗?
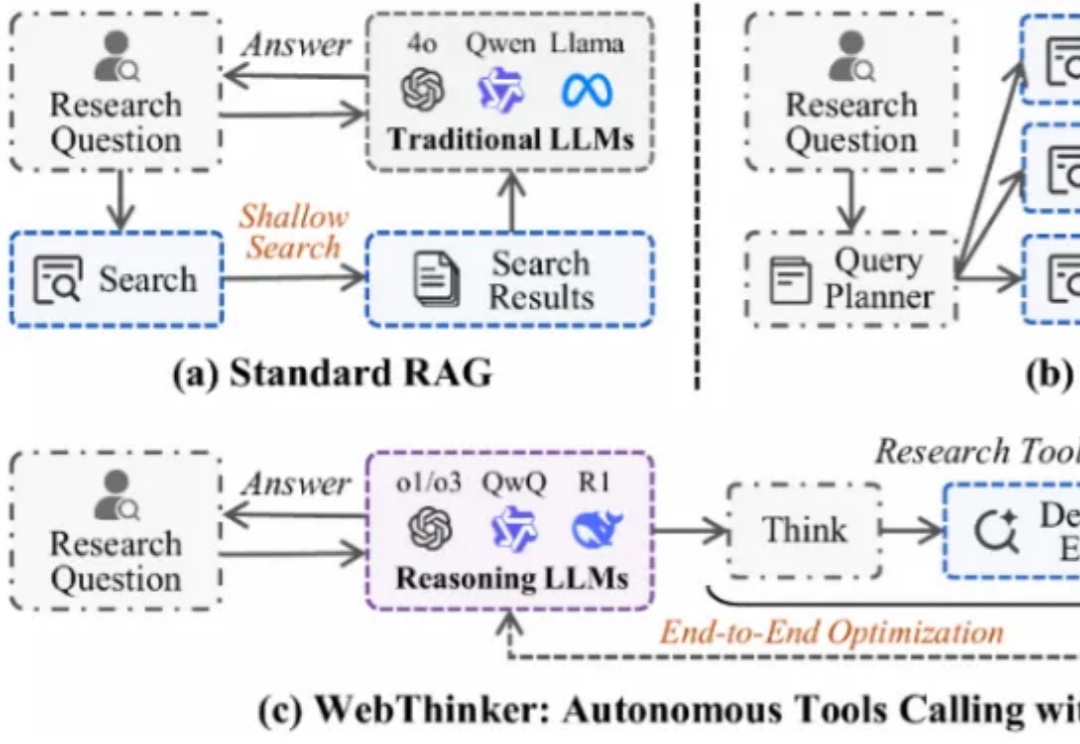
大型推理模型(如 OpenAI-o1、DeepSeek-R1)展现了强大的推理能力,但其静态知识限制了在复杂知识密集型任务及全面报告生成中的表现。为应对此挑战,深度研究智能体 WebThinker 赋予 LRM 在推理中自主搜索网络、导航网页及撰写报告的能力。