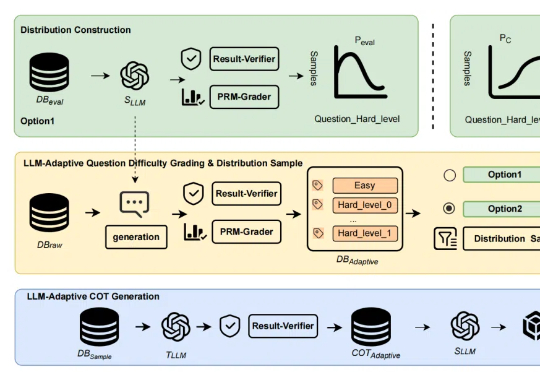
大模型推理上限再突破:「自适应难易度蒸馏」超越R1蒸馏,长CoT语料质量飞升
大模型推理上限再突破:「自适应难易度蒸馏」超越R1蒸馏,长CoT语料质量飞升近年来,「思维链(Chain of Thought,CoT)」成为大模型推理的显学,但要让小模型也拥有长链推理能力却非易事。
来自主题: AI技术研报
9142 点击 2025-05-04 17:08
 搜索
搜索
近年来,「思维链(Chain of Thought,CoT)」成为大模型推理的显学,但要让小模型也拥有长链推理能力却非易事。

近日,阿里云通义点金团队与苏州大学携手合作,在金融大语言模型领域推出了突破性的创新成果:DianJin-R1。

超越YOLOv3、Faster-RCNN,首个在COCO2017 val set上突破30AP的纯多模态开源LLM来啦!
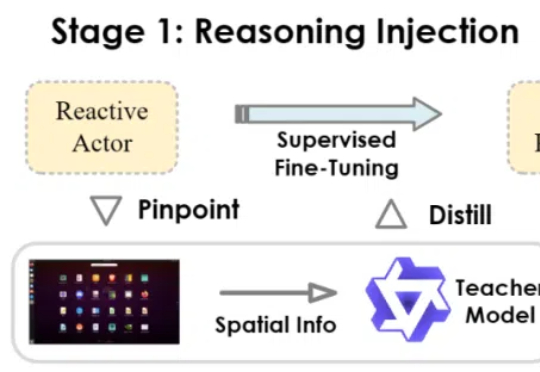
当前,多模态大模型驱动的图形用户界面(GUI)智能体在自动化手机、电脑操作方面展现出巨大潜力。然而,一些现有智能体更类似于「反应式行动者」(Reactive Actors),主要依赖隐式推理,面对需要复杂规划和错误恢复的任务时常常力不从心。

阿里Qwen3凌晨开源,正式登顶全球开源大模型王座!它的性能全面超越DeepSeek-R1和OpenAI o1,采用MoE架构,总参数235B,横扫各大基准。这次开源的Qwen3家族,8款混合推理模型全部开源,免费商用。
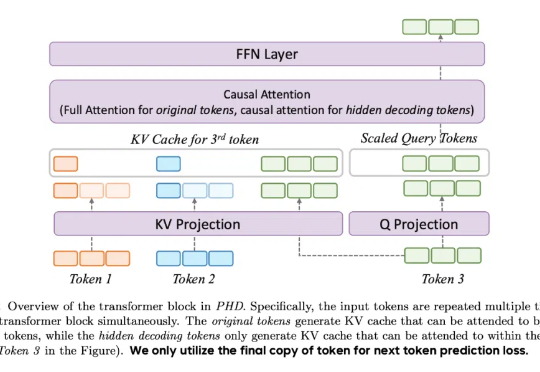
最近,DeepSeek-R1 和 OpenAI o1/03 等推理大模型在后训练阶段探索了长度扩展(length scaling),通过强化学习(比如 PPO、GPRO)训练模型生成很长的推理链(CoT),并在奥数等高难度推理任务上取得了显著的效果提升。
AIMO2冠军「答卷」公布了!英伟达团队NemoSkills拔得头筹,开源了OpenMath-Nemotron系列AI模型,1.5B小模型击败14B-DeepSeek「推理大模型」!
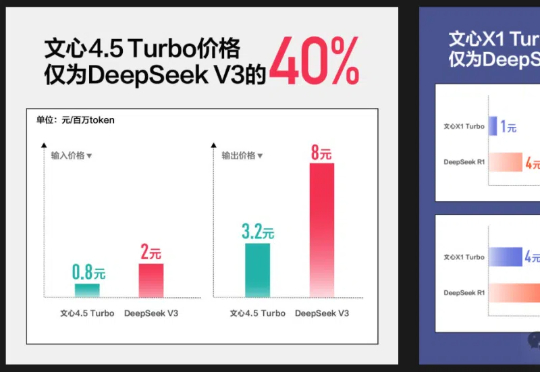
百度文心大模型X1 Turbo正式发布了。这个基于4.5 Turbo的深度思考模型,效果领先DeepSeek-R1、V3,且价格仅为R1的25%!而文心4.5 Turbo在低价的同时,多模态能力更是让人出乎意料。
OpenAI 的 o1 系列模型、Deepseek-R1 带起了推理模型的研究热潮,但这些推理模型大多关注数学、代码等专业领域。

什么开源算法自称为DeepSeek-R1(-Zero) 框架的第一个复现?