
推理模型其实无需「思考」?伯克利发现有时跳过思考过程会更快、更准确
推理模型其实无需「思考」?伯克利发现有时跳过思考过程会更快、更准确当 DeepSeek-R1、OpenAI o1 这样的大型推理模型还在通过增加推理时的计算量提升性能时,加州大学伯克利分校与艾伦人工智能研究所突然扔出了一颗深水炸弹:别再卷 token 了,无需显式思维链,推理模型也能实现高效且准确的推理。
来自主题: AI技术研报
9091 点击 2025-04-19 14:39
 搜索
搜索
当 DeepSeek-R1、OpenAI o1 这样的大型推理模型还在通过增加推理时的计算量提升性能时,加州大学伯克利分校与艾伦人工智能研究所突然扔出了一颗深水炸弹:别再卷 token 了,无需显式思维链,推理模型也能实现高效且准确的推理。

这是一份142页的研究论文,本文深入解析了大型推理模型DeepSeek-R1如何通过"思考"解决问题。研究揭示了模型思维的结构化过程,以及每个问题都存在甜蜜点"最佳推理区间"的惊人发现。这标志着"思维学"这一新兴领域的诞生,为我们理解和优化AI推理能力提供了宝贵框架。
GPT - 4o、Deepseek - R1 等高级模型已展现出令人惊叹的「深度思考」能力:理解上下文关联、拆解多步骤问题、甚至通过思维链(Chain - of - Thought)进行自我验证、自我反思等推理过程。

近年来,大模型(Large Language Models, LLMs)在数学、编程等复杂任务上取得突破,OpenAI-o1、DeepSeek-R1 等推理大模型(Reasoning Large Language Models,RLLMs)表现尤为亮眼。但它们为何如此强大呢?

港中文和清华团队推出Video-R1模型,首次将强化学习的R1范式应用于视频推理领域。通过升级的T-GRPO算法和混合图像视频数据集,Video-R1在视频空间推理测试中超越了GPT-4o,展现了强大的推理能力,并且全部代码和数据集均已开源。
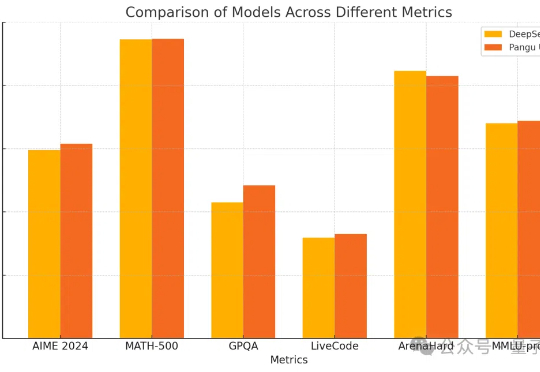
密集模型的推理能力也能和DeepSeek-R1掰手腕了?
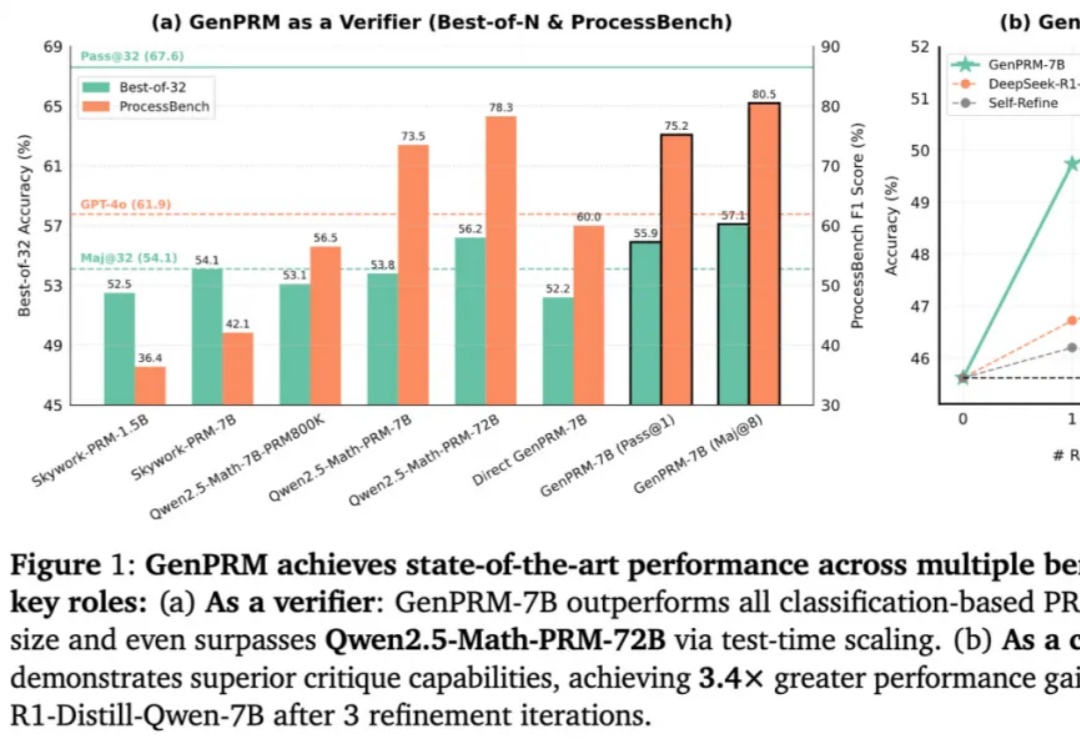
随着 OpenAI o1 和 DeepSeek R1 的爆火,大语言模型(LLM)的推理能力增强和测试时扩展(TTS)受到广泛关注。然而,在复杂推理问题中,如何精准评估模型每一步回答的质量,仍然是一个亟待解决的难题。传统的过程奖励模型(PRM)虽能验证推理步骤,但受限于标量评分机制,难以捕捉深层逻辑错误,且其判别式建模方式限制了测试时的拓展能力。

研究发现,推理模型(如DeepSeek-R1、o1)遇到「缺失前提」(MiP)的问题时,这些模型往往表现失常:回答长度激增、计算资源浪费。本文基于马里兰大学和利哈伊大学的最新研究,深入剖析推理模型在MiP问题上的「过度思考」现象,揭示其背后的行为模式,带你一窥当前AI推理能力的真实边界。
近年来,随着大型语言模型(LLMs)的快速发展,多模态理解领域取得了前所未有的进步。像 OpenAI、InternVL 和 Qwen-VL 系列这样的最先进的视觉-语言模型(VLMs),在处理复杂的视觉-文本任务时展现了卓越的能力。

AIMO2最终结果出炉了!英伟达团队NemoSkills拔得头筹,凭借14B小模型破解了34道奥数题,完胜DeepSeek R1。