LLM总是把简单任务复杂化,Karpathy无语:有些任务无需那么多思考
LLM总是把简单任务复杂化,Karpathy无语:有些任务无需那么多思考随着推理大模型和思维链的出现与普及,大模型具备了「深度思考」的能力,不同任务的泛用性得到了很大的提高。
来自主题: AI资讯
7976 点击 2025-08-12 15:58
 搜索
搜索
随着推理大模型和思维链的出现与普及,大模型具备了「深度思考」的能力,不同任务的泛用性得到了很大的提高。

取名大王 Karpathy。

在过去很长一段时间里,科技圈似乎人均都成了“提示词工程师”,大家都在琢磨怎么用最精妙的语言驯服AI。但包括Andrej Karpathy在内的很多行业大佬已经开始反思了,他们认为,决定AI效果的关键,可能早就不是怎么问,而是你给AI喂了什么料。这个思路,就是最近越来越火的上下文工程(Context Engineering)。

世界首个实时AI扩散视频模型炸场,Karpathy亲自站台,颠覆AI视频交互,0延迟+无限时长,每秒24帧不卡顿,MirageLSD首次实现AI直播级生成。

AI也要氛围阅读,Karpathy提出PDF论文已不适合AI时代,呼吁以Git、Markdown等结构化格式重塑科研写作。他认为未来99%的注意力将来自AI,科研成果应为AI优化。

最终体验 = 模型 + context (包括提示词、文件、代码库、业务数据,MCP服务等等一切喂给模型的东西),正好Andrej karpathy前几天天也整了个新提法叫Context engineering,这里可以碰瓷一下Andrej哈哈,这篇文章好几天前我发在小红书了

像细菌一样编写代码!创造出“氛围编程”、“软件3.0”的大神Karpathy又抛出一个新概念,引起网友广泛讨论——细菌编程(Bacterial code),要有三个特点:代码块小而精、模块化、自包含且易于复制粘贴。

Atharva博客揭示,AI是工程师能力的放大器。扎实的编程基础搭配精准提示,能让AI助你打造出极致产品。想知道如何用AI加速开发、少踩坑?快来看高手的秘诀!

继提示工程之后,「上下文工程」又红了!这一概念深得Karpathy等硅谷大佬的喜欢,堪称「全新的氛围编程」。而智能体成败的关键,不在于精湛的代码,而是上下文工程。
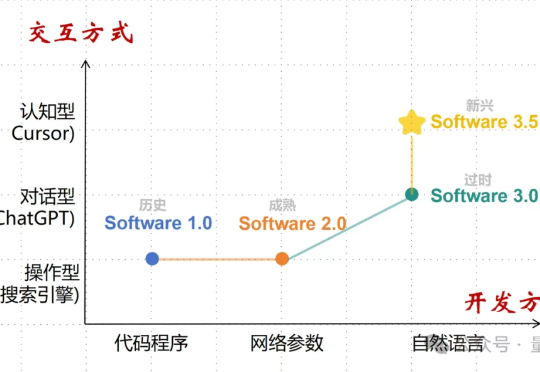
大神Karpathy提出“软件3.0”才两周,“软件3.5”已经诞生了?交互即智能。指AI不再是黑盒工具,而是透明的思维伙伴。用户可以在AI思考的任何节点进行干预,提供战略指导或纠正方向。