
训练数据爆减至1/1200!清华&生数发布国产视频具身基座模型,高效泛化复杂物理操作达SOTA水平
训练数据爆减至1/1200!清华&生数发布国产视频具身基座模型,高效泛化复杂物理操作达SOTA水平机器人能通过普通视频来学会实际物理操作了! 来看效果,对于所有没见过的物品,它能精准识别并按照指令完成动作。
来自主题: AI技术研报
8260 点击 2025-07-26 11:58
 搜索
搜索
机器人能通过普通视频来学会实际物理操作了! 来看效果,对于所有没见过的物品,它能精准识别并按照指令完成动作。
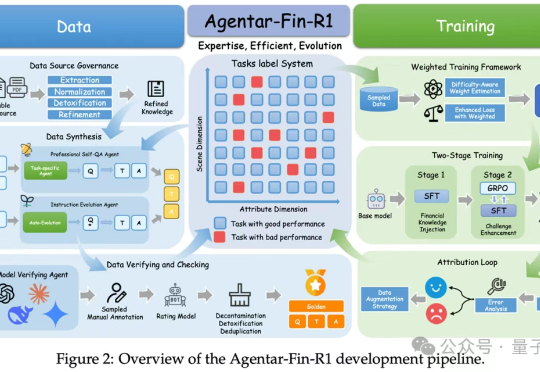
又到了一年一度“中国AI春晚”WAIC,各家大厂动作频发的时候。 今年会有哪些看点?你别说,我们还真在扒论文的过程中,发现了一些热乎线索。 比如蚂蚁数科的金融推理大模型,发布会还没开,技术论文已悄咪咪上线。 金融领域的推理大模型,你可以理解为金融领域的DeepSeek,带着SOTA的刷榜成绩来了。
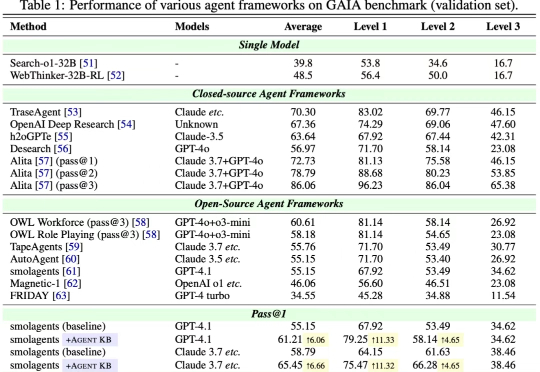
近日,来自 OPPO、耶鲁大学、斯坦福大学、威斯康星大学麦迪逊分校、北卡罗来纳大学教堂山分校等多家机构的研究团队联合发布了 Agent KB 框架。这项工作通过构建一个经验池并且通过两阶段的检索机制实现了 AI Agent 之间的有效经验共享。Agent KB 通过层级化的经验检索,让智能体能够从其他任务的成功经验中学习,显著提升了复杂推理和问题解决能力。

编程Agent王座,国产开源模型拿下了!就在刚刚,阿里通义大模型团队开源Qwen3-Coder,直接刷新AI编程SOTA——不仅在开源界超过DeepSeek V3和Kimi K2,连业界标杆、闭源的Claude Sonnet 4都比下去了。
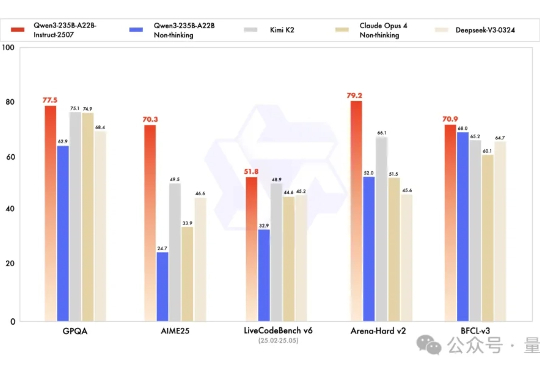
开源大模型正在进入中国时间。 Kimi K2风头正盛,然而不到一周,Qwen3就迎来最新升级,235B总参数量仅占Kimi K2 1T规模的四分之一。 基准测试性能上却超越了Kimi K2。
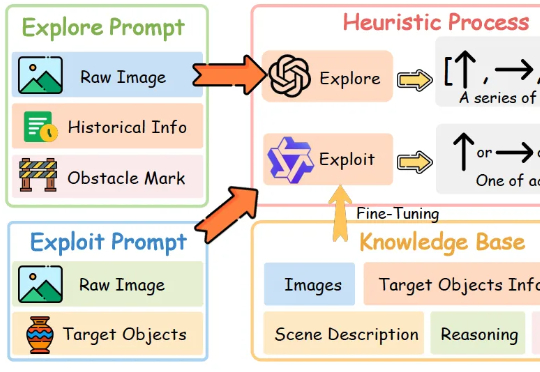
让机器人像人一样边看边理解,来自浙江大学和vivo人工智能实验室的研究团队带来了新进展。

现有视频异常检测(Video Anomaly Detection, VAD)方法中,有监督方法依赖大量领域内训练数据,对未见过的异常场景泛化能力薄弱;而无需训练的方法虽借助大语言模型(LLMs)的世界知识实现检测,但存在细粒度视觉时序定位不足、事件理解不连贯、模型参数冗余等问题。

你可能听说过OpenAI的Sora,用数百万视频、千万美元训练出的AI视频模型。 但你能想象,有团队只用3860段视频、不到500美元成本,也能在关键任务上做到SOTA?

近日,由普林斯顿大学牵头,联合清华大学、北京大学、上海交通大学、斯坦福大学,以及英伟达、亚马逊、Meta FAIR 等多家顶尖机构的研究者共同推出了新一代开源数学定理证明模型——Goedel-Prover-V2。

当前最强大的视觉语言模型(VLMs)虽然能“看图识物”,但在理解电影方面还不够“聪明”。