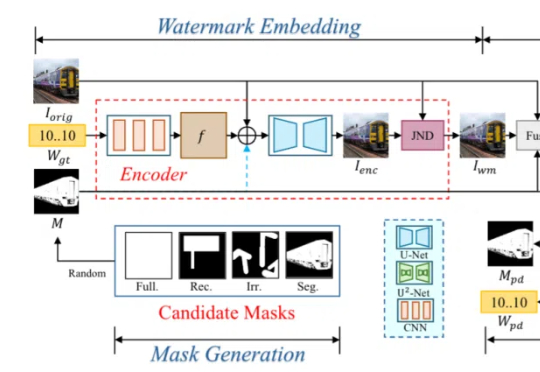
Databricks × Snowflake 纷纷下注,PostgreSQL 成 AI 时代数据库标准?
Databricks × Snowflake 纷纷下注,PostgreSQL 成 AI 时代数据库标准?本文内容整理自 ProtonBase CEO 王绍翾在 AICon 的主题演讲《Data Warebase: Instant Ingest-Transform-Explore-Retrieve for AI Applications》。
来自主题: AI资讯
11631 点击 2025-06-08 18:08