给大模型制作图文并茂的教科书: 从2.5年的教学视频里挖掘多模态语料
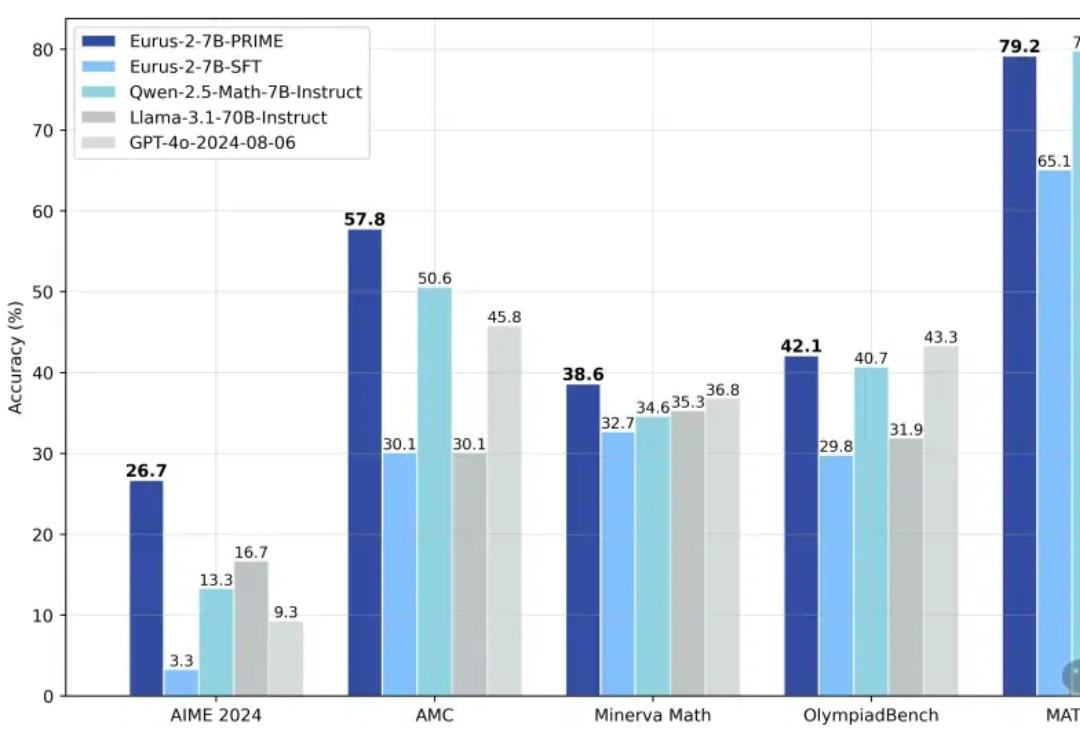
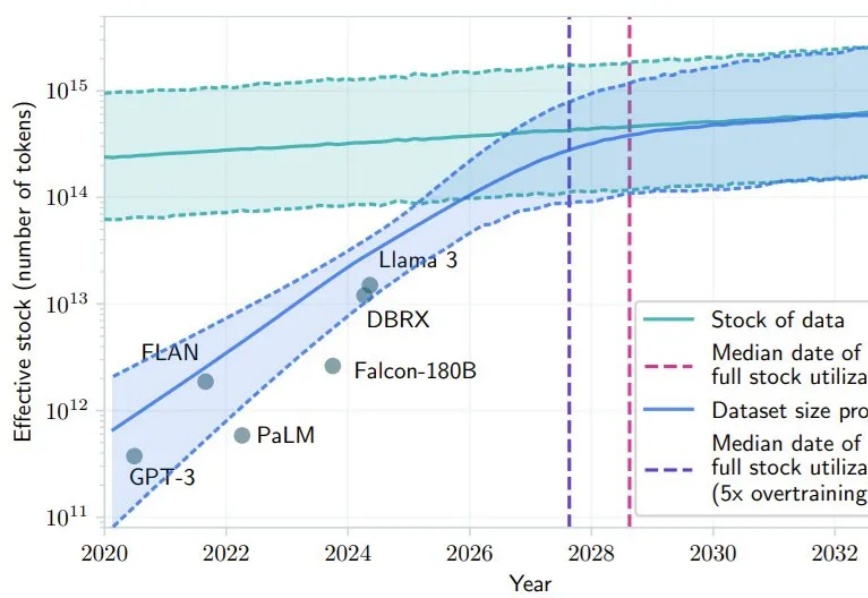
给大模型制作图文并茂的教科书: 从2.5年的教学视频里挖掘多模态语料近期关于 scaling law 的讨论甚嚣尘上,很多观点认为 scale law is dead. 然而,我们认为,高质量的 “无监督” 数据才是 scaling law 的关键,尤其是教科书级别的高质量的知识语料。此外,尽管传统的语料快枯竭了,但是互联网上还有海量的视频并没有被利用起来,它们囊括了丰富的多种模态的知识,可以帮助 VLMs 更好好地理解世界。
来自主题: AI技术研报
8469 点击 2025-01-20 19:01