
两本科生自学3个月复刻谷歌爆款产品,开源AI语音新标杆一天揽获5000星标
两本科生自学3个月复刻谷歌爆款产品,开源AI语音新标杆一天揽获5000星标谷歌现象级产品NotebookLM,两个本科生自学3个月就复刻了?
来自主题: AI资讯
9485 点击 2025-04-24 18:51
 搜索
搜索
谷歌现象级产品NotebookLM,两个本科生自学3个月就复刻了?
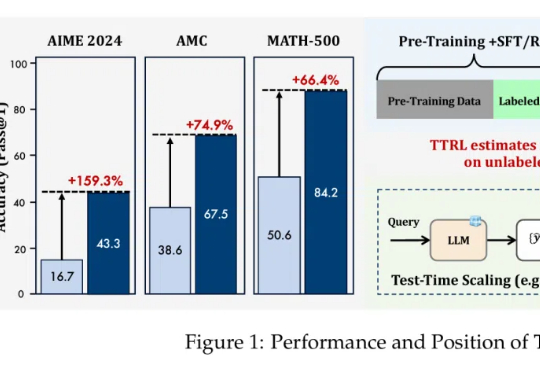
在大语言模型(LLMs)竞争日趋白热化的今天,「推理能力」已成为评判模型优劣的关键指标。
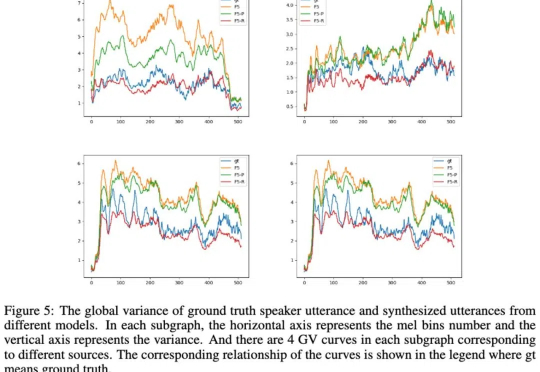
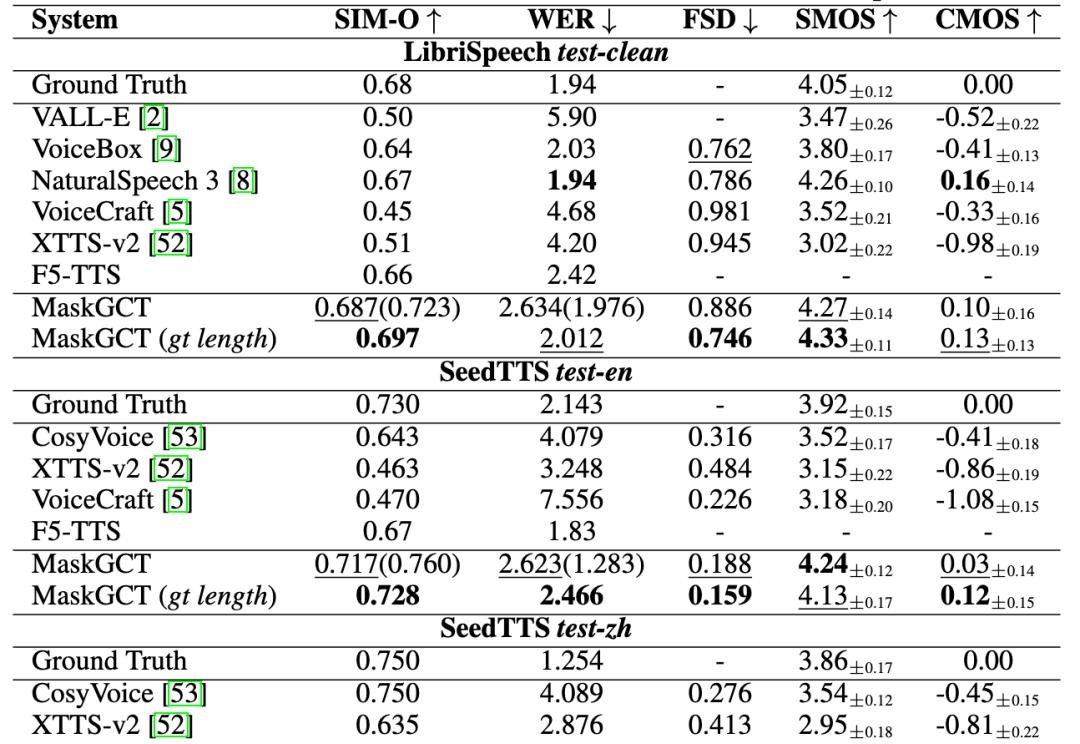
在人工智能技术日新月异的今天,语音合成(TTS)领域正经历着一场前所未有的技术革命。最新一代文本转语音系统不仅能够生成媲美真人音质的高保真语音,更实现了「只听一次」就能完美复刻目标音色的零样本克隆能力。

Two Heads are Better Than One"(两个脑袋比一个好/双Agent更优)源自英语中的一句古老谚语。MAS-TTS框架的研究者将这一朴素智慧应用到LLM中,创造性地让多个智能体协同工作,如同专家智囊团。
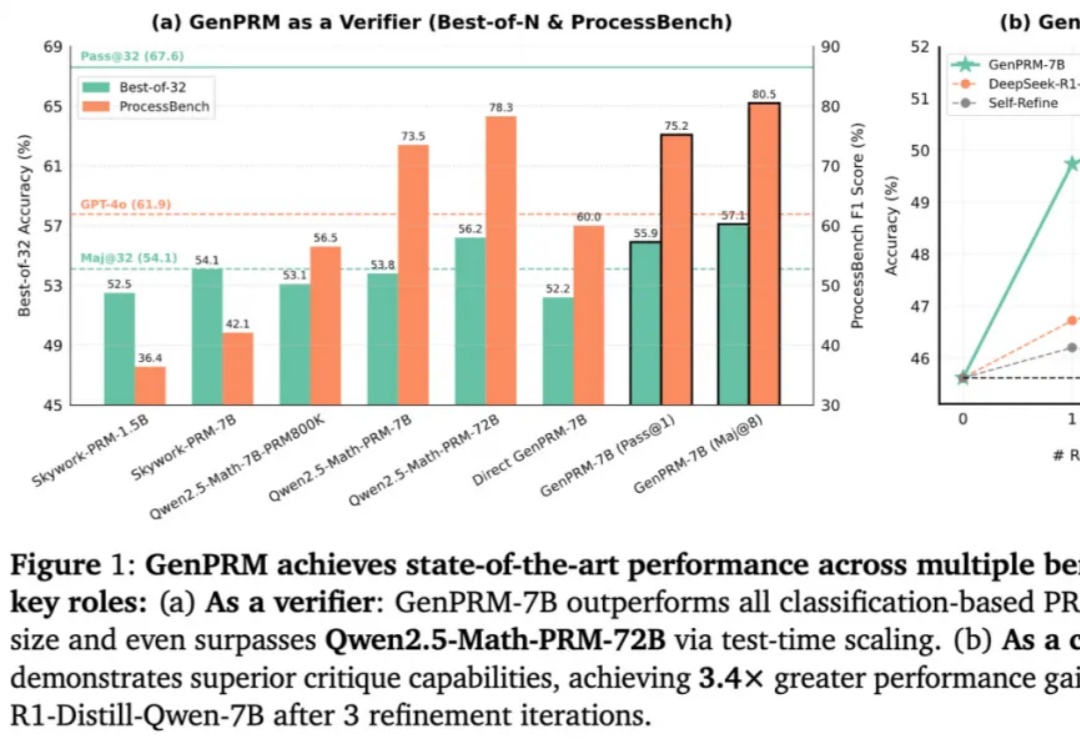
随着 OpenAI o1 和 DeepSeek R1 的爆火,大语言模型(LLM)的推理能力增强和测试时扩展(TTS)受到广泛关注。然而,在复杂推理问题中,如何精准评估模型每一步回答的质量,仍然是一个亟待解决的难题。传统的过程奖励模型(PRM)虽能验证推理步骤,但受限于标量评分机制,难以捕捉深层逻辑错误,且其判别式建模方式限制了测试时的拓展能力。
“最强AI语音”的场景化突围。

2025 年 3 月 11 日,语音生成初创公司 Cartesia 宣布完成 6400 万美元 A 轮融资,距其 2700 万美元种子轮融资仅过去不到 3 个月。本轮融资由 Kleiner Perkins 领投,Lightspeed、Index、A*、Greycroft、Dell Technologies Capital 和 Samsung Ventures 等跟投。
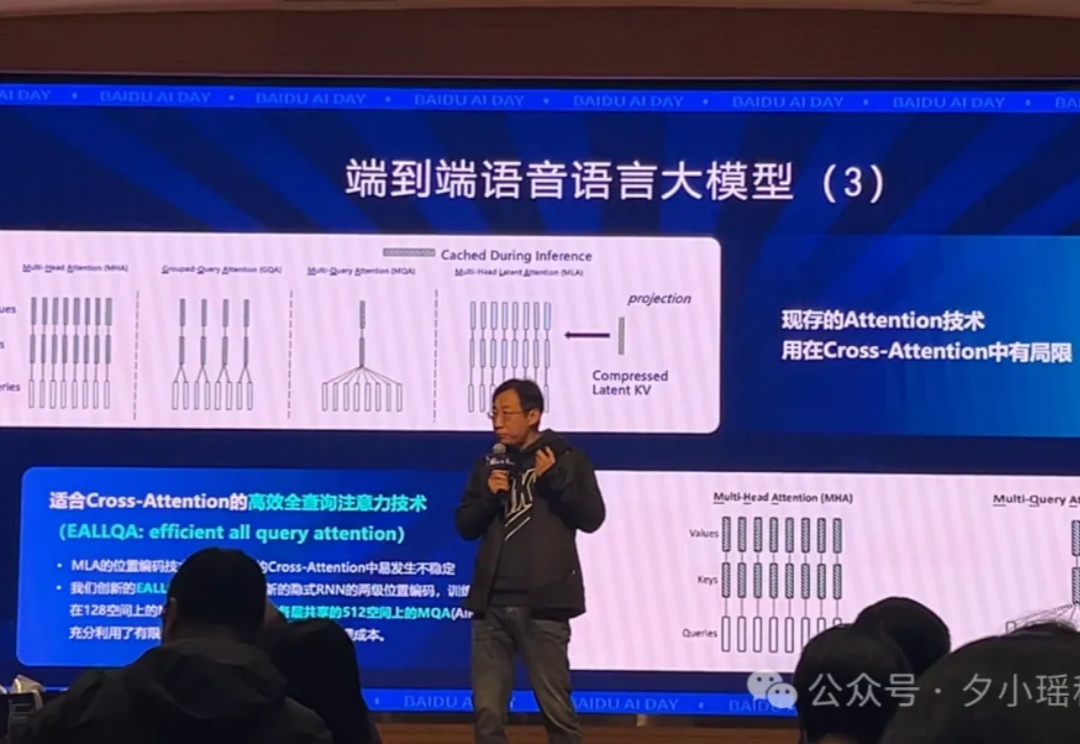
大家好,我是小瑶,今天是你们的 AI 前排吃瓜 + 技术解读博主。

(用户的)信任是要靠争取的,如果模型在设计时没有考虑到这一点,它们就永远无法发挥出全部潜力。
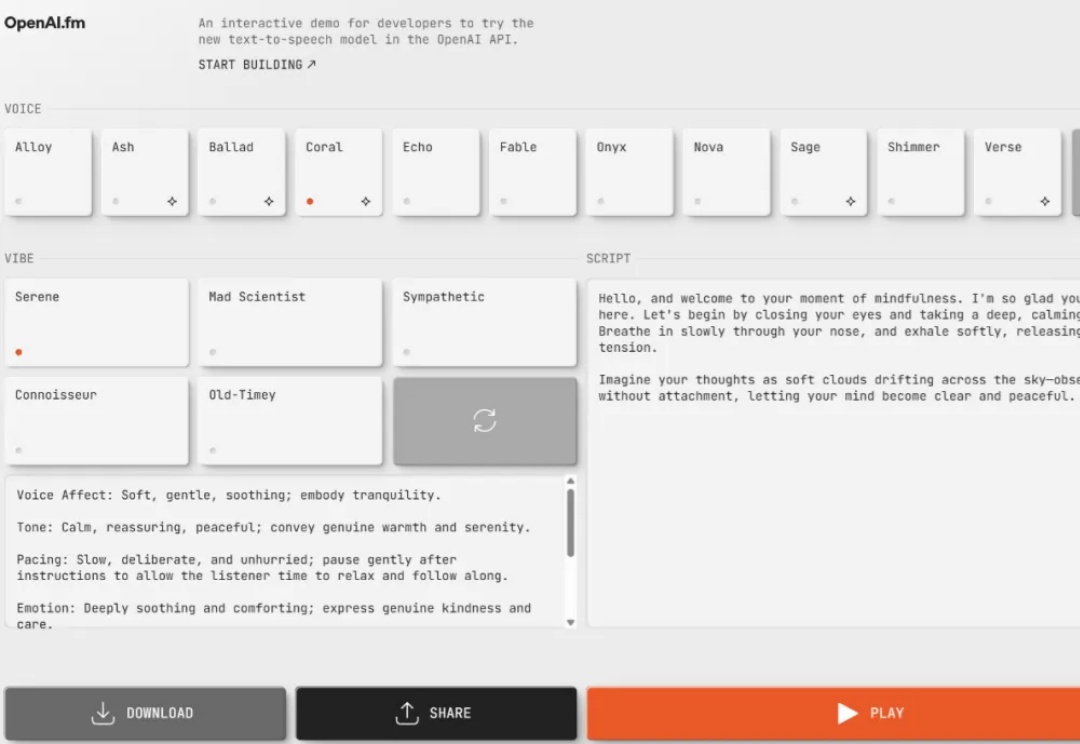
现在,你可以指导 GPT-4o 的说话方式了。