告别Transformer,重塑机器学习范式:上海交大首个「类人脑」大模型诞生
告别Transformer,重塑机器学习范式:上海交大首个「类人脑」大模型诞生当前 GPT 类大语言模型的表征和处理机制,仅在输入和输出接口层面对语言元素保持可解释的语义映射。相比之下,人类大脑直接在分布式的皮层区域中编码语义,如果将其视为一个语言处理系统,它本身就是一个在全局上可解释的「超大模型」。
来自主题: AI技术研报
8557 点击 2025-08-14 11:11
 搜索
搜索
当前 GPT 类大语言模型的表征和处理机制,仅在输入和输出接口层面对语言元素保持可解释的语义映射。相比之下,人类大脑直接在分布式的皮层区域中编码语义,如果将其视为一个语言处理系统,它本身就是一个在全局上可解释的「超大模型」。
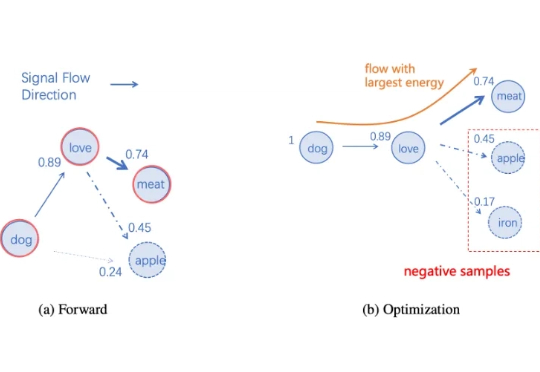
27M小模型超越o3-mini-high和DeepSeek-R1!推理还不靠思维链。 开发者是那位拒绝了马斯克、还要挑战Transformer的00后清华校友,Sapient Intelligence的创始人王冠。

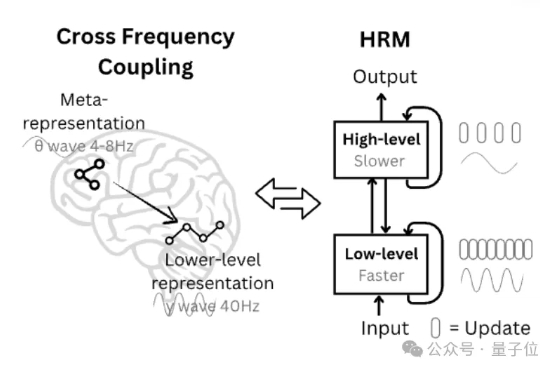
在大语言模型席卷全球的时代,坚持更接近生命本质的智能是少有人走的路。2025年7月初,一篇来自Numenta与Thousand Brains Project的论文,首次通过一个名为“Monty”的AI系统,实验性地验证了神经科学家杰夫·霍金斯(Jeff Hawkins)提出的“千脑智能理论”。

国内 AI 创企 RockAI 提出的非 Transformer 架构 Yan 2.0 Preview。这个架构极大地降低了模型推理时的计算复杂度,因此可以在算力非常有限的设备上离线运行,比如树莓派。

如何理解大模型推理能力?现在有来自谷歌DeepMind推理负责人Denny Zhou的分享了。 就是那位和清华姚班马腾宇等人证明了只要思维链足够长,Transformer就能解决任何问题的Google Brain推理团队创建者。 Denny Zhou围绕大模型推理过程和方法,在斯坦福大学CS25上讲了一堂“LLM推理”课。
大型语言模型已展现出卓越的能力,但其部署仍面临巨大的计算与内存开销所带来的挑战。随着模型参数规模扩大至数千亿级别,训练和推理的成本变得高昂,阻碍了其在许多实际应用中的推广与落地。
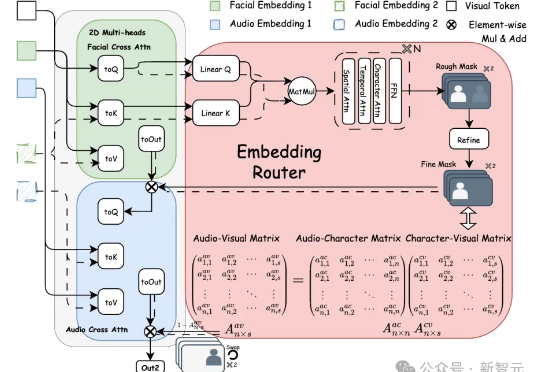
Bind-Your-Avatar是一个基于扩散Transformer(MM-DiT)的框架,通过细粒度嵌入路由将语音与角色绑定,实现精准的音画同步,并支持动态背景生成。该框架还引入了首个针对多角色对话视频生成的数据集MTCC和基准测试,实验表明其在身份保真和音画同步上优于现有方法。

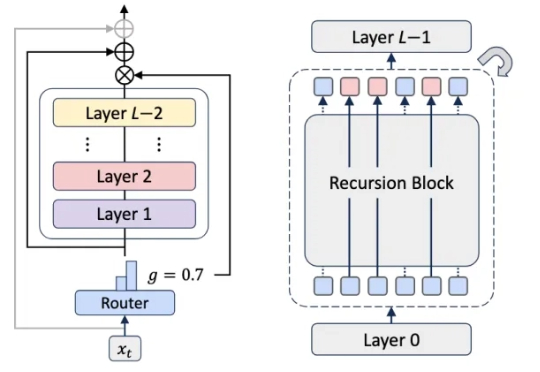
Transformer杀手来了?KAIST、谷歌DeepMind等机构刚刚发布的MoR架构,推理速度翻倍、内存减半,直接重塑了LLM的性能边界,全面碾压了传统的Transformer。网友们直呼炸裂:又一个改变游戏规则的炸弹来了。
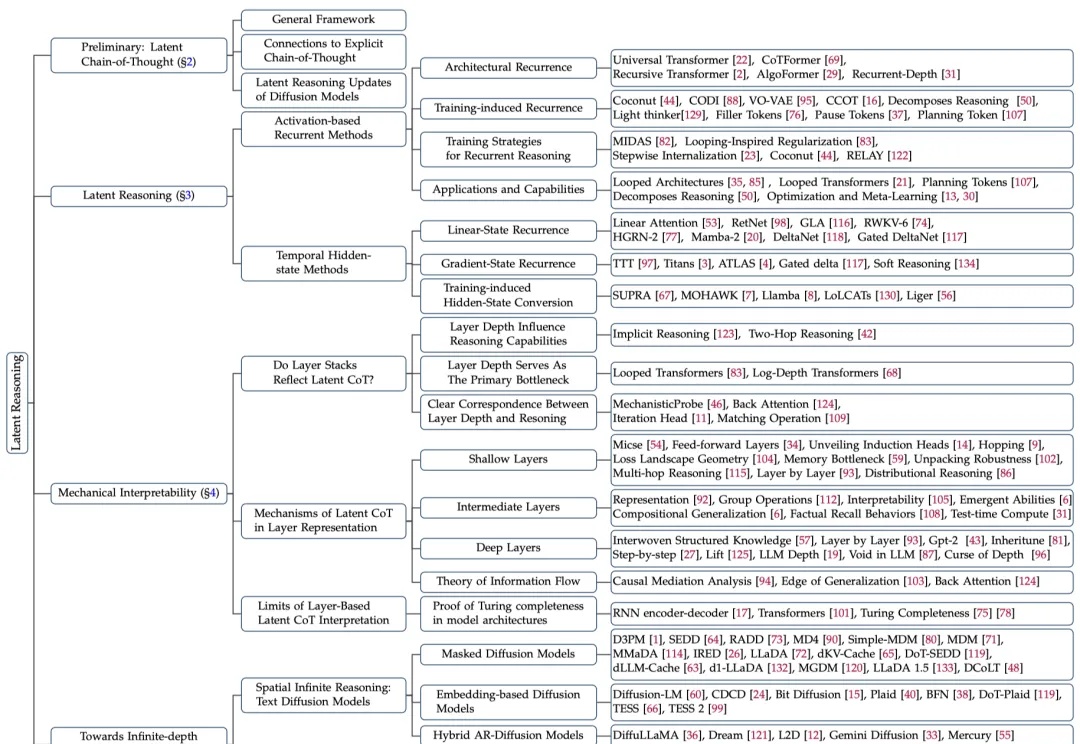
大模型在潜空间中推理,带宽能达到普通(显式)思维链(CoT)的2700多倍?
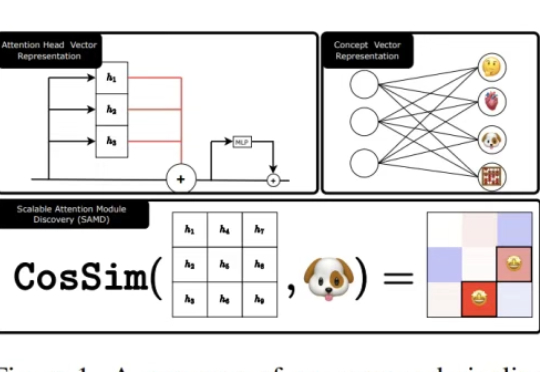
AI也能选择性失忆?Meta联合NYU发布新作,轻松操控缩放Transformer注意头,让大模型「忘掉狗会叫」。记忆可删、偏见可调、安全可破,掀开大模型「可编辑时代」,安全边界何去何从。