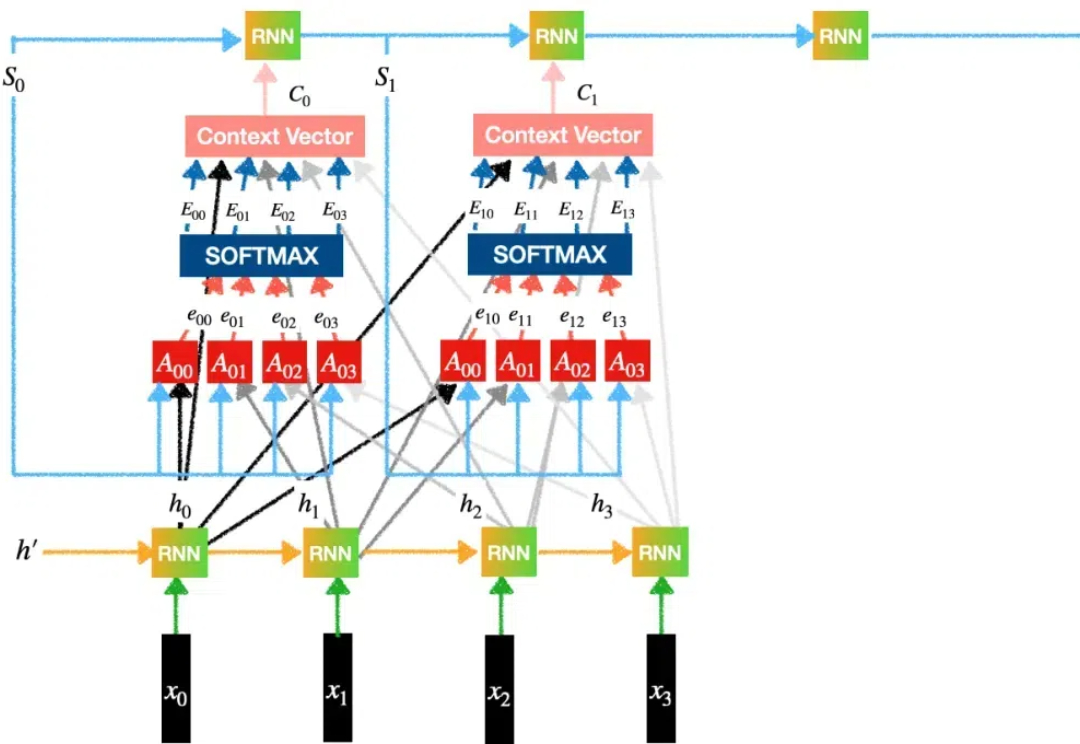
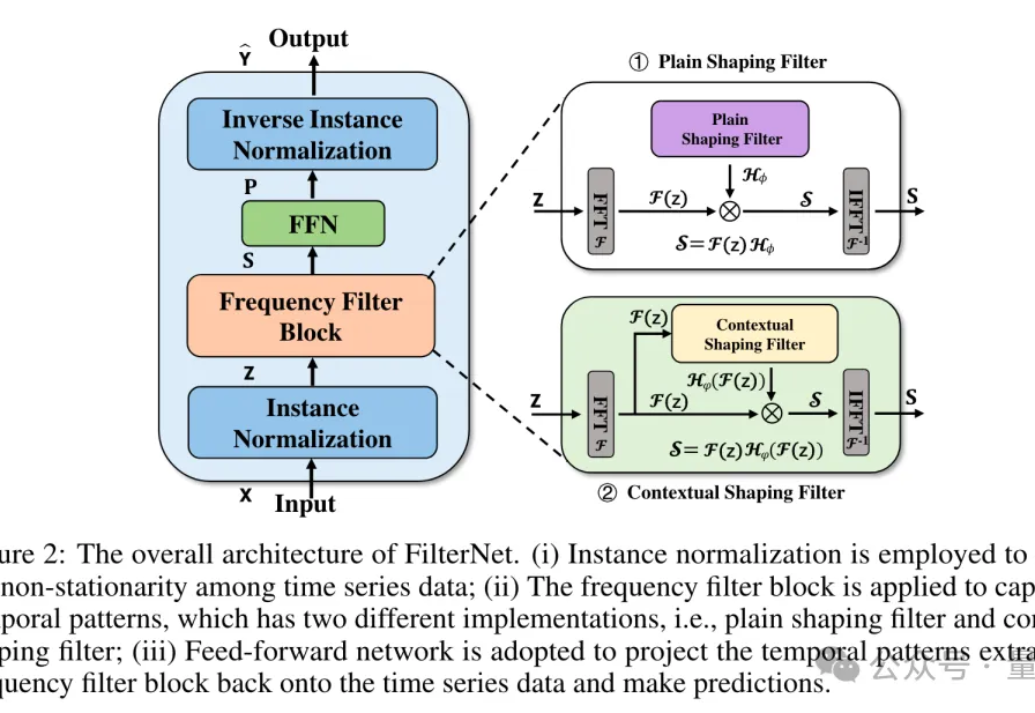
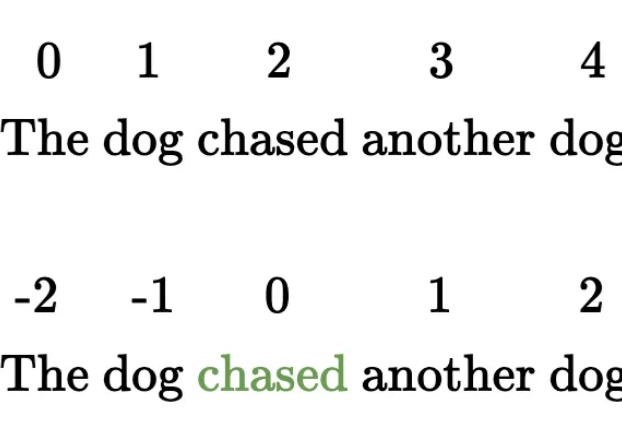
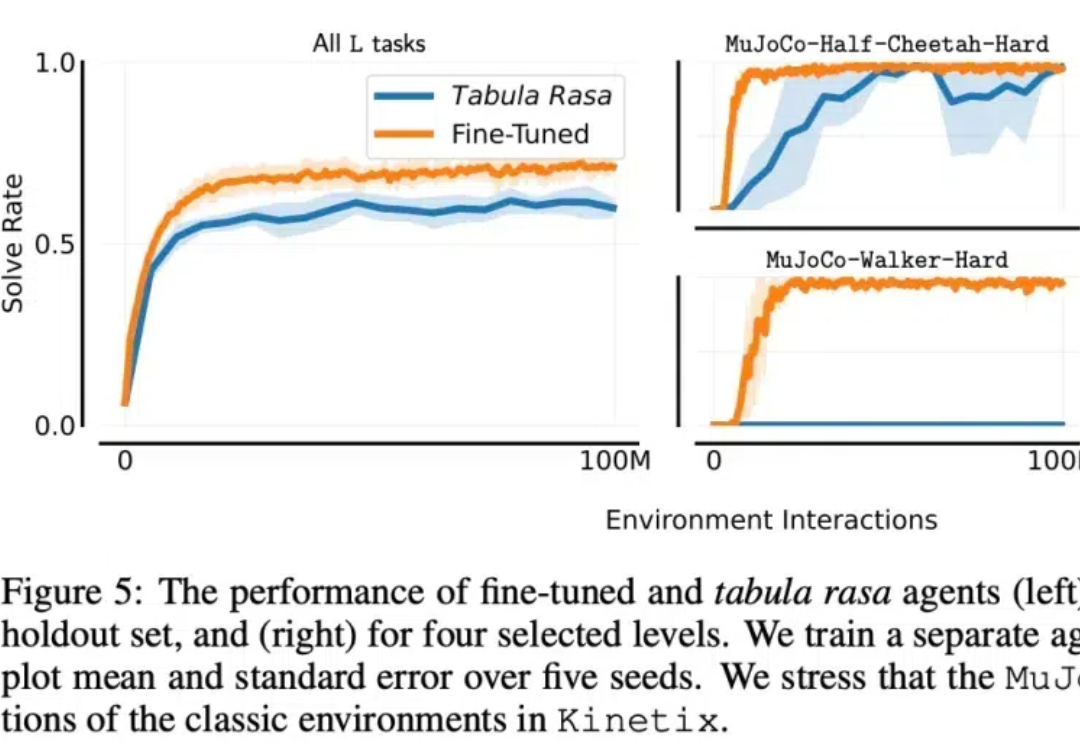
Mamba作者带斯坦福同学、导师创业,Cartesia获2700万美元种子轮融资
Mamba作者带斯坦福同学、导师创业,Cartesia获2700万美元种子轮融资Mamba 这种状态空间模型(SSM)被认为是 Transformer 架构的有力挑战者。近段时间,相关研究成果接连不断。而就在不久前,Mamba 作者 Albert Gu 与 Karan Goel、Chris Ré、Arjun Desai、Brandon Yang 一起共同创立的 Cartesia 获得 2700 万美元种子轮融资。
来自主题: AI技术研报
9455 点击 2024-12-13 17:21