
对话RWKV作者彭博:单枪匹马挑战Transformer的神秘怪才
对话RWKV作者彭博:单枪匹马挑战Transformer的神秘怪才一个人,待在家里,“懒散”的有一搭没一搭,训练一个要挑战已经“一统世界”的Transformer 的模型。这听起来足够夸张。
来自主题: AI资讯
10801 点击 2024-08-08 14:45
 搜索
搜索
一个人,待在家里,“懒散”的有一搭没一搭,训练一个要挑战已经“一统世界”的Transformer 的模型。这听起来足够夸张。

Transformer架构层层堆叠,包含十几亿甚至几十亿个参数,这些层到底是如何工作的?当一个新奇的比喻——「画家流水线」,被用于类比并理解Transformer架构的中间层,情况突然变得明朗起来,并引出了一些有趣的发现。

七年前,论文《Attention is all you need》提出了 transformer 架构,颠覆了整个深度学习领域。

逆合成是药物发现和有机合成中的一项关键任务,AI 越来越多地用于加快这一过程。

卖身,AI大模型创企的归宿?
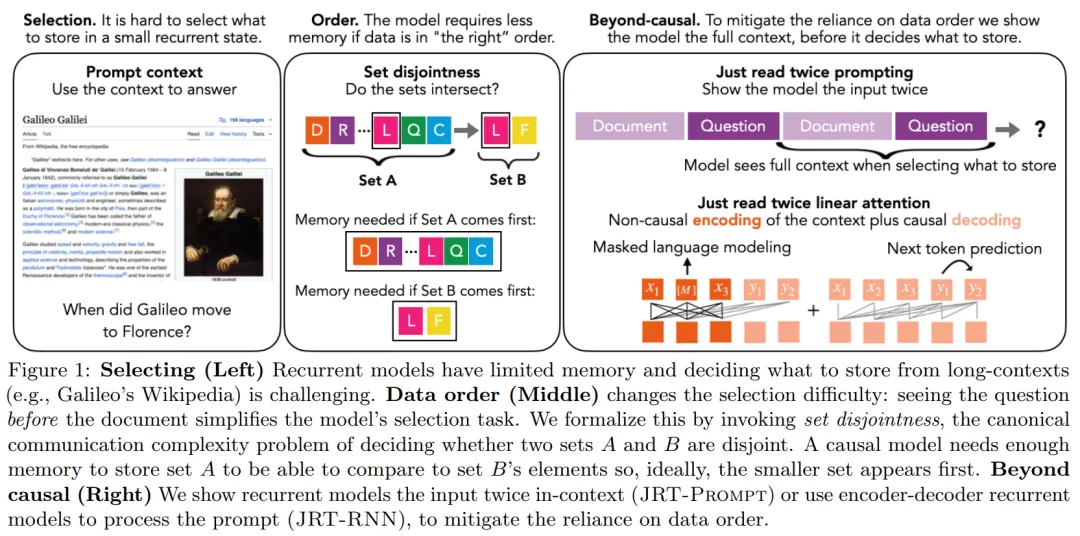
在当前 AI 领域,大语言模型采用的主流架构是 Transformer。不过,随着 RWKV、Mamba 等架构的陆续问世,出现了一个很明显的趋势:在语言建模困惑度方面与 Transformer 较量的循环大语言模型正在快速进入人们的视线。

人工智能赛道最受关注的独角兽之一,Character.AI迎来了新命运。尽管近期媒体报道,伊隆·马斯克的 xAI 正在考虑收购Character.AI,但最终摘到果实的是谷歌。

明星AI独角兽Character.AI,核心团队被谷歌打包带走了。

明星AI独角兽Character.AI,核心团队被谷歌打包带走了。

AI 初创者的归宿还是大厂?