
单GPU训练一天,Transformer在100位数字加法上就达能到99%准确率
单GPU训练一天,Transformer在100位数字加法上就达能到99%准确率乘法和排序也有效。
来自主题: AI技术研报
9119 点击 2024-06-01 19:00
 搜索
搜索
乘法和排序也有效。

用卷积能做出一样好的效果。

即使最强大的 LLM 也难以通过 token 索引来关注句子等概念,现在有办法了。

一位优秀的相声演员需要吹拉弹唱样样在行,类似地,一个优秀的机器人模型也应能适应多样化的机器人形态和不同的任务,但目前大多数机器人模型都只能控制一种形态的机器人执行一类任务。现在 Octo(八爪鱼)来了!这个基于 Transformer 的模型堪称当前最强大的开源机器人学习系统,无需额外训练就能完成多样化的机器人操控任务并能在一定程度适应新机器人形态和新任务,就像肢体灵活的八爪鱼。

科学家们把Transformer模型应用到蛋白质序列数据中,试图在蛋白质组学领域复制LLM的成功。本篇文章能够带你了解蛋白质语言模型(pLM)的起源、发展,以及那些尚待解决的问题。

既能像 Transformer 一样并行训练,推理时内存需求又不随 token 数线性递增,长上下文又有新思路了?
大模型公司洗牌期开始了。 突然之间,几家明星初创纷纷传出消息,寻求收购。都是大家熟悉的名字、过往战绩也都不错:Adept,估值超10亿美元,由Transformer作者创立;Humane,估值7.5-10亿美元,打造出爆火AI新硬件AI Pin;Stability AI,Stable Diffusion打造者,最早一批AI独角兽。
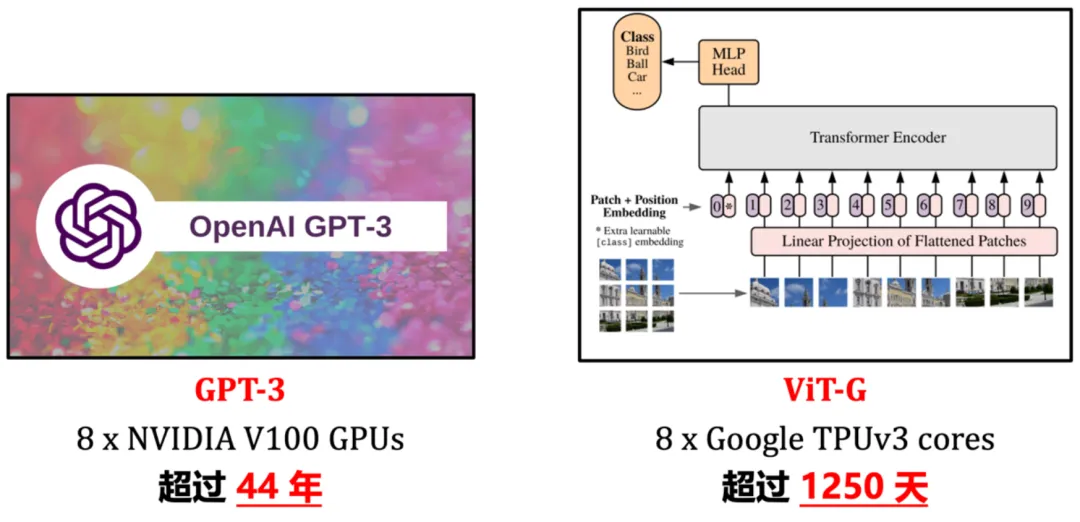
近年来,「scaling」是计算机视觉研究的主角之一。随着模型尺寸和训练数据规模的增大、学习算法的进步以及正则化和数据增强等技术的广泛应用,通过大规模训练得到的视觉基础网络(如 ImageNet1K/22K 上训得的 Vision Transformer、MAE、DINOv2 等)已在视觉识别、目标检测、语义分割等诸多重要视觉任务上取得了令人惊艳的性能。

Llama 3发布一个月后,一位开发者在GitHub上创建了名为「从头开始实现Llama 3」的项目,引起了开源社区的广泛关注。代码非常详细地展现了Llama所使用的Transformer架构,甚至让Andrej Karpathy亲自下场「背书」。

预训练语言模型在分析核苷酸序列方面显示出了良好的前景,但使用单个预训练权重集在不同任务中表现出色的多功能模型仍然存在挑战。