
全网破防,AI「手指难题」翻车逼疯人类!6根手指,暴露Transformer致命缺陷
全网破防,AI「手指难题」翻车逼疯人类!6根手指,暴露Transformer致命缺陷最近,网友们已经被AI「手指难题」逼疯了。给AI一支六指手,它始终无法正确数出到底有几根手指!说吧AI,你是不是在嘲笑人类?其实这背后,暗藏着Transformer架构的「阿喀琉斯之踵」……
来自主题: AI技术研报
7176 点击 2025-12-16 10:37
 搜索
搜索
最近,网友们已经被AI「手指难题」逼疯了。给AI一支六指手,它始终无法正确数出到底有几根手指!说吧AI,你是不是在嘲笑人类?其实这背后,暗藏着Transformer架构的「阿喀琉斯之踵」……

现在的大学生该选什么专业?未来一百年的大学会是什么样子?业界 AI 如此强势,学界还能做什么?谷歌在过去二十多年里做对了什么,又有哪些遗憾?

“人工智能要发展到下一个台阶,一定要突破两座大山。第一座大山是Transformer,第二座大山是反向传播算法。”在大模型规模不断拔高、算力与数据卷到极致的当下,RockAI创始人刘凡平提出了一个与主流共识截然不同的判断。

北航刘偲教授团队提出首个大规模真实星座调度基准AEOS-Bench,更创新性地将Transformer模型的泛化能力与航天工程的专业需求深度融合,训练内嵌时间约束的调度模型AEOS-Former。这一组合为未来的“AI星座规划”奠定了新的技术基准。

我们以为语言是语法、规则、结构。但最新的Nature研究却撕开了这层幻觉。GPT的层级结构与竟与人大脑里的「时间印记」一模一样。当浅层、中层、深层在脑中依次点亮,我们第一次看见:理解语言,也许从来不是解析,而是预测。

谷歌DeepMind掌门人断言,2030年AGI必至!不过,在此之前,还差1-2个「Transformer级」核爆突破。恰在NeurIPS大会上,谷歌甩出下一代Transformer最强继任者——Titans架构。

两项关于大模型新架构的研究一口气在NeurIPS 2025上发布,通过“测试时训练”机制,能在推理阶段将上下文窗口扩展至200万token。两项新成果分别是:Titans:兼具RNN速度和Transformer性能的全新架构;MIRAS:Titans背后的核心理论框架。

当地时间12月4日下午,谷歌研究员的一篇论文在现场引来了超多AI爱好者的围观。甚至,被业界专家视为“为AGI发展提供了新框架”,一位人士评价为:这篇论文将成为逐步推动实现AGI的5~10篇论文中的一篇。
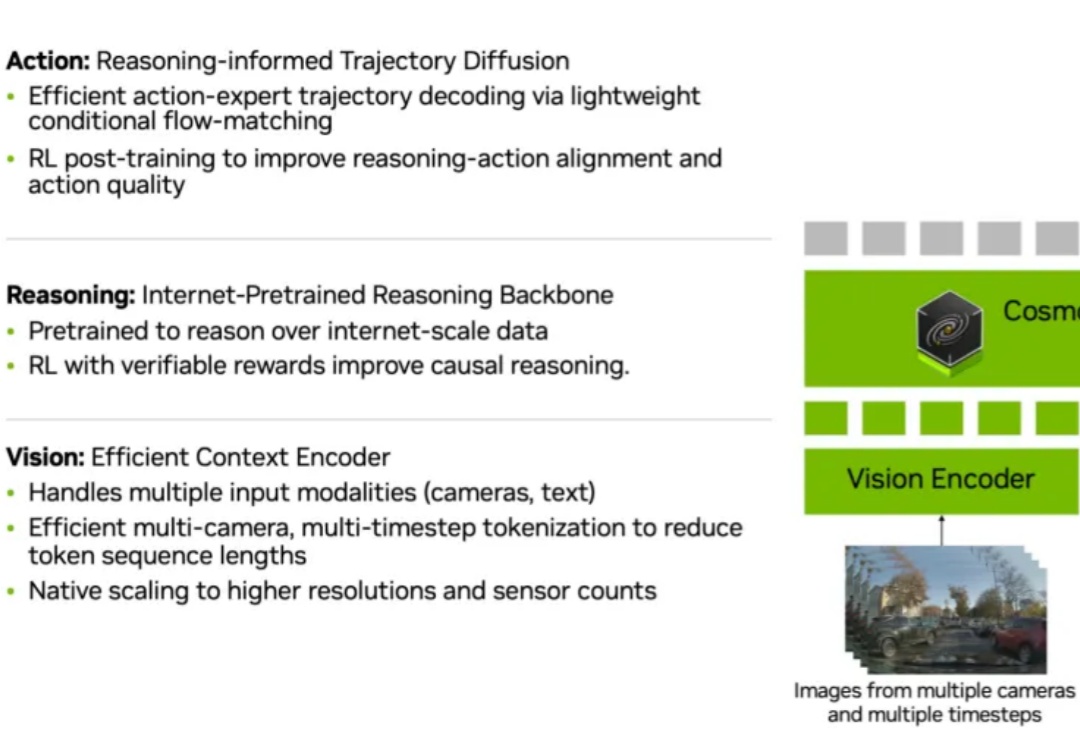
当今自动驾驶模型越来越强大,摄像头、雷达、Transformer 网络一齐上阵,似乎什么都「看得见」。但真正的挑战在于:模型能否像人一样「想明白」为什么要这么开?

我们正在经历一次静悄悄、但本质性的AI范式转换。