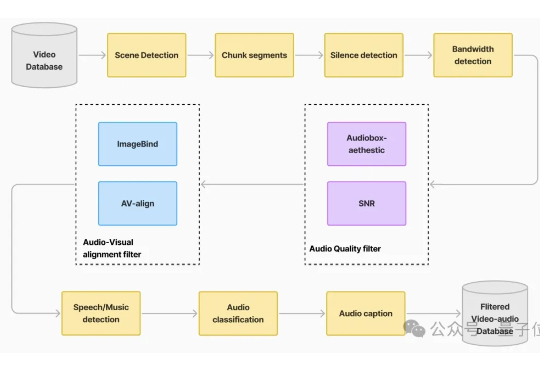
腾讯混元最新开源:一键生成电影级音效,性能表现全面SOTA
腾讯混元最新开源:一键生成电影级音效,性能表现全面SOTA自带声音的视频生成模型,开源版开卷! 最新赶到的是腾讯混元:刚刚正式开源端到端的视频音效生成模型HunyuanVideo-Foley。
来自主题: AI资讯
9417 点击 2025-08-29 12:12
 搜索
搜索
自带声音的视频生成模型,开源版开卷! 最新赶到的是腾讯混元:刚刚正式开源端到端的视频音效生成模型HunyuanVideo-Foley。

传统 video dubbing 技术长期受限于其固有的 “口型僵局”,即仅能编辑嘴部区域,导致配音所传递的情感与人物的面部、肢体表达严重脱节,削弱了观众的沉浸感。现有新兴的音频驱动视频生成模型,在应对长视频序列时也暴露出身份漂移和片段过渡生硬等问题。

在软件领域,Vibe Coding的核心在于:让开发者摆脱繁琐、低产出的代码编写,把体力活交给 AI,从而专注于更高维度的产品迭代与创意探索——追求的是效率 + 创意的双重突破。
AI视频生成,快速进入Agent时代! 只需一句提示词:生成一个F1赛车的现场解说视频。 AI即可自动完成分镜、画面、配音、字幕,生成结构完整、节奏在线的爆款视频。
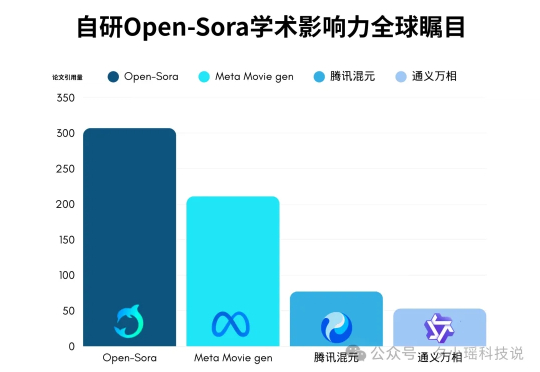
在软件领域,Vibe Coding 的核心在于:让开发者摆脱繁琐、低产出的代码编写,把体力活交给 AI,从而专注于更高维度的产品迭代与创意探索——追求的是 效率 + 创意 的双重突破。
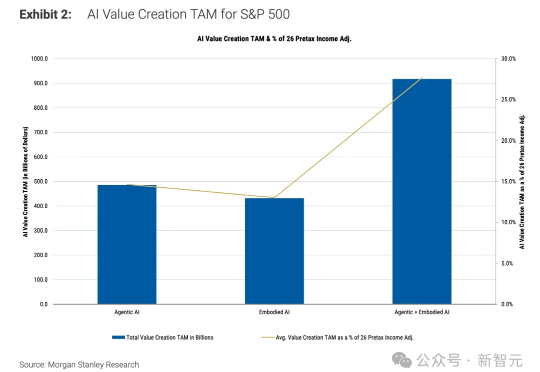
全球95%企业AI惨遭滑铁卢?MIT 26页爆火报告揭开真相:90%员工悄悄用ChatGPT高效办公,在科技、媒体行业掀起了效率革命。
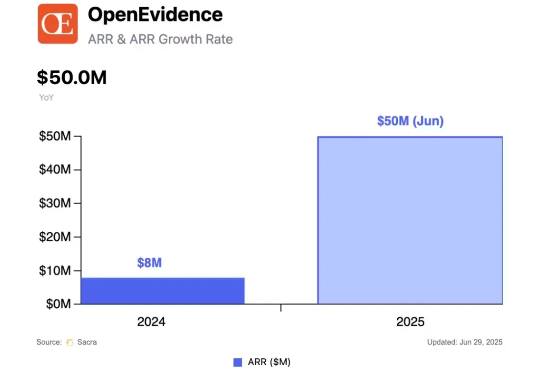
首个满分选手的出现,标志着AI医疗的又一个里程碑。 近日,美国初创公司OpenEvidence宣布,其开发的全新AI系统在美国医师执照考试(USMLE)中获得了100%的满分。
穿着运动鞋的鲨鱼踩着滑板冲浪,头顶卡布奇诺泡沫的芭蕾舞者在水晶球里旋转——这些被称为“脑残视频”(Brainrot Videos)的荒诞内容正在TikTok和Instagram上病毒式传播,年轻用户群体疯狂追捧这些脱离现实逻辑的视觉梗图,单条播放量动辄突破千万。

这位AI创始人靠打造医生专用的“ChatGPT”成为亿万富豪。丹尼尔·纳德勒(Daniel Nadler)创办了OpenEvidence,帮医生们从海量医学研究中理出头绪。如今,他已筹得2.1亿美元资金,公司估值达35亿美元。
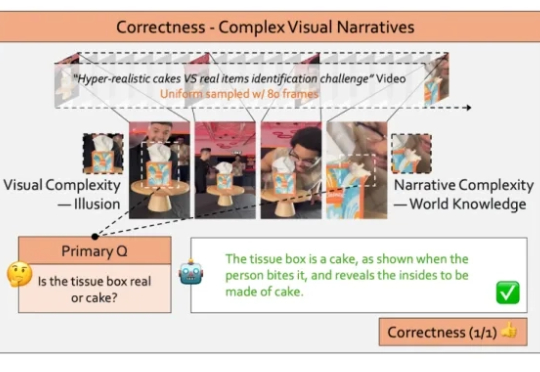
视频大型语言模型(Video LLMs)的发展日新月异,它们似乎能够精准描述视频内容、准确的回答相关问题,展现出足以乱真的人类级理解力。