终于找到一键做爆款AI短视频的办法了!OiiOii 2.0升级实测【保姆级教程】
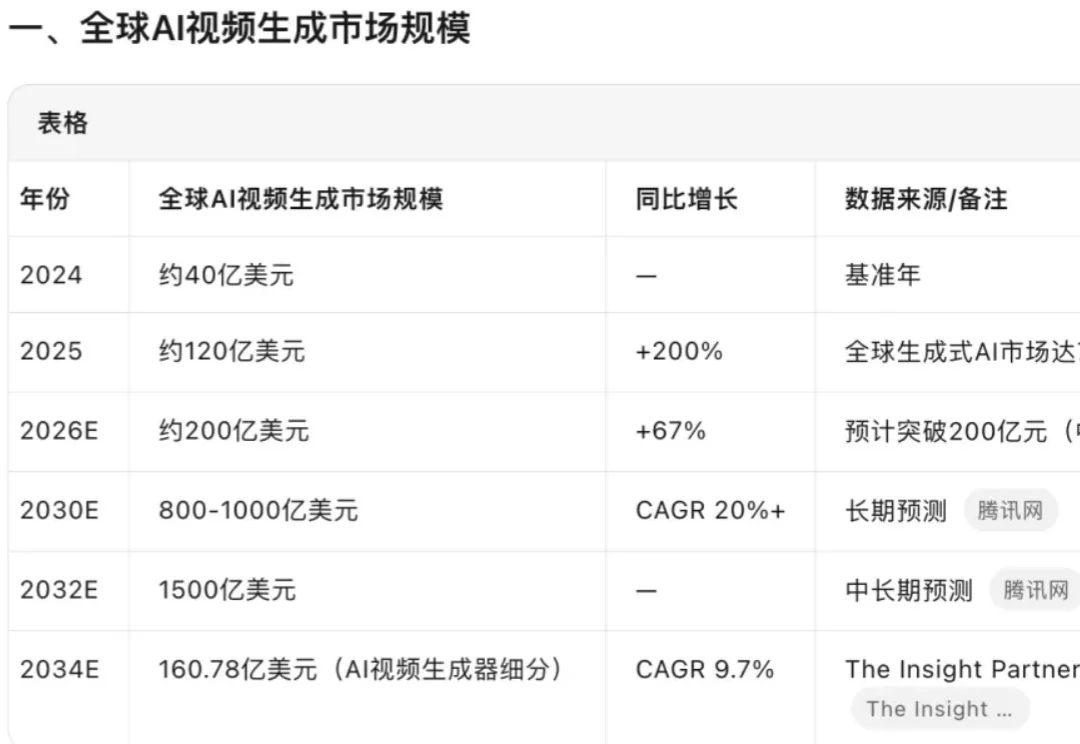
终于找到一键做爆款AI短视频的办法了!OiiOii 2.0升级实测【保姆级教程】我最近专门调研了一下AI短视频🧐。发现市场规模是越来越大。
来自主题: AI技术研报
9045 点击 2026-06-12 10:47
 搜索
搜索
我最近专门调研了一下AI短视频🧐。发现市场规模是越来越大。
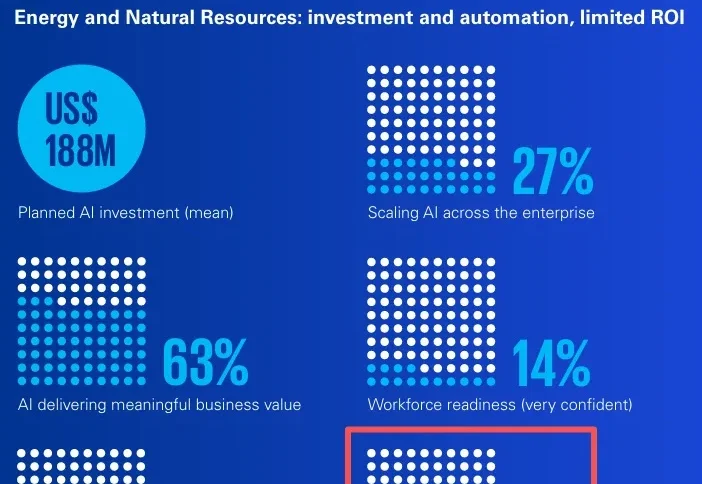
一提到AI的应用和落地,大家就会陷入非共识迷雾。为了拨开营销炒作,我把近期有代表性的几份Enterprise AI调研报告拉通,横跨Menlo Ventures(500+企业AI决策者)、德勤(24个国家,6大行业,3235名高管)、KPMG(20个国家,8大行业,2110名全球高管)、Entelligence(2444家企业)。
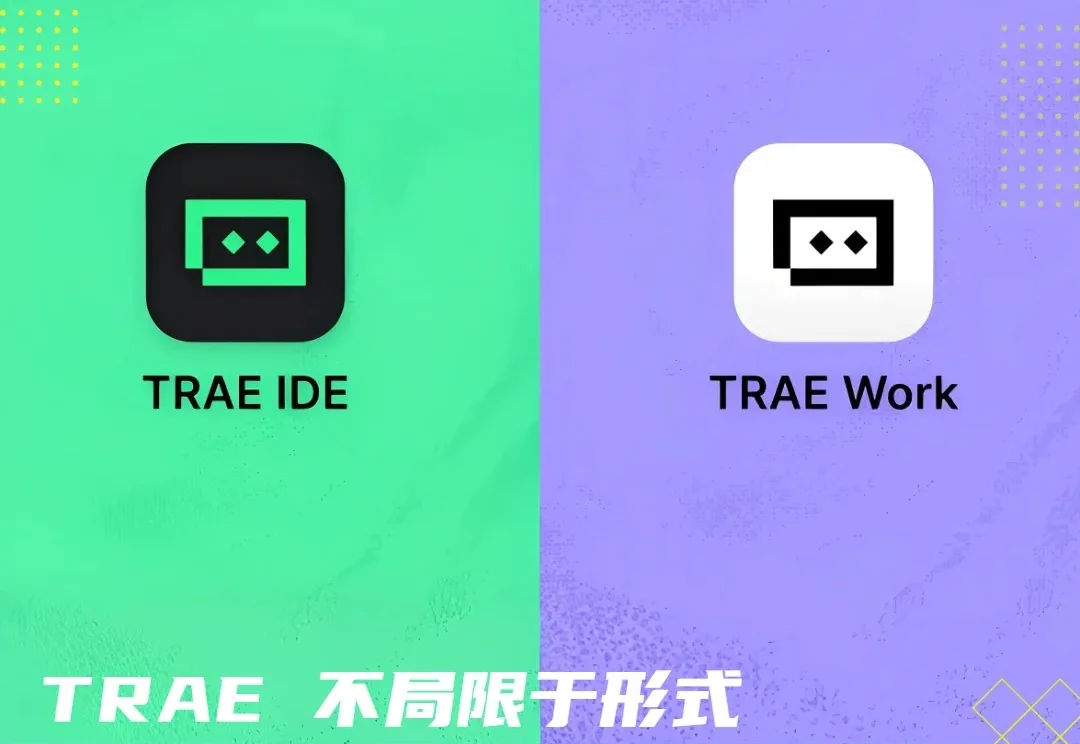
6 月 9 日,TRAE SOLO 正式升级为 TRAE Work,桌面端与网页端同步上线。新的品牌主张很直接:让 TRAE 为你工作。

这两天AI圈有个词特别火,叫做loop工程。

Claude Fable 5 发布之后,奥特曼又要被吓到眩晕瘫坐,犹如看到原子弹爆炸了。 短短 24 小时里,社交平台几乎被各种案例淹没。视频一个接一个冒出来,我们还没看完上一个,时间线又跳出一个由

今年开年以来,不管是硅谷、还是国内的 AI 投资圈子,都不太敢投 AI 应用了。

上下文攻击、供应链渗透、AI社区崩溃……当大模型智能体真正进入开放世界,挑战远比想象中复杂。
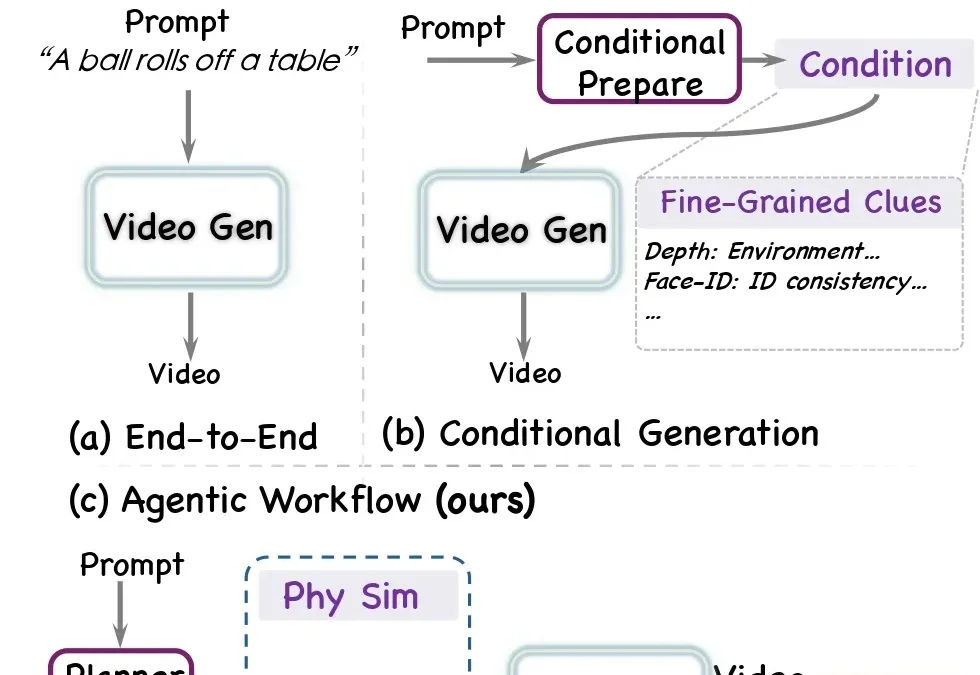
近年来,视频生成模型发展迅猛。从 Sora、Veo、Kling 到一系列开源视频生成模型,文生视频已经逼近真实影像的观感 —— 画面清晰、镜头流畅、风格可控,一句话就能生成一段观感不错的视频。
如果把一个商业化产品、一个科技公司的底层系统比作一棵树,那任意挑出一个项目,层层抽丝剥茧之后,你一定会发现,最早的年轮,一定与开源有关。

近日,Anthropic 发布了一篇引发广泛关注的文章《When AI builds itself》。文中披露了极其惊人的内部数据:截至 2026 年 5 月,Anthropic 超过 80% 的合并代码已由 Claude 编写,工程师的日常代码产出飙升了 8 倍;更令人瞩目的是,AI 智能体已经可以自主提出假设、执行长达数百小时的强化安全实验。