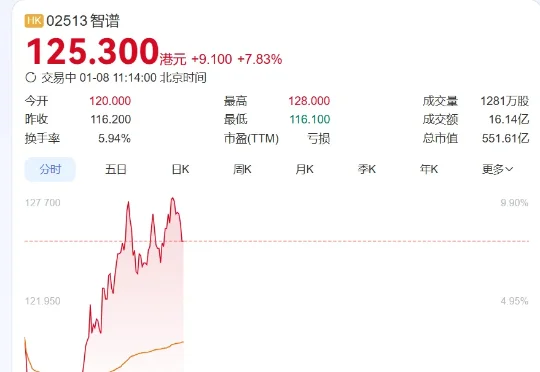
发布 ChatGPT 健康 6 天后,OpenAI 在自家医疗健康 Benchmark 上被百川M3模型反超
发布 ChatGPT 健康 6 天后,OpenAI 在自家医疗健康 Benchmark 上被百川M3模型反超百川智能表示今年上半年,将陆续发布两款 to C 的医疗产品。 作者|Li Yuan 编辑|郑玄 你有没有向 AI 助手问过你的健康问题? 如果你和我一样是一个 AI 的深度用户,大概率你也试过。 O
来自主题: AI资讯
10070 点击 2026-01-14 09:24