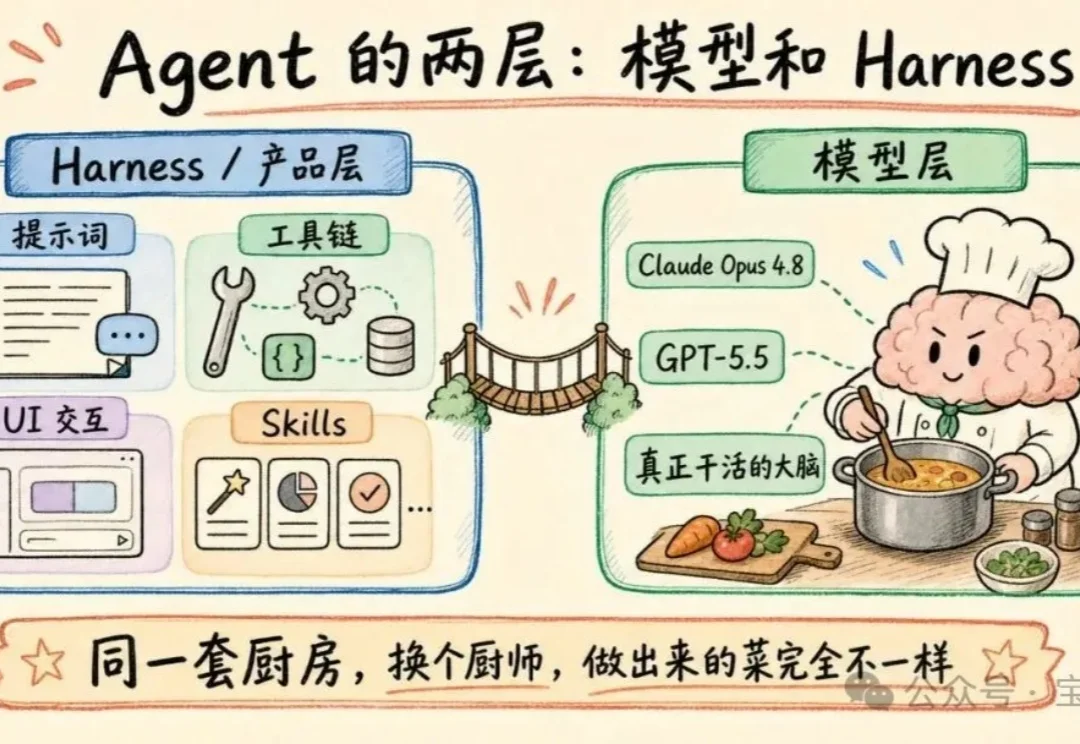
为啥 Codex 还不推出类似 Codex Design 的产品?
为啥 Codex 还不推出类似 Codex Design 的产品?Anthropic 最近推出了 Claude Design,是我除了编程之外用得最多的 Agent,也推荐过很多次。效果真的好:你用一句话描述想要的 App,它直接给你生成一个可交互的原型,点哪哪都有反应,不仔细看还以为在操作真实的 App。
来自主题: AI资讯
6646 点击 2026-06-16 09:54
 搜索
搜索
Anthropic 最近推出了 Claude Design,是我除了编程之外用得最多的 Agent,也推荐过很多次。效果真的好:你用一句话描述想要的 App,它直接给你生成一个可交互的原型,点哪哪都有反应,不仔细看还以为在操作真实的 App。
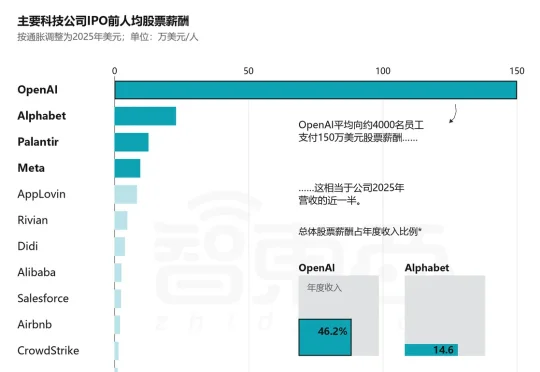
据外媒The Information昨日报道,过去5年间,OpenAI和Anthropic的早期员工及投资者已通过私下股份出售合计套现约140亿美元(约合人民币950亿元)。这一轮员工造富潮正值AI行业IPO竞赛全面升温。6月12日,SpaceX以1.75万亿美元估值登陆纳斯达克,成为这波超级IPO潮中第一个落地的案例。而在此之前,SpaceX至少已连续5年安排员工减持。
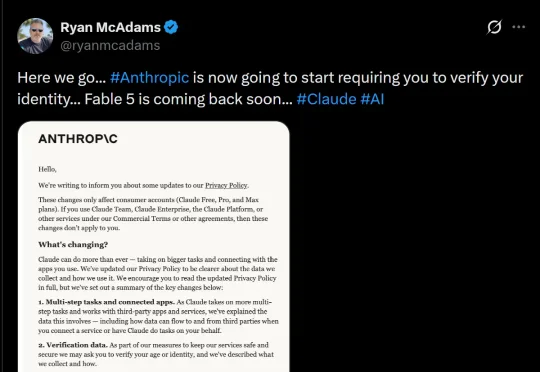
根据邮件内容,从7月8日开始,Claude很可能要向你要身份证了。Anthropic的实名制验证,终于要来了?根据Anthropic官方支持页面,验证将通过第三方服务Persona进行。- 上传政府颁发的、带有照片的身份证件(护照、驾照、身份证等)
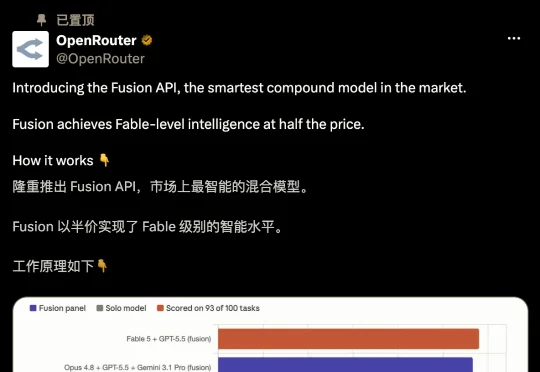
OpenRouter 上线了一个叫 Fusion 的新功能,把同一道题丢给一组模型,再让一个裁判模型把答案揉成一份。结果是,几个便宜的开源模型组起团来,能直接打平 Fable 5,价格只有其一半。
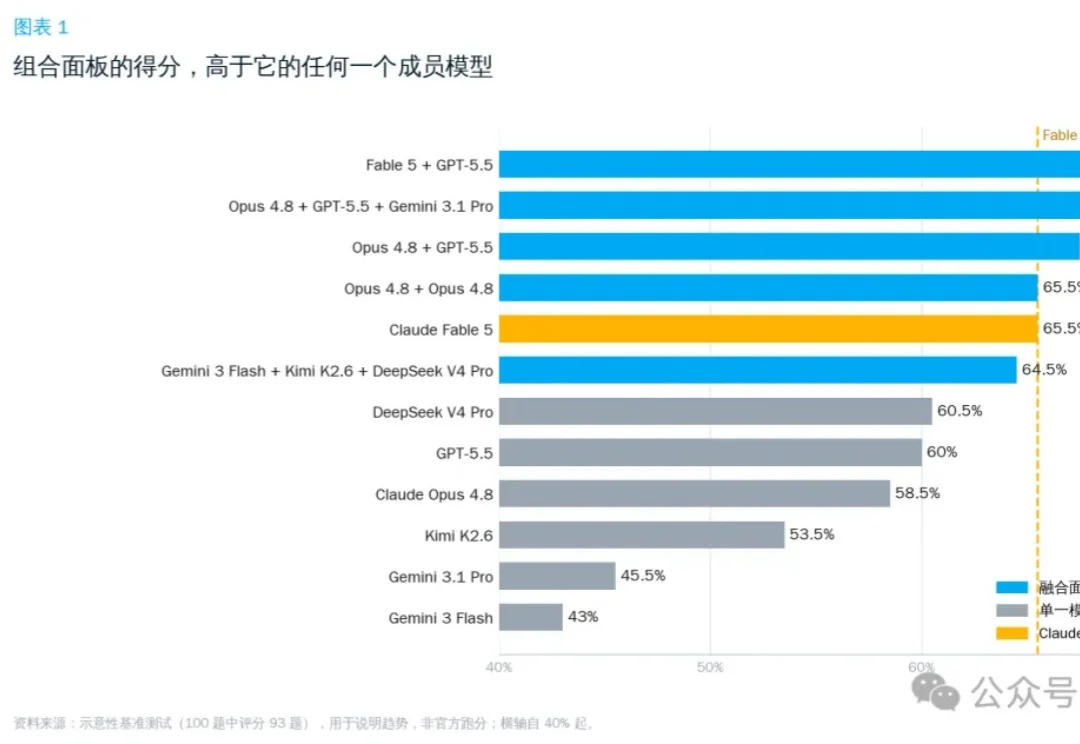
AI网关OrcaRouter最近上线了一套可编程路由策略Routing DSL,多个模型同时答题,自动仲裁出最优解。几个你现在就能调用的“常规模型”,给它来个组合编排,跑出来的综合胜率,直接掀翻了Fable 5的单体基准线。Opus 4.8打不过Fable 5,GPT-5.5也单挑不过,但这两个拼一组,结果就反超了。

Workflow、Skill、SOP,可能真的要过时了。
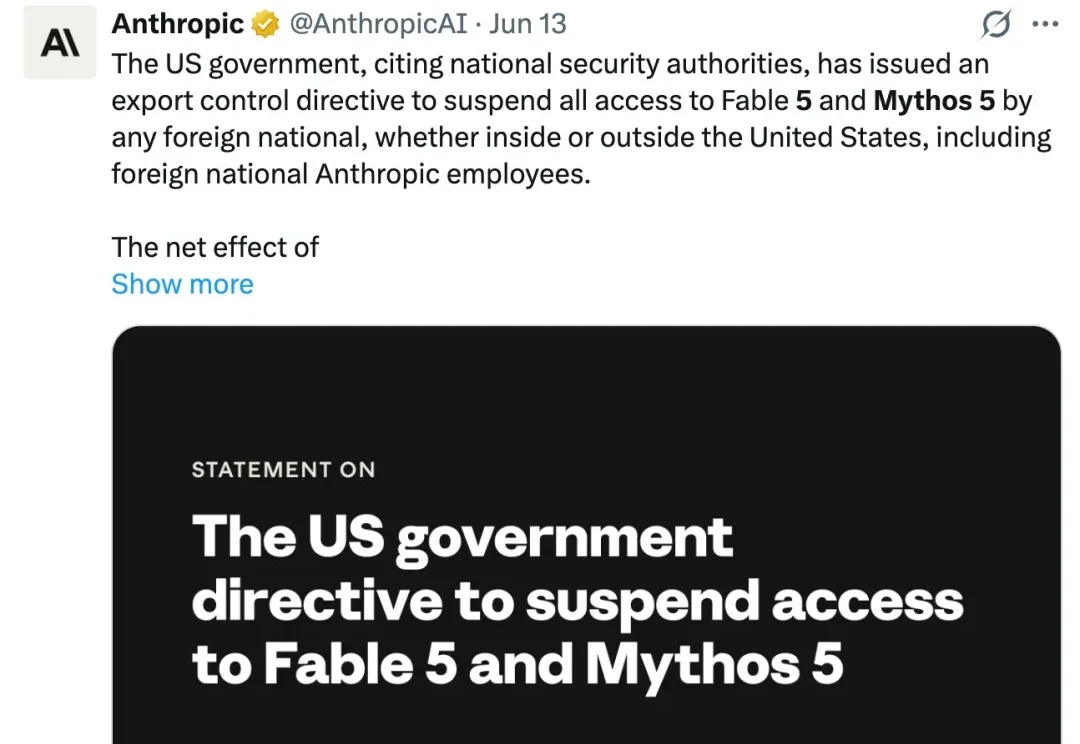
从万众期待的「AI 封神时刻」,到美国政府一纸禁令强制下线 —— 这个名字中有 5 的模型,没活过 5 天。
刚刚,开发者Jamieson O'Reilly用泄露的系统级Prompt,硬核解锁了「轻量版」的Fable 5。仅仅一行代码的注入,就让Opus 4.8当场「开智」。在极限对照实验中,O'Reilly给到同一个指令——制作一个现代苹果风的网页。
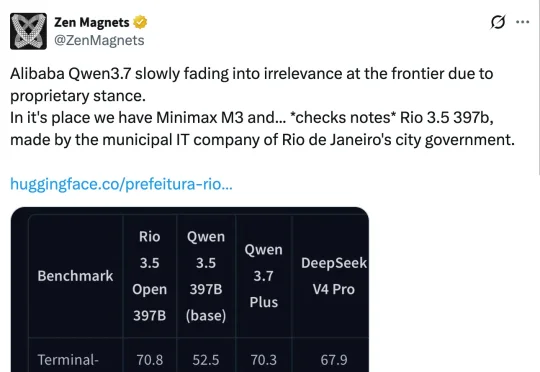
今天,除了全球(非美)被禁的 Claude Fable 5,AI 社区还被一个开源模型刷屏了。有推特博主发现,一个由巴西里约热内卢市政府旗下 IT 公司开源的模型 Rio 3.5 397B,在多项基准测试中超越了 Qwen 3.7 Plus 等开源模型,而这个模型的基础模型还是 Qwen3.5-397B-A17B。
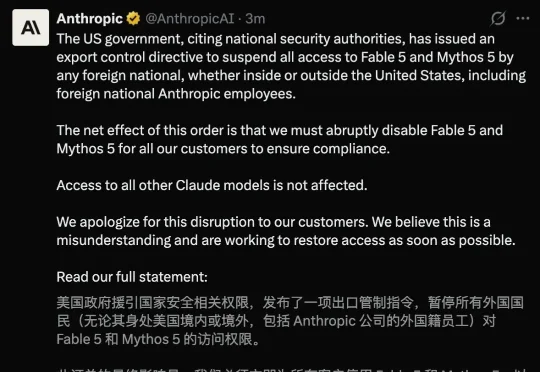
就在刚刚,Anthropic官宣——全球禁用外籍人士对Claude Fable 5和Mythos 5的所有访问权限。无论是在美国境内还是境外,就连Anthropic的外籍员工,全都不可用。上线才3天的Claude Fable 5,一瞬间就没了。