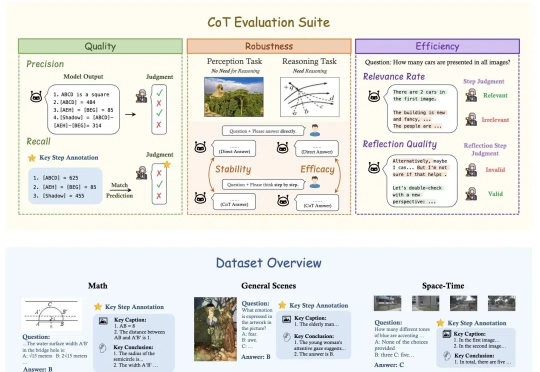
DeepSeek、OpenAI、Kimi视觉推理到底哪家强?港中文MMLab推出推理基准MME-COT
DeepSeek、OpenAI、Kimi视觉推理到底哪家强?港中文MMLab推出推理基准MME-COTOpenAI o1和DeepSeek-R1靠链式思维(Chain-of-Thought, CoT)展示了超强的推理能力,但这一能力能多大程度地帮助视觉推理,又应该如何细粒度地评估视觉推理呢?
来自主题: AI技术研报
10212 点击 2025-02-22 21:27
 搜索
搜索
OpenAI o1和DeepSeek-R1靠链式思维(Chain-of-Thought, CoT)展示了超强的推理能力,但这一能力能多大程度地帮助视觉推理,又应该如何细粒度地评估视觉推理呢?
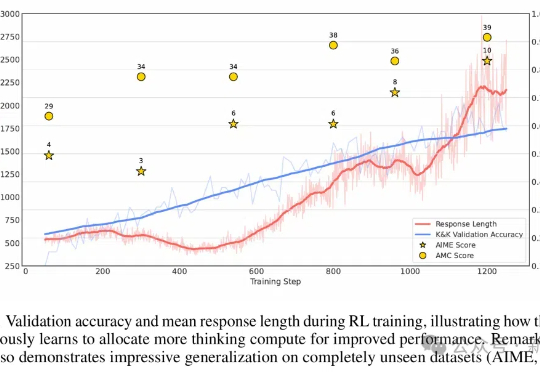
不到10美元,3B模型就能复刻DeepSeek的顿悟时刻了?来自荷兰的开发者采用轻量级的RL算法Reinforce-Lite,把复刻成本降到了史上最低!同时,微软亚研院的一项工作,也受DeepSeek-R1启发,让7B模型涌现出了高级推理技能。
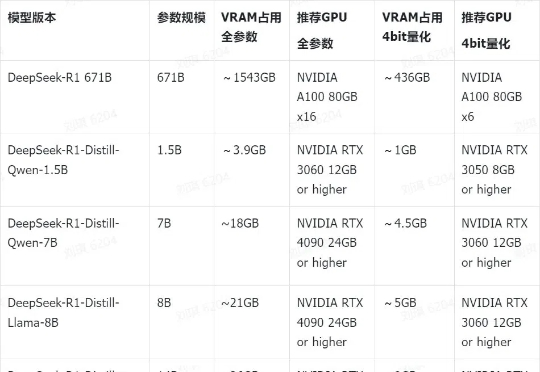
DeepSeek-R1及其蒸馏版本模型突破了AI Reasoning和大规模AI性能的新基准,其中DeepSeek-R1-Zero和DeepSeek-R1,已经在推理和问题求解上树立了新的标准。本次研究聚焦于如何利用已有的机器进行模型部署,使用这些先进的模型进行开发和研究。
美国AI云服务商Together AI宣布完成3.05亿美元B轮融资,估值高达33亿美元!该公司押注开源模型,提供包括DeepSeek-R1在内的200多个模型API服务,并出租GPU算力,年收入已超1亿美元。
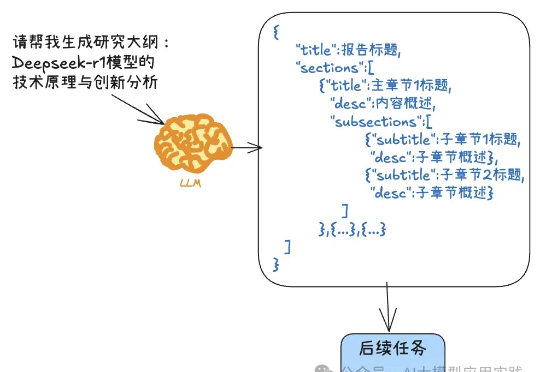
DeepSeek-R1这样的推理模型有着强大的深度思考能力,但也有着一些不同于通用模型的特点与用法,比如不支持函数调用,不支持结构化输出,o1甚至不支持系统提示(System Prompt)等。尽管这和它们的使用场景有关,但有时也会带来不便。今天我们就来说说结构化输出这个常见的问题。
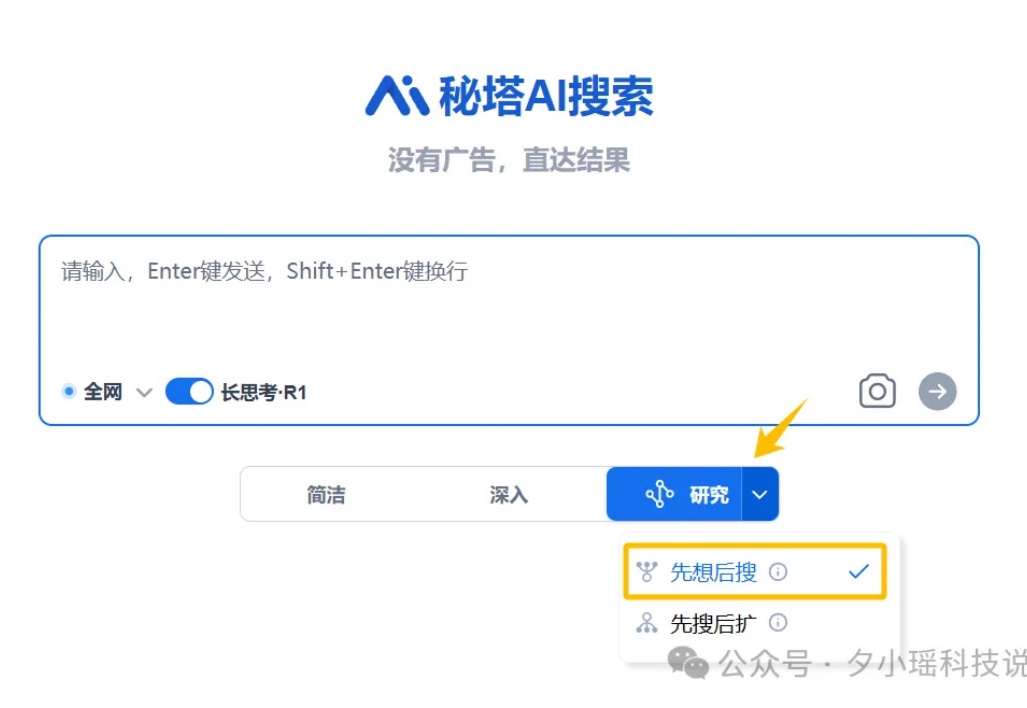
近两个月,AI圈像开了倍速一样,可以说是卷疯了......
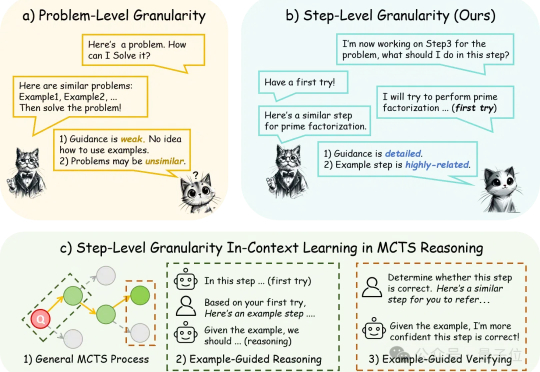
仅需简单提示,满血版DeepSeek-R1美国数学邀请赛AIME分数再提高。
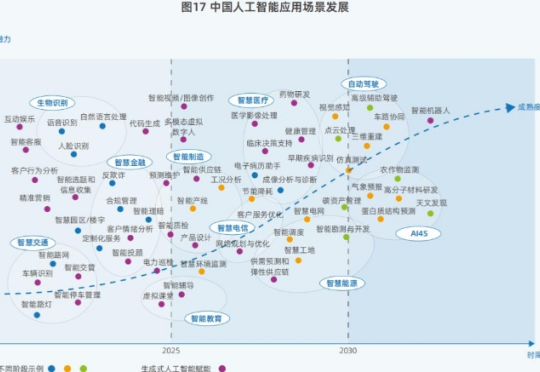
这个AI领域千亿级市场,将辐射千家万户。 DeepSeek-R1横空出世,打响了大模型比拼性价比的第一枪。 Meta、OpenAI等国外头部大模型厂商纷纷复刻或变相降价。比DeepSeek-R1晚两周发布的OpenAI o3-mini模型,定价比前代模型o1-mini降低了超6成,比前代完整版的o1模型便宜超9成。

应用内接入 DeepSeek-R1 已经成了一种潮流。
接入DeepSeek,不等于All in DeepSeek