
Transformer作者:DeepSeek才有搞头,OpenAI指望不上了
Transformer作者:DeepSeek才有搞头,OpenAI指望不上了“闭源人工智能在阻碍我们探索真正的科学。”
来自主题: AI资讯
10184 点击 2025-09-10 12:30
 搜索
搜索
“闭源人工智能在阻碍我们探索真正的科学。”
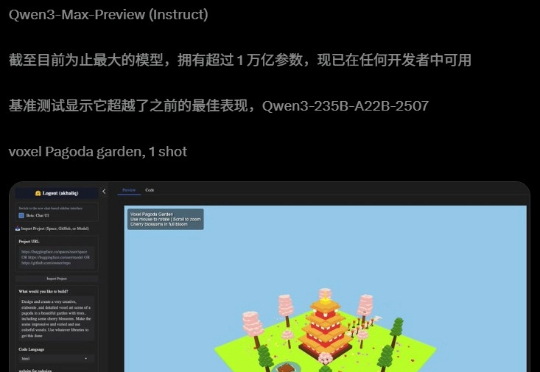
阿里迄今为止,参数最大的模型诞生了!昨夜,Qwen3-Max-Preview(Instruct)官宣上线,超1万亿参数性能爆表。在全球主流权威基准测试中,Qwen3-Max-Preview狂揽非推理模型「C」位,直接碾压Claude-Opus 4(Non-Thinking)、Kimi-K2、DeepSeek-V3.1。
为了“骗”过模型,有人每天陪AI聊天,摸透模型的脾气和规则;有人在图片里用透明字体写上诱导语,扰乱模型答案排序。

DeepSeek下一步,被曝剑指智能体。 知情人士透露,DeepSeek正在开发具有更强大AI Agent能力的新模型,预计在今年年底就会推出。

存款60美元、欠债1.5万美元,82岁的Luis正在积极学习提示词策略,创办科技公司,他想用AI为自己的人生来一场漂亮的收官;年近80的Scalettar,教会了96岁丈夫使用AI编辑。AI为许多美国老年人打开了一个新世界,他们比许多年轻人更接受,也更会用AI。

您对“思维链”(Chain-of-Thought)肯定不陌生,从最早的GPT-o1到后来震惊世界的Deepseek-R1,它通过让模型输出详细的思考步骤,确实解决了许多复杂的推理问题。但您肯定也为它那冗长的输出、高昂的API费用和感人的延迟头疼过,这些在产品落地时都是实实在在的阻碍。

DeepSeek再次出招,直接对标OpenAI!据彭博社最新独家爆料,DeepSeek正开发AI智能体:打造无需复杂指令、可自主学习与执行的下一代AI系统,年底重磅发布!

用过才知道,「快」不是万能药。
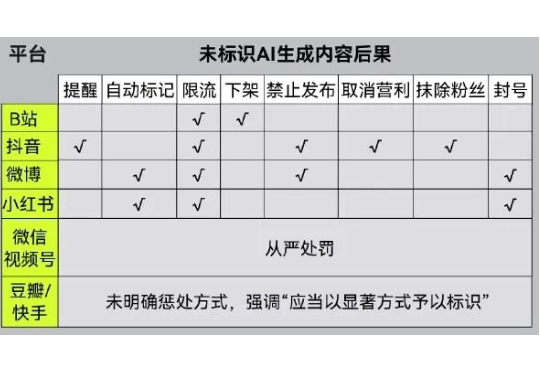
被AI糟蹋的互联网,靠AI标识重回清净? 过去几年,AI生成内容大量涌入我们的生活,但AI往往“隐身”幕后,这种“看不见的存在”自9月1日起就要被终结了。
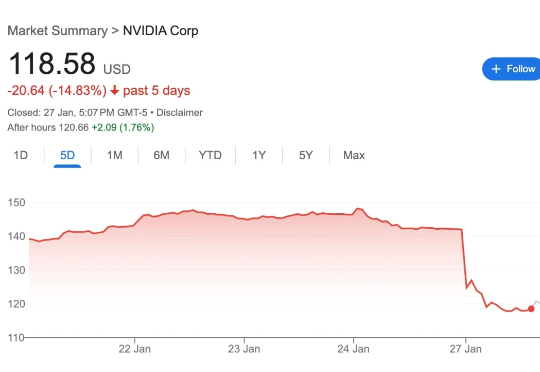
随着DeepSeek R1、Kimi K2和DeepSeek V3.1混合专家(MoE)模型的相继发布,它们已成为智能前沿领域大语言模型(LLM)的领先架构。由于其庞大的规模(1万亿参数及以上)和稀疏计算模式(每个token仅激活部分参数而非整个模型),MoE式LLM对推理工作负载提出了重大挑战,显著改变了底层的推理经济学。