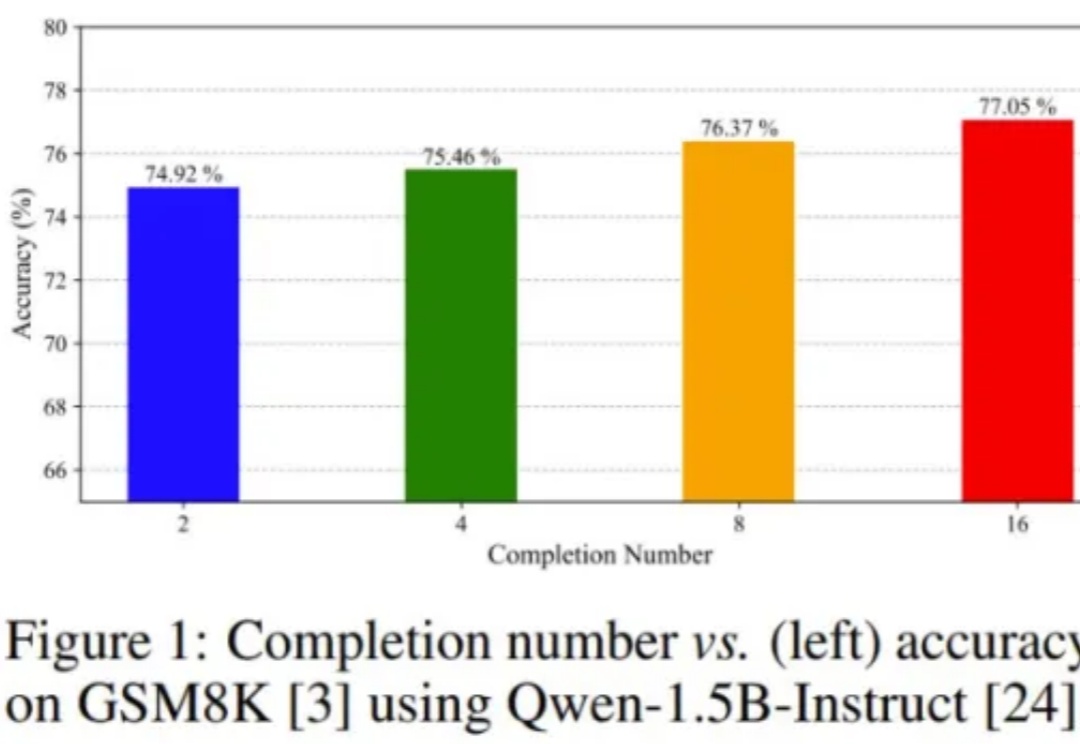
在GSM8K上比GRPO快8倍!厦大提出CPPO,让强化学习快如闪电
在GSM8K上比GRPO快8倍!厦大提出CPPO,让强化学习快如闪电DeepSeek-R1 的成功离不开一种强化学习算法:GRPO(组相对策略优化)。
来自主题: AI技术研报
7889 点击 2025-04-01 16:16
 搜索
搜索
DeepSeek-R1 的成功离不开一种强化学习算法:GRPO(组相对策略优化)。
刚刚,百度文小言全面升级了。

一夜之间,OpenAI更新三大动向,开源、融资、用户暴增。第一,将开源一个具备推理能力的大语言模型,包含参数权重那种。上一次这样开源还是6年前推出GPT-2。

DeepSeek的出圈,不仅引爆了全社会对于AI的大讨论,更重要的是激发各界人士从观望者转变为参与者,掀起了一波真实的人工智能落地潮。在孕育了AI的互联网生态中,AI引起的变化会首当其冲,且影响更彻底。广告作为互联网生态最主要的商业模式,更是当前AI技术应用的主战场。

DeepSeek要开放融资了?
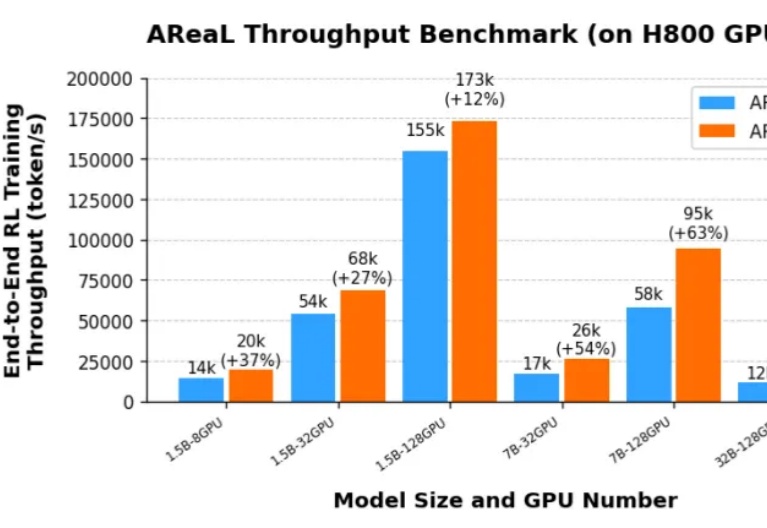
由于 DeepSeek R1 和 OpenAI o1 等推理模型(LRM,Large Reasoning Model)带来了新的 post-training scaling law,强化学习(RL,Reinforcement Learning)成为了大语言模型能力提升的新引擎。然而,针对大语言模型的大规模强化学习训练门槛一直很高:
最近超火的氛围编程(Vibe coding)你听说了吗?

正值“金三银四”,应届毕业生又进入到求职冲刺阶段,如果能够顺利杀出重围,便可以逃离毕业季的又一场肉搏。而因为ChatGPT、DeepSeek、豆包等AI产品的集体爆发,“AI潮”成为今年春招绕不开的主题。据《2025年春招市场行业周报(第一期)》数据显示,春招首周,人工智能行业求职人数同比增速达33.4%,位居行业第一;人工智能工程师的求职增速达69.6%,位居职业榜首。

随着Deepseek持续火热,部分医生和患者纷纷在线种草。但在近日,「AI 误诊,上海患者获赔127万」的消息在各大社交平台迅速传播、引起争议。

3D生成版DeepSeek再上新高度!