
GPT-4没通过图灵测试!60年前老AI击败了ChatGPT,但人类胜率也仅有63%
GPT-4没通过图灵测试!60年前老AI击败了ChatGPT,但人类胜率也仅有63%GPT-4无法通过图灵测试!UCSD团队研究证明60年前AI在测试中打败了ChatGPT,更有趣的是人类在测试中的胜率仅有63%。
来自主题: AI技术研报
6269 点击 2023-12-03 14:49
GPT-4无法通过图灵测试!UCSD团队研究证明60年前AI在测试中打败了ChatGPT,更有趣的是人类在测试中的胜率仅有63%。
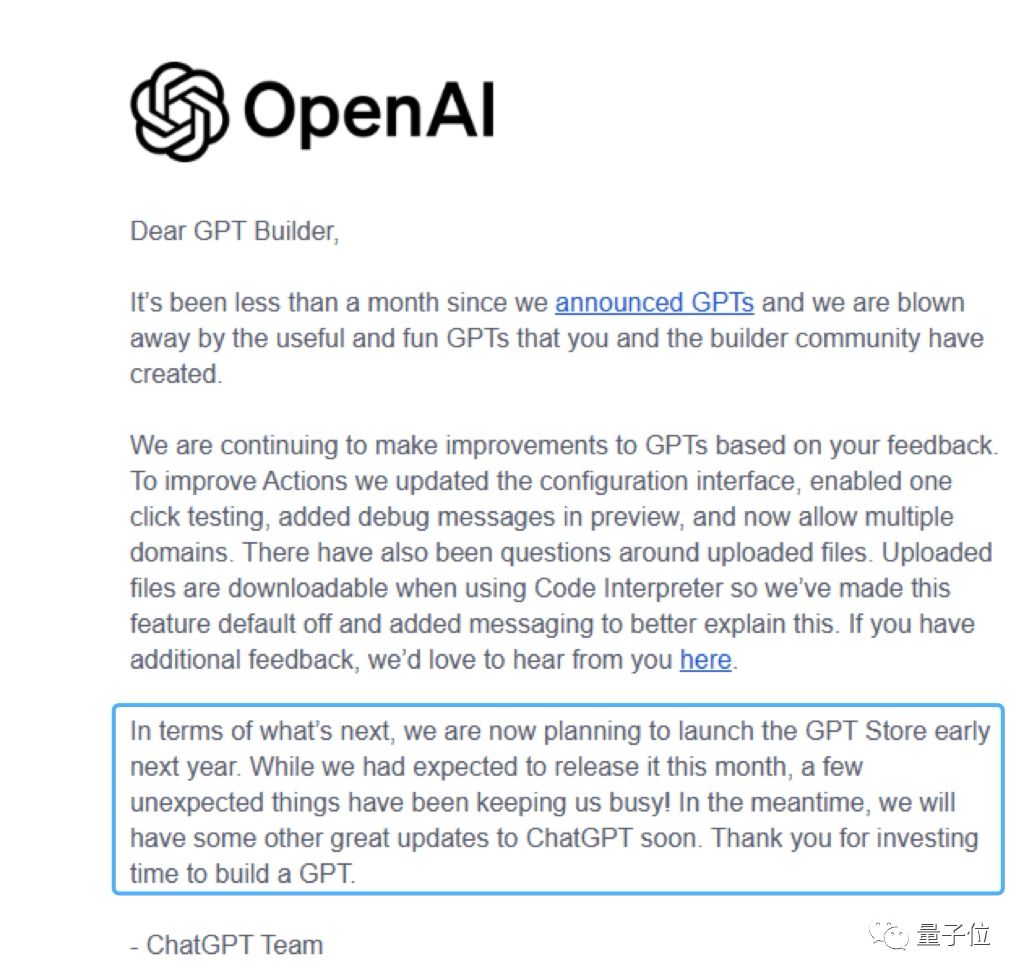
OpenAI刚刚向开发者宣布,那个要给大家分收益的商店,今年它上不了线了!GPTs商店要推迟到明年年初,才能与大家见面。而且这个决定是被 迫 的——所有的一切都与犹在眼前的OpenAI内讧事件息息相关。

PyTorch团队让大模型推理速度加快了10倍。且只用了不到1000行的纯原生PyTorch代码!

今天,外媒纽约客曝出长文揭秘OpenAI动乱始末,女董事Helen Toner内鬼身份基本坐实,微软开启ABC三重plan,最终顺利摘桃成最大赢家。

「硅基研究室」观察发现,小红书正在内测其AI对话助手「DAVINCI 达芬奇」,不少用户在今年9月就已收到小红书官方账号「测试薯」的内测邀请,通过提交问卷,有机会进行体验。

不知不觉,ChatGPT发布一周年了,从发布之初的万人惊叹,到引发几乎所有科技公司入局AI,再到内部宫斗全世界吃瓜,没有人能够否认,过去一年,是ChatGPT引发了全世界从产业到普通人的AI热情,同样,也引发了对于AI的担忧,而这种担忧,纷纷指向了AI的安全性。

让大模型洗钱、制造炸弹、合成冰毒?GPT-4、 Claude 2纷纷沦陷了。让大模型成功越狱,还是有机可乘。

Anthropic的模型可解释性团队,从大模型中看到了它的「灵魂」——一个可解释的更高级的模型。
从人工智能的发展历程来看,GPT 系列模型(例如 ChatGPT 和 GPT-4)的问世无疑是一个重要的里程碑。由它所驱动的人工智能应用已经展现出高度的通用性和可用性,并且能够覆盖多个场景和行业 —— 这在人工智能的历史上前所未有。

目前最好的大型多模态模型 GPT-4V 与大学生谁更强?我们还不知道,但近日一个新的基准数据集 MMMU 以及基于其的基准测试或许能给我们提供一点线索,