

首个统一多模态模型评测标准,DeepSeek Janus理解能力领跑开源,但和闭源还有差距
首个统一多模态模型评测标准,DeepSeek Janus理解能力领跑开源,但和闭源还有差距统一多模态大模型(U-MLLMs)逐渐成为研究热点,近期GPT-4o,Gemini-2.0-flash都展现出了非凡的理解和生成能力,而且还能实现跨模态输入输出,比如图像+文本输入,生成图像或文本。
来自主题: AI技术研报
8860 点击 2025-04-10 10:20
统一多模态大模型(U-MLLMs)逐渐成为研究热点,近期GPT-4o,Gemini-2.0-flash都展现出了非凡的理解和生成能力,而且还能实现跨模态输入输出,比如图像+文本输入,生成图像或文本。

GPT-4o图像生成架构被“破解”了!
这届网友真是把 AI 玩出花!

今年早些时候, 尿布电商品牌 Coterie 的员工注意到顾客来自一个有趣的新来源——ChatGPT。
当前搜索AI市场面临着一个显著的断层:Perplexity的Sonar Reasoning Pro和OpenAI的GPT-4o Search Preview等专有解决方案与开源替代品之间存在巨大差距。这些封闭式系统虽然表现优异,但却限制了透明度、创新和创业自由。作为一名正在开发Agent产品的工程师,你是否曾经渴望拥有一个功能强大且完全开放的搜索框架?
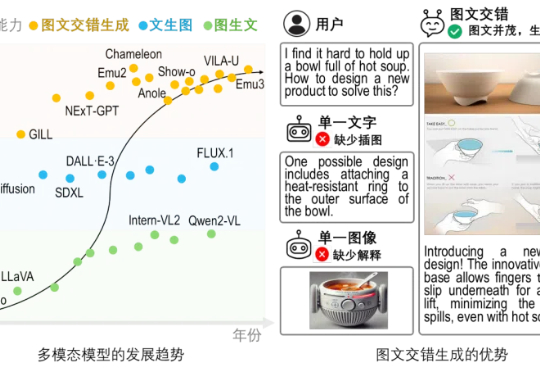
文生图 or 图生文?不必纠结了!
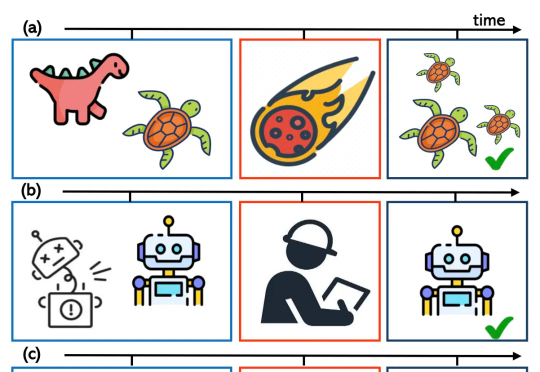
大型语言模型 (LLM) 在软体机器人设计领域展现出了令人振奋的应用潜力。

刚刚,奥特曼接连抛出重磅消息:GPT-5不仅将免费开放,还将整合多项尖端技术。o3和o4-mini即将在几周内亮相,还有一个神秘的开源推理模型要来。然而,另一边Meta的Llama 4却因性能瓶颈屡次延期,AI竞赛的格局愈发扑朔迷离。

4 月 3 日消息,当地时间周三,Anthropic 发布了“Claude for Education”计划,宣布正式进军高等教育市场,以应对 OpenAI 的 ChatGPT Edu 方案。该计划将为高校师生和工作人员提供 Claude AI 聊天机器人,并额外配备一系列专门功能。

「下一代默认 AI 大模型工具」的竞争开始了。