
OpenAI参与,重卷ImageNet:终于把FID做成训练
OpenAI参与,重卷ImageNet:终于把FID做成训练来自USC、CMU、CUHK和OpenAI的全华阵容研究团队,提出了一种叫FD-loss的方法,把“算统计的样本池”和“算梯度的batch”彻底解耦。依靠数万张图像组成的大容量缓存队列或指数移动平均机制,稳定完成分布估算,仅针对当下小批量数据开展梯度回传。
来自主题: AI技术研报
7697 点击 2026-05-03 22:46
 搜索
搜索
来自USC、CMU、CUHK和OpenAI的全华阵容研究团队,提出了一种叫FD-loss的方法,把“算统计的样本池”和“算梯度的batch”彻底解耦。依靠数万张图像组成的大容量缓存队列或指数移动平均机制,稳定完成分布估算,仅针对当下小批量数据开展梯度回传。
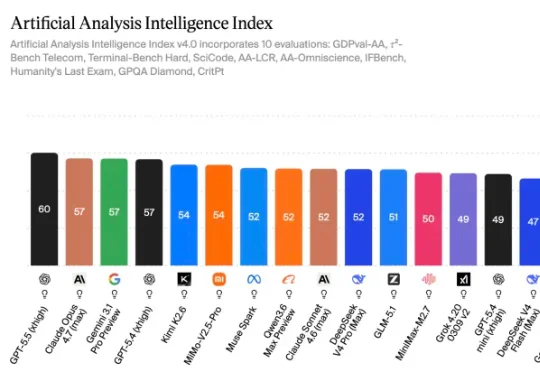
上周太集中发的后果就是光在用GPT -5.5了,小米的Mimo-V2.5-Pro,DeepSeek V4 Pro还没有放在Agent的场景上测。所以我跟钱包一拍即合,复制了4个一模一样的Hermes Agent,记忆一样,skill一样,系统设置一样,能调用的工具也一样。

当AI生图真的开始被普通人使用,它会先被用在哪里?所以这次我没有继续测模型或者写Prompt分享。而是去找了10个身边的普通人,问他们怎么开始用AI生图,又为什么会在这些具体的小事上用到它。

从去年开始做这个账号以来,我其实写过不少测模型的文章。我相信也有很多朋友是因为看了我测评的文章关注我的。但从过年之后,真的就很少写模型评测的文章了。主要是我写文章的速度甚至一度跟不上模型发布的速度了。

GPT Image 2的发布给整个AI圈带来了亿点点震撼。但很多人可能没注意到,幕后最会玩梗的居然是他——主力训练者陈博远。他和奥特曼同台主持,悄悄修好了中文渲染;给模型起代号“布基胶带”,还拿香蕉艺术品玩梗;为了秀模型的文字能力,设计了米粒刻字、漫画套娃、视觉证明题这些“彩蛋级”测试。

来自华为泰勒实验室、北京大学和上海财经大学的研究团队提出了 SHAPE(Stage-aware Hierarchical Advantage via Potential Estimation),给推理链装上了一套「里程碑 + 推理税」机制——不仅告诉模型每一步推得对不对,还让它为啰嗦付出代价。结果是:准确率平均提升 3%,token 消耗直降 30%。

SenseNova U1 是商汤最新发布的一个开源的多模态模型,它的 Lite 系列 8B 和 A3B 参数版本,目前已经在 Hugging Face 和 GitHub 上开源。APPSO 也提前拿到了测试资格,我们发现商汤这款新一代原生理解生成统一模型,就开源模型来说,已经做到了最好水平。

腾讯ima最新上线了copilot模式,你可以“领养”一只小熊猫,自由设定人设、性格、说话风格。让它记住你的习惯、你的资料、你做过的事,调教出一个会说话、会干活的专属知识伙伴。
商汤刚刚开源了一个全新架构的理解生成统一模型SenseNova-U1,虽然小尺寸版本只有8B,却能复刻不少GPT-Image-2的拿手绝活。太阳系图解,八大行星各自的轨道、属性、图文介绍一应俱全,看着挺像那么回事。

在消耗了无数张 GPU 资源、烧掉了够几座城市用一年的电力之后,OpenAI 最新推出的 AI 生图大模型 GPT-Image-2,再次迎来了它人生中的高光时刻——给人类看手相/面相。