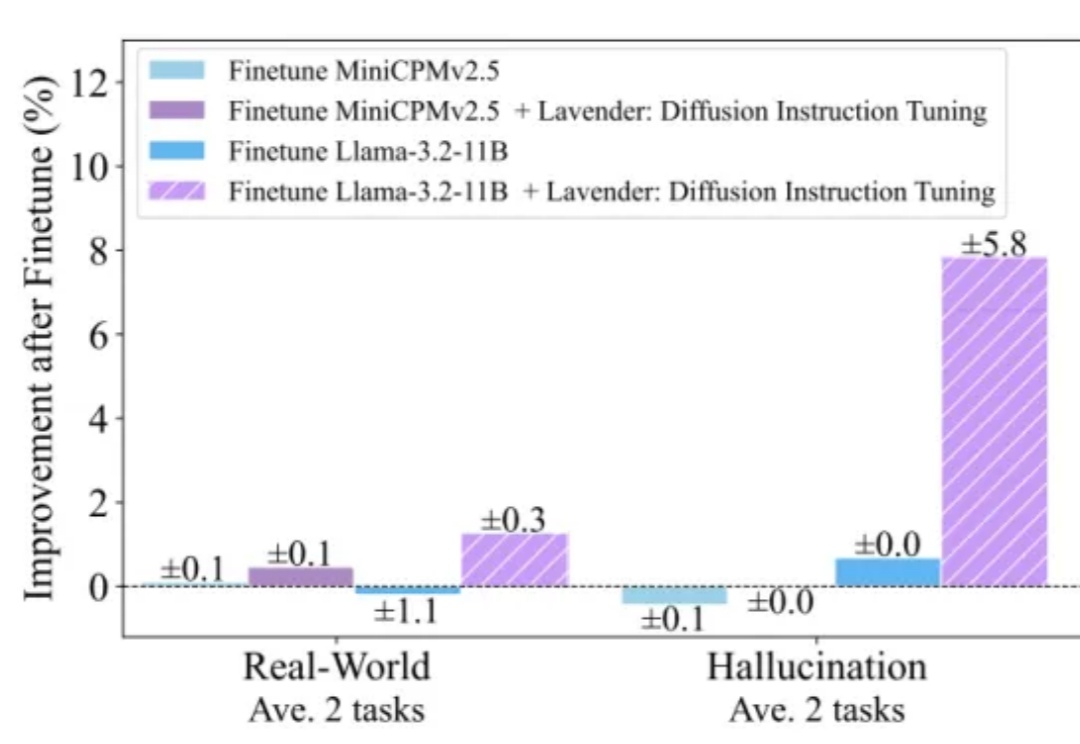
Llama模仿Diffusion多模态涨分30%!不卷数据不烧卡,只需共享注意力分布
Llama模仿Diffusion多模态涨分30%!不卷数据不烧卡,只需共享注意力分布这次不是卷参数、卷算力,而是卷“跨界学习”——
来自主题: AI技术研报
9037 点击 2025-02-17 14:43
 搜索
搜索
这次不是卷参数、卷算力,而是卷“跨界学习”——
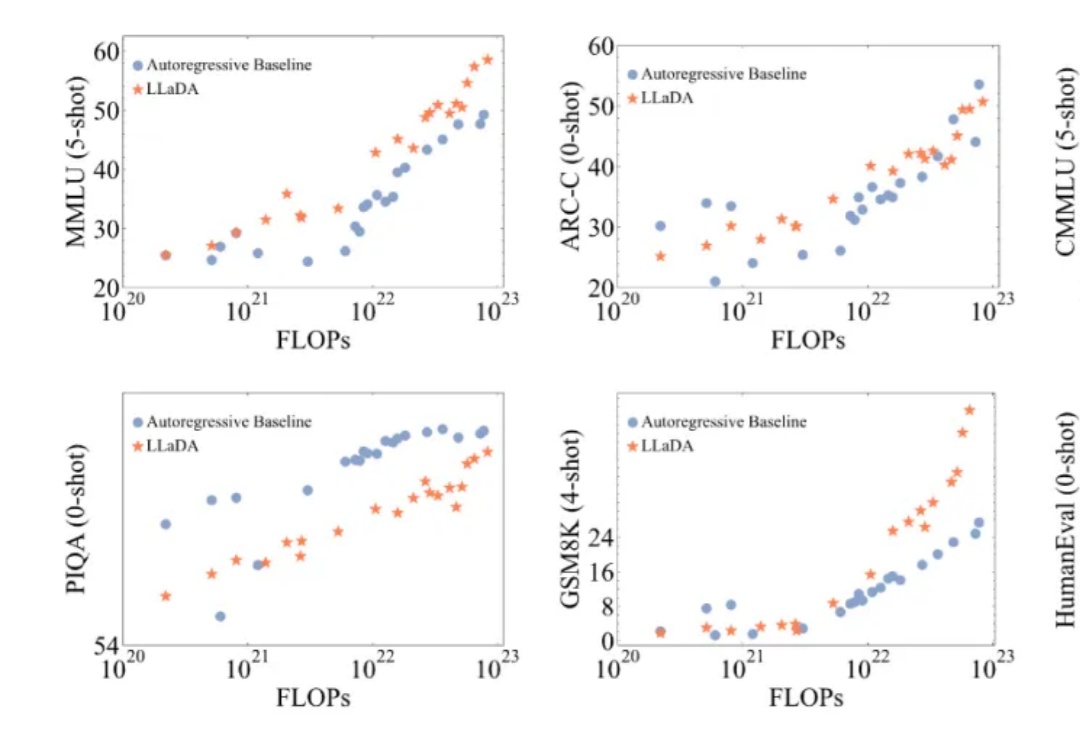
近年来,大语言模型(LLMs)取得了突破性进展,展现了诸如上下文学习、指令遵循、推理和多轮对话等能力。目前,普遍的观点认为其成功依赖于自回归模型的「next token prediction」范式。

一张图、一句提示词,万物都能乱入你随手拍的视频。
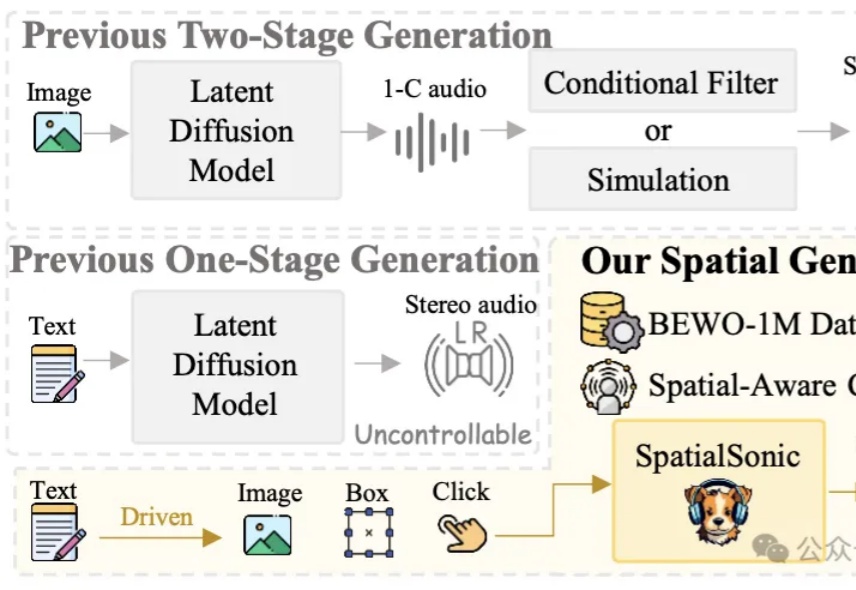
兔子通过两只耳朵可以准确感知捕食者的一举一动,造就了不同品种广泛分布在世界各地的生命奇迹;同样人也需要通过双耳沉浸式享受电影视听盛宴、判断驾驶环境和感知周围活动状态。
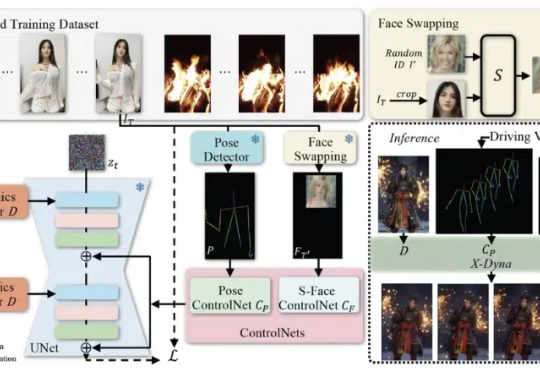
在当下的技术领域中,人像视频生成(Human-Video-Animation)作为一个备受瞩目的研究方向,正不断取得新的进展。人像视频生成 (Human-Video-Animation) 是指从某人物的视频中获取肢体动作和面部表情序列,来驱动其他人物个体的参考图像来生成视频。

新型验证码IllusionCAPTCHA,利用视觉错觉和诱导性提示,使AI难以识别,而人类用户能轻松通过。实验表明,该验证码能有效防御大模型攻击,同时提升用户体验,为验证码技术提供了新思路。

DeepSeek的爆火来得很突然。1月27日一早,DeepSeek在中国区和美国区苹果App Store免费榜上同时冲到了下载量第一,超过原先霸榜的ChatGPT。而半个月前,DeepSeek的App才刚刚上线iOS和安卓的应用市场。
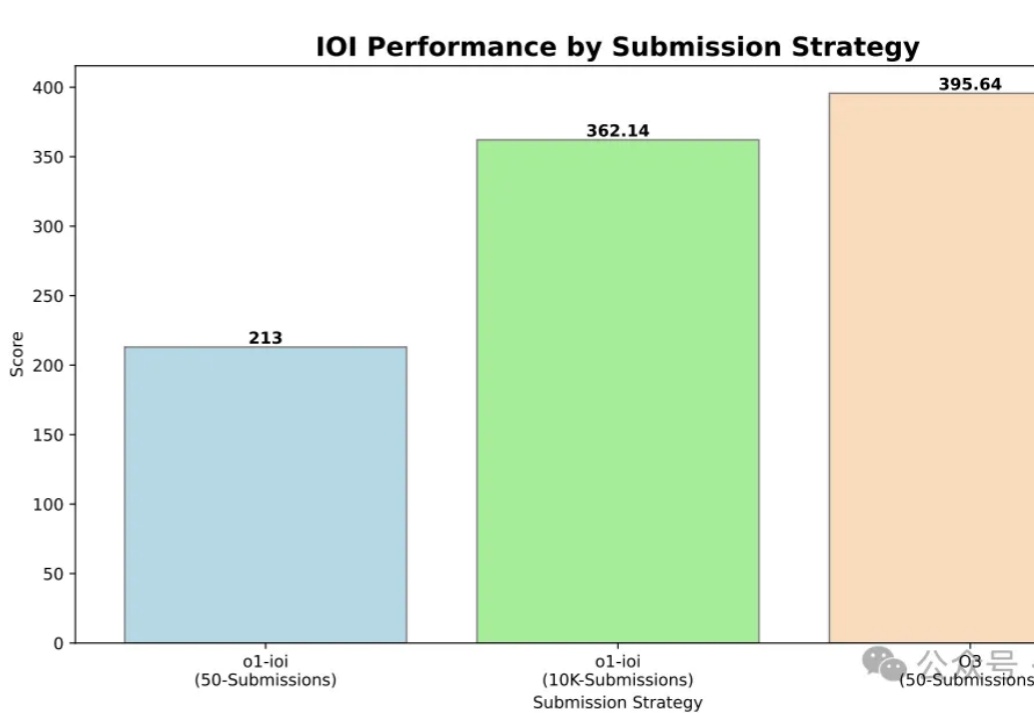
IOI 2024金牌,OpenAI o3轻松高分拿下!

先是三星宣布智谱的Agentic GLM成为其新手机Galaxy S25的AI能力来源,紧接着The Information爆料,在经历了近一年的模型测试与合作伙伴探索后,苹果终于敲定了中国市场的合作伙伴:阿里巴巴。这意味着,中国iPhone用户很可能在今年迎来一个由国产大模型驱动的iPhone。

DreamTech,由牛津大学、南京大学等顶尖高校研究者组成的AI创业团队,在春节期间公布了他们在3D生成方向上的新工作成果——Neural4D 2.0(初版名为Direct3D),提出了创新性的3D Assembly Generation算法思路及更高效的模型架构