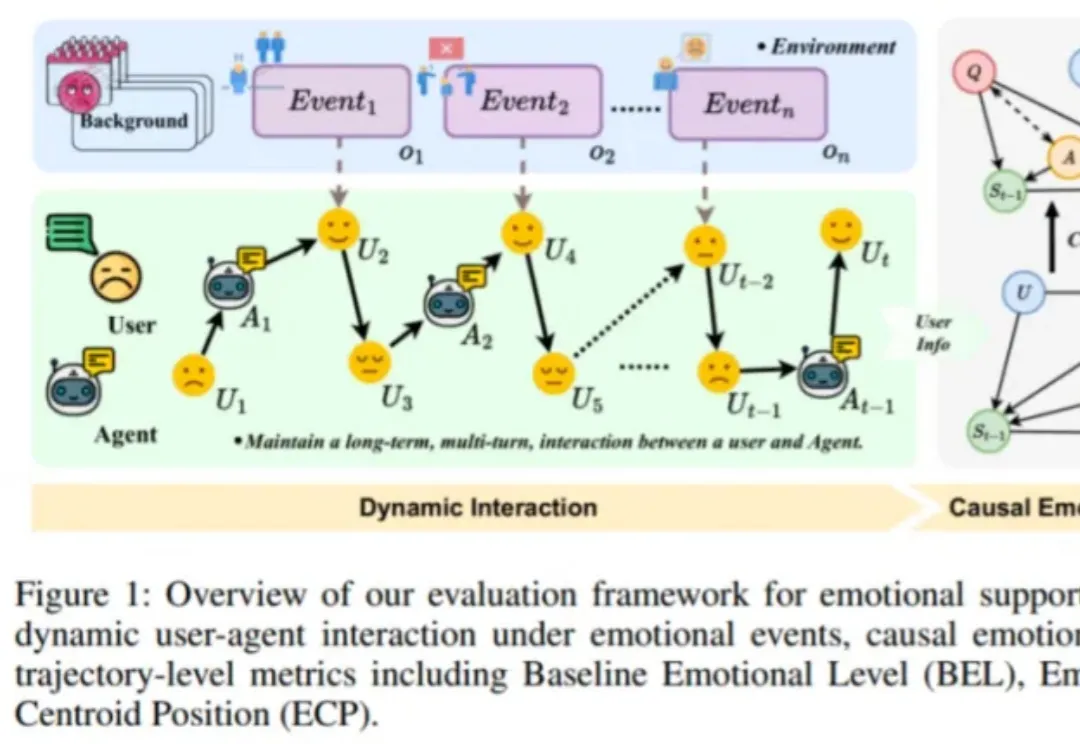
DeepSeek、Gemini谁更能提供情感支持?趣丸×北大来了波情绪轨迹动态评估
DeepSeek、Gemini谁更能提供情感支持?趣丸×北大来了波情绪轨迹动态评估近日,由趣丸科技与北京大学软件工程国家工程研究中心共同发表的《Detecting Emotional Dynamic Trajectories: An Evaluation Framework for Emotional Support in Language Models(检测情感动态轨迹:大语言模型情感支持的评估框架)》论文,获 AAAI 2026 录用。
来自主题: AI技术研报
9708 点击 2025-12-08 14:13